 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiducial Exoskeletons: Image-Centric Robot State Estimation
Jan 12, 2026We introduce Fiducial Exoskeletons, an image-based reformulation of 3D robot state estimation that replaces cumbersome procedures and motor-centric pipelines with single-image inference. Traditional approaches - especially robot-camera extrinsic estimation - often rely on high-precision actuators and require time-consuming routines such as hand-eye calibration. In contrast, modern learning-based robot control is increasingly trained and deployed from RGB observations on lower-cost hardware. Our key insight is twofold. First, we cast robot state estimation as 6D pose estimation of each link from a single RGB image: the robot-camera base transform is obtained directly as the estimated base-link pose, and the joint state is recovered via a lightweight global optimization that enforces kinematic consistency with the observed link poses (optionally warm-started with encoder readings). Second, we make per-link 6D pose estimation robust and simple - even without learning - by introducing the fiducial exoskeleton: a lightweight 3D-printed mount with a fiducial marker on each link and known marker-link geometry. This design yields robust camera-robot extrinsics, per-link SE(3) poses, and joint-angle state from a single image, enabling robust state estimation even on unplugged robots. Demonstrated on a low-cost robot arm, fiducial exoskeletons substantially simplify setup while improving calibration, state accuracy, and downstream 3D control performance. We release code and printable hardware designs to enable further algorithm-hardware co-design.
SIRE: SE(3) Intrinsic Rigidity Embeddings
Mar 10, 2025



Motion serves as a powerful cue for scene perception and understanding by separating independently moving surfaces and organizing the physical world into distinct entities. We introduce SIRE, a self-supervised method for motion discovery of objects and dynamic scene reconstruction from casual scenes by learning intrinsic rigidity embeddings from videos. Our method trains an image encoder to estimate scene rigidity and geometry, supervised by a simple 4D reconstruction loss: a least-squares solver uses the estimated geometry and rigidity to lift 2D point track trajectories into SE(3) tracks, which are simply re-projected back to 2D and compared against the original 2D trajectories for supervision. Crucially, our framework is fully end-to-end differentiable and can be optimized either on video datasets to learn generalizable image priors, or even on a single video to capture scene-specific structure - highlighting strong data efficiency. We demonstrate the effectiveness of our rigidity embeddings and geometry across multiple settings, including downstream object segmentation, SE(3) rigid motion estimation, and self-supervised depth estimation. Our findings suggest that SIRE can learn strong geometry and motion rigidity priors from video data, with minimal supervision.
Variational methods for Learning Multilevel Genetic Algorithms using the Kantorovich Monad
Nov 14, 2024



Levels of selection and multilevel evolutionary processes are essential concepts in evolutionary theory, and yet there is a lack of common mathematical models for these core ideas. Here, we propose a unified mathematical framework for formulating and optimizing multilevel evolutionary processes and genetic algorithms over arbitrarily many levels based on concepts from category theory and population genetics. We formulate a multilevel version of the Wright-Fisher process using this approach, and we show that this model can be analyzed to clarify key features of multilevel selection. Particularly, we derive an extended multilevel probabilistic version of Price's Equation via the Kantorovich Monad, and we use this to characterize regimes of parameter space within which selection acts antagonistically or cooperatively across levels. Finally, we show how our framework can provide a unified setting for learning genetic algorithms (GAs), and we show how we can use a Variational Optimization and a multi-level analogue of coalescent analysis to fit multilevel GAs to simulated data.
FlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent
Apr 23, 2024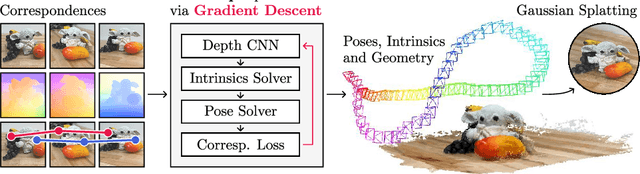


