 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent
Apr 23, 2024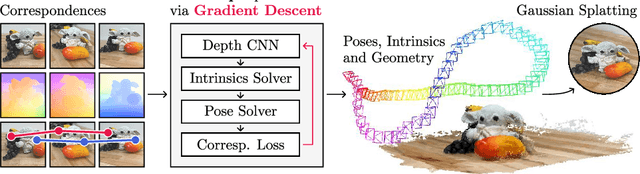


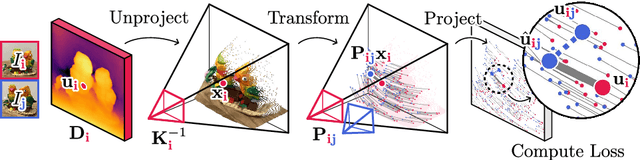
This paper introduces FlowMap, an end-to-end differentiable method that solves for precise camera poses, camera intrinsics, and per-frame dense depth of a video sequence. Our method performs per-video gradient-descent minimization of a simple least-squares objective that compares the optical flow induced by depth, intrinsics, and poses against correspondences obtained via off-the-shelf optical flow and point tracking. Alongside the use of point tracks to encourage long-term geometric consistency, we introduce differentiable re-parameterizations of depth, intrinsics, and pose that are amenable to first-order optimization. We empirically show that camera parameters and dense depth recovered by our method enable photo-realistic novel view synthesis on 360-degree trajectories using Gaussian Splatting. Our method not only far outperforms prior gradient-descent based bundle adjustment methods, but surprisingly performs on par with COLMAP, the state-of-the-art SfM method, on the downstream task of 360-degree novel view synthesis (even though our method is purely gradient-descent based, fully differentiable, and presents a complete departure from conventional SfM).
pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction
Dec 21, 2023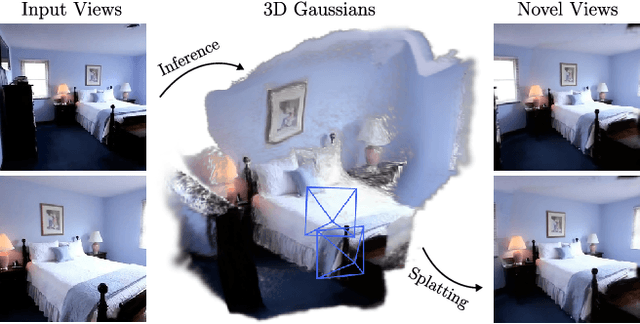

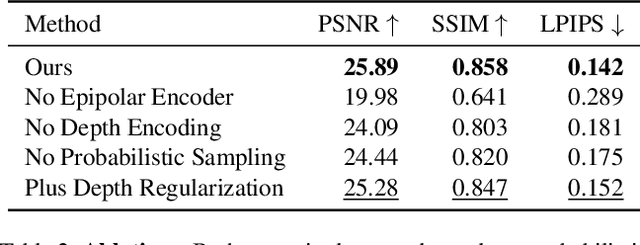
We introduce pixelSplat, a feed-forward model that learns to reconstruct 3D radiance fields parameterized by 3D Gaussian primitives from pairs of images. Our model features real-time and memory-efficient rendering for scalable training as well as fast 3D reconstruction at inference time. To overcome local minima inherent to sparse and locally supported representations, we predict a dense probability distribution over 3D and sample Gaussian means from that probability distribution. We make this sampling operation differentiable via a reparameterization trick, allowing us to back-propagate gradients through the Gaussian splatting representation. We benchmark our method on wide-baseline novel view synthesis on the real-world RealEstate10k and ACID datasets, where we outperform state-of-the-art light field transformers and accelerate rendering by 2.5 orders of magnitude while reconstructing an interpretable and editable 3D radiance field.
Benchmarking Pedestrian Odometry: The Brown Pedestrian Odometry Dataset (BPOD)
Dec 24, 2021
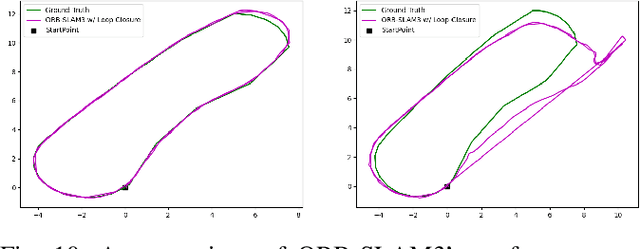
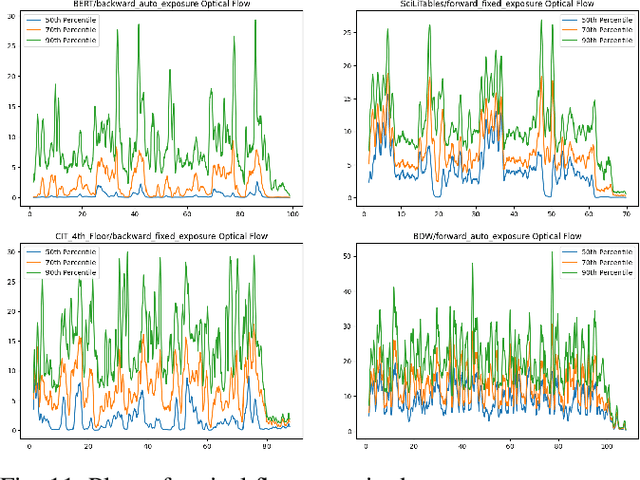

