 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
Aug 17, 2022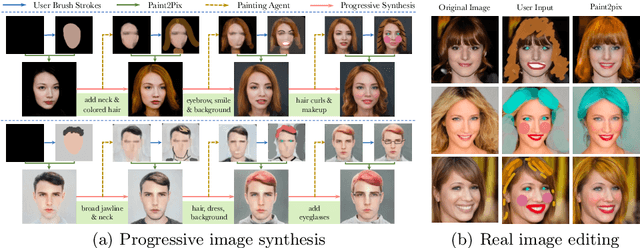
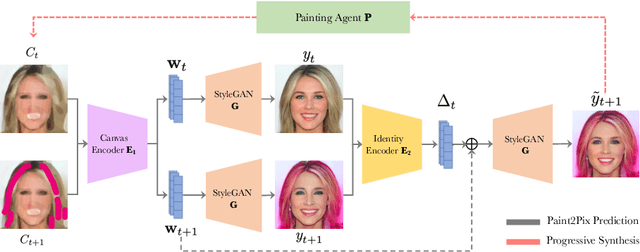
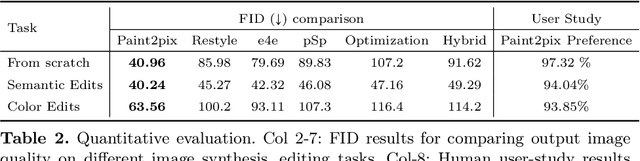
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) "what a user wants to draw" from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Supplemental video and demo are available at https://1jsingh.github.io/paint2pix
* ECCV 2022
Interactive Portrait Harmonization
Mar 15, 2022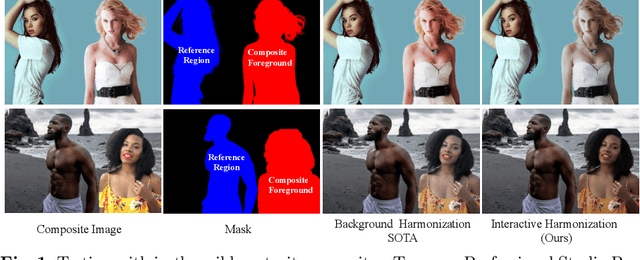
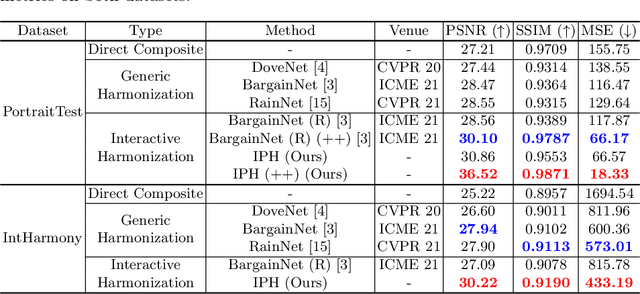