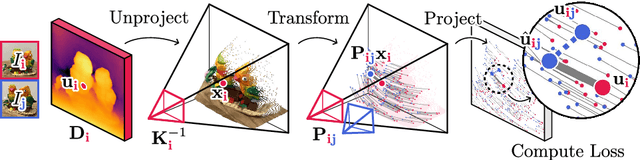
This paper introduces FlowMap, an end-to-end differentiable method that solves for precise camera poses, camera intrinsics, and per-frame dense depth of a video sequence. Our method performs per-video gradient-descent minimization of a simple least-squares objective that compares the optical flow induced by depth, intrinsics, and poses against correspondences obtained via off-the-shelf optical flow and point tracking. Alongside the use of point tracks to encourage long-term geometric consistency, we introduce differentiable re-parameterizations of depth, intrinsics, and pose that are amenable to first-order optimization. We empirically show that camera parameters and dense depth recovered by our method enable photo-realistic novel view synthesis on 360-degree trajectories using Gaussian Splatting. Our method not only far outperforms prior gradient-descent based bundle adjustment methods, but surprisingly performs on par with COLMAP, the state-of-the-art SfM method, on the downstream task of 360-degree novel view synthesis (even though our method is purely gradient-descent based, fully differentiable, and presents a complete departure from conventional SfM).
SmartMask: Context Aware High-Fidelity Mask Generation for Fine-grained Object Insertion and Layout Control
Dec 08, 2023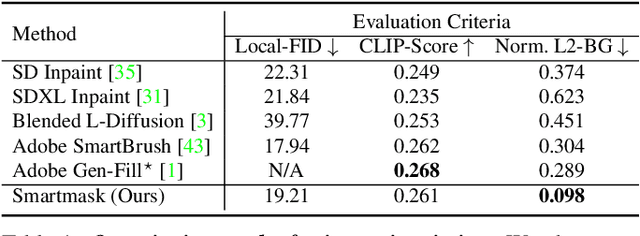
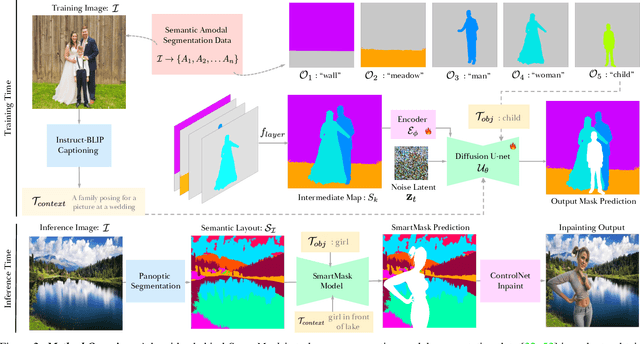
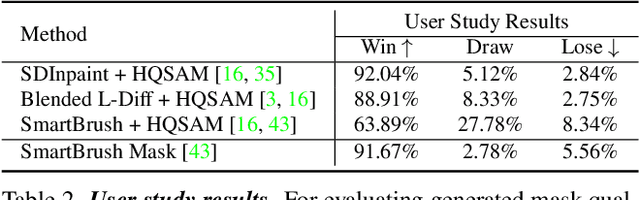