We present the Brown Pedestrian Odometry Dataset (BPOD) for benchmarking visual odometry algorithms in head-mounted pedestrian settings. This dataset was captured using synchronized global and rolling shutter stereo cameras in 12 diverse indoor and outdoor locations on Brown University's campus. Compared to existing datasets, BPOD contains more image blur and self-rotation, which are common in pedestrian odometry but rare elsewhere. Ground-truth trajectories are generated from stick-on markers placed along the pedestrian's path, and the pedestrian's position is documented using a third-person video. We evaluate the performance of representative direct, feature-based, and learning-based VO methods on BPOD. Our results show that significant development is needed to successfully capture pedestrian trajectories. The link to the dataset is here: \url{https://doi.org/10.26300/c1n7-7p93
ShapeMOD: Macro Operation Discovery for 3D Shape Programs
Apr 13, 2021

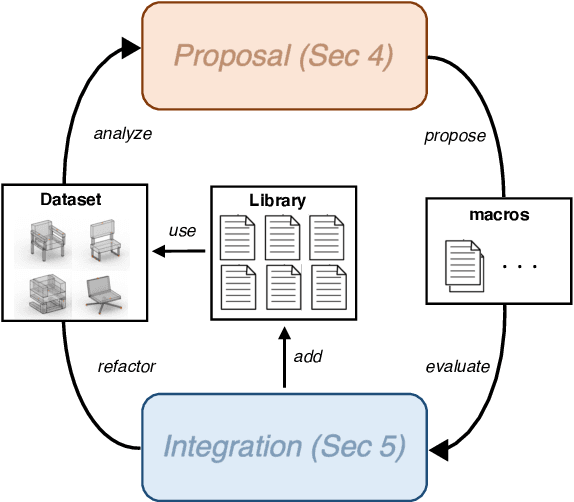
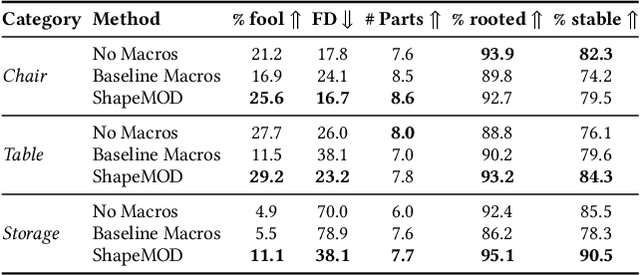
A popular way to create detailed yet easily controllable 3D shapes is via procedural modeling, i.e. generating geometry using programs. Such programs consist of a series of instructions along with their associated parameter values. To fully realize the benefits of this representation, a shape program should be compact and only expose degrees of freedom that allow for meaningful manipulation of output geometry. One way to achieve this goal is to design higher-level macro operators that, when executed, expand into a series of commands from the base shape modeling language. However, manually authoring such macros, much like shape programs themselves, is difficult and largely restricted to domain experts. In this paper, we present ShapeMOD, an algorithm for automatically discovering macros that are useful across large datasets of 3D shape programs. ShapeMOD operates on shape programs expressed in an imperative, statement-based language. It is designed to discover macros that make programs more compact by minimizing the number of function calls and free parameters required to represent an input shape collection. We run ShapeMOD on multiple collections of programs expressed in a domain-specific language for 3D shape structures. We show that it automatically discovers a concise set of macros that abstract out common structural and parametric patterns that generalize over large shape collections. We also demonstrate that the macros found by ShapeMOD improve performance on downstream tasks including shape generative modeling and inferring programs from point clouds. Finally, we conduct a user study that indicates that ShapeMOD's discovered macros make interactive shape editing more efficient.