The field of generative image inpainting and object insertion has made significant progress with the recent advent of latent diffusion models. Utilizing a precise object mask can greatly enhance these applications. However, due to the challenges users encounter in creating high-fidelity masks, there is a tendency for these methods to rely on more coarse masks (e.g., bounding box) for these applications. This results in limited control and compromised background content preservation. To overcome these limitations, we introduce SmartMask, which allows any novice user to create detailed masks for precise object insertion. Combined with a ControlNet-Inpaint model, our experiments demonstrate that SmartMask achieves superior object insertion quality, preserving the background content more effectively than previous methods. Notably, unlike prior works the proposed approach can also be used even without user-mask guidance, which allows it to perform mask-free object insertion at diverse positions and scales. Furthermore, we find that when used iteratively with a novel instruction-tuning based planning model, SmartMask can be used to design detailed layouts from scratch. As compared with user-scribble based layout design, we observe that SmartMask allows for better quality outputs with layout-to-image generation methods. Project page is available at https://smartmask-gen.github.io
FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow
May 31, 2023Reconstruction of 3D neural fields from posed images has emerged as a promising method for self-supervised representation learning. The key challenge preventing the deployment of these 3D scene learners on large-scale video data is their dependence on precise camera poses from structure-from-motion, which is prohibitively expensive to run at scale. We propose a method that jointly reconstructs camera poses and 3D neural scene representations online and in a single forward pass. We estimate poses by first lifting frame-to-frame optical flow to 3D scene flow via differentiable rendering, preserving locality and shift-equivariance of the image processing backbone. SE(3) camera pose estimation is then performed via a weighted least-squares fit to the scene flow field. This formulation enables us to jointly supervise pose estimation and a generalizable neural scene representation via re-rendering the input video, and thus, train end-to-end and fully self-supervised on real-world video datasets. We demonstrate that our method performs robustly on diverse, real-world video, notably on sequences traditionally challenging to optimization-based pose estimation techniques.
Learning to Render Novel Views from Wide-Baseline Stereo Pairs
Apr 17, 2023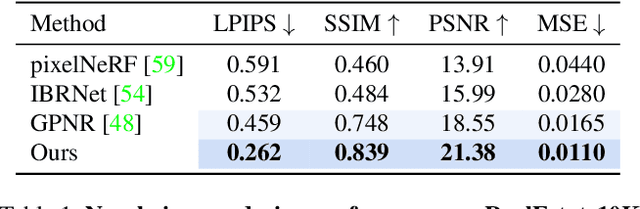
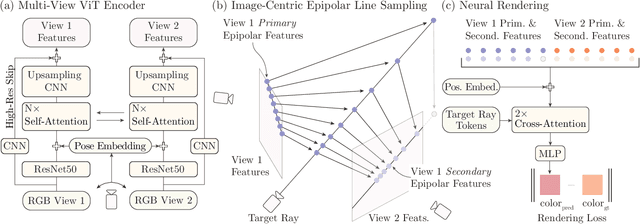
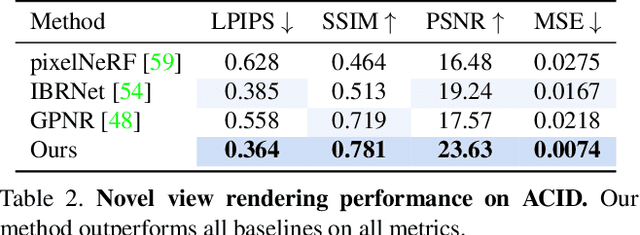

We introduce a method for novel view synthesis given only a single wide-baseline stereo image pair. In this challenging regime, 3D scene points are regularly observed only once, requiring prior-based reconstruction of scene geometry and appearance. We find that existing approaches to novel view synthesis from sparse observations fail due to recovering incorrect 3D geometry and due to the high cost of differentiable rendering that precludes their scaling to large-scale training. We take a step towards resolving these shortcomings by formulating a multi-view transformer encoder, proposing an efficient, image-space epipolar line sampling scheme to assemble image features for a target ray, and a lightweight cross-attention-based renderer. Our contributions enable training of our method on a large-scale real-world dataset of indoor and outdoor scenes. We demonstrate that our method learns powerful multi-view geometry priors while reducing the rendering time. We conduct extensive comparisons on held-out test scenes across two real-world datasets, significantly outperforming prior work on novel view synthesis from sparse image observations and achieving multi-view-consistent novel view synthesis.
In-N-Out: Face Video Inversion and Editing with Volumetric Decomposition
Feb 09, 20233D-aware GANs offer new capabilities for creative content editing, such as view synthesis, while preserving the editing capability of their 2D counterparts. Using GAN inversion, these methods can reconstruct an image or a video by optimizing/predicting a latent code and achieve semantic editing by manipulating the latent code. However, a model pre-trained on a face dataset (e.g., FFHQ) often has difficulty handling faces with out-of-distribution (OOD) objects, (e.g., heavy make-up or occlusions). We address this issue by explicitly modeling OOD objects in face videos. Our core idea is to represent the face in a video using two neural radiance fields, one for in-distribution and the other for out-of-distribution data, and compose them together for reconstruction. Such explicit decomposition alleviates the inherent trade-off between reconstruction fidelity and editability. We evaluate our method's reconstruction accuracy and editability on challenging real videos and showcase favorable results against other baselines.
Paint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
Aug 17, 2022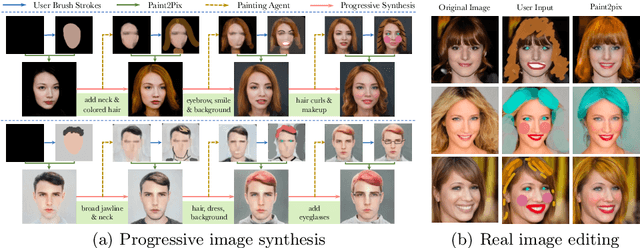
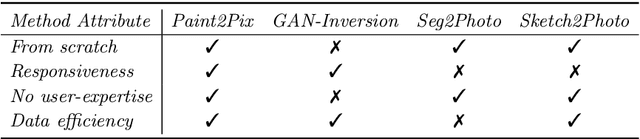
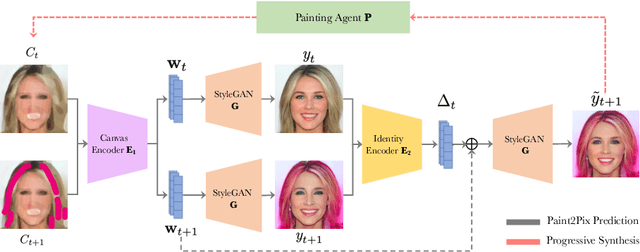
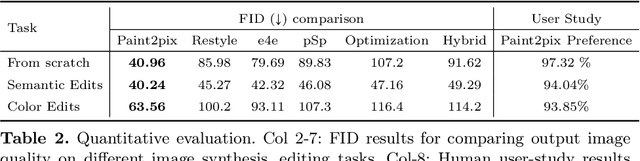
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) "what a user wants to draw" from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Supplemental video and demo are available at https://1jsingh.github.io/paint2pix
* ECCV 2022
Unsupervised Discovery and Composition of Object Light Fields
May 08, 2022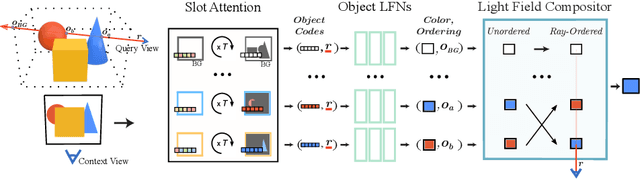

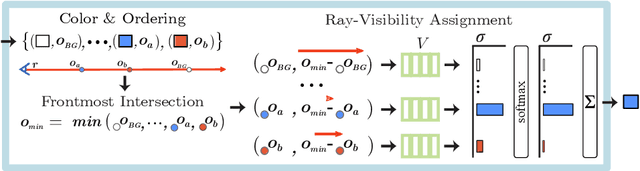

Neural scene representations, both continuous and discrete, have recently emerged as a powerful new paradigm for 3D scene understanding. Recent efforts have tackled unsupervised discovery of object-centric neural scene representations. However, the high cost of ray-marching, exacerbated by the fact that each object representation has to be ray-marched separately, leads to insufficiently sampled radiance fields and thus, noisy renderings, poor framerates, and high memory and time complexity during training and rendering. Here, we propose to represent objects in an object-centric, compositional scene representation as light fields. We propose a novel light field compositor module that enables reconstructing the global light field from a set of object-centric light fields. Dubbed Compositional Object Light Fields (COLF), our method enables unsupervised learning of object-centric neural scene representations, state-of-the-art reconstruction and novel view synthesis performance on standard datasets, and rendering and training speeds at orders of magnitude faster than existing 3D approaches.