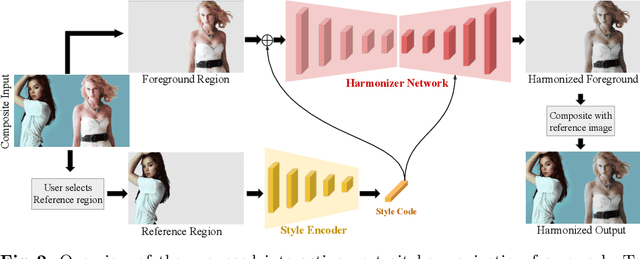
Current image harmonization methods consider the entire background as the guidance for harmonization. However, this may limit the capability for user to choose any specific object/person in the background to guide the harmonization. To enable flexible interaction between user and harmonization, we introduce interactive harmonization, a new setting where the harmonization is performed with respect to a selected \emph{region} in the reference image instead of the entire background. A new flexible framework that allows users to pick certain regions of the background image and use it to guide the harmonization is proposed. Inspired by professional portrait harmonization users, we also introduce a new luminance matching loss to optimally match the color/luminance conditions between the composite foreground and select reference region. This framework provides more control to the image harmonization pipeline achieving visually pleasing portrait edits. Furthermore, we also introduce a new dataset carefully curated for validating portrait harmonization. Extensive experiments on both synthetic and real-world datasets show that the proposed approach is efficient and robust compared to previous harmonization baselines, especially for portraits. Project Webpage at \href{https://jeya-maria-jose.github.io/IPH-web/}{https://jeya-maria-jose.github.io/IPH-web/}
Intelli-Paint: Towards Developing Human-like Painting Agents
Dec 16, 2021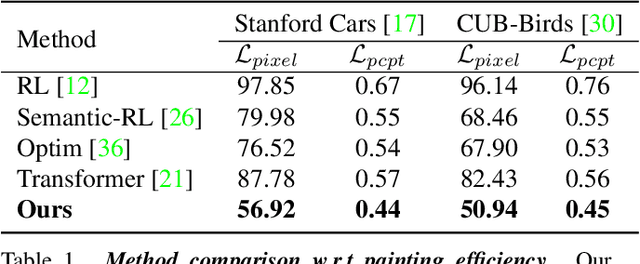
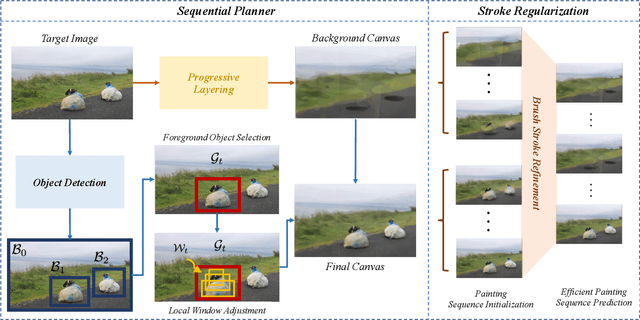


The generation of well-designed artwork is often quite time-consuming and assumes a high degree of proficiency on part of the human painter. In order to facilitate the human painting process, substantial research efforts have been made on teaching machines how to "paint like a human", and then using the trained agent as a painting assistant tool for human users. However, current research in this direction is often reliant on a progressive grid-based division strategy wherein the agent divides the overall image into successively finer grids, and then proceeds to paint each of them in parallel. This inevitably leads to artificial painting sequences which are not easily intelligible to human users. To address this, we propose a novel painting approach which learns to generate output canvases while exhibiting a more human-like painting style. The proposed painting pipeline Intelli-Paint consists of 1) a progressive layering strategy which allows the agent to first paint a natural background scene representation before adding in each of the foreground objects in a progressive fashion. 2) We also introduce a novel sequential brushstroke guidance strategy which helps the painting agent to shift its attention between different image regions in a semantic-aware manner. 3) Finally, we propose a brushstroke regularization strategy which allows for ~60-80% reduction in the total number of required brushstrokes without any perceivable differences in the quality of the generated canvases. Through both quantitative and qualitative results, we show that the resulting agents not only show enhanced efficiency in output canvas generation but also exhibit a more natural-looking painting style which would better assist human users express their ideas through digital artwork.
A Learned Compact and Editable Light Field Representation
Mar 21, 2021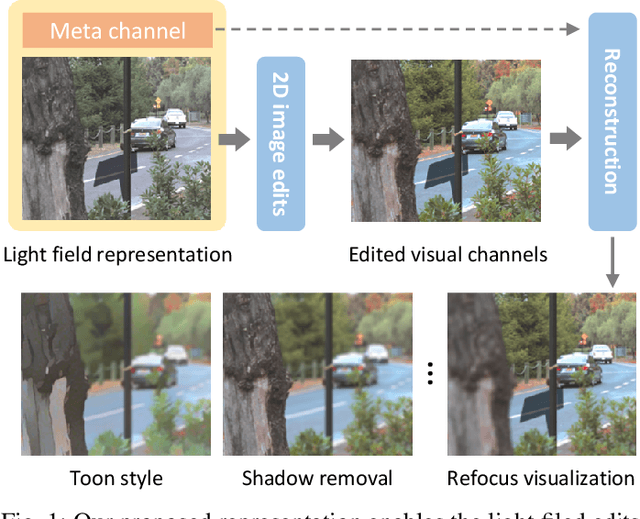



Light fields are 4D scene representation typically structured as arrays of views, or several directional samples per pixel in a single view. This highly correlated structure is not very efficient to transmit and manipulate (especially for editing), though. To tackle these problems, we present a novel compact and editable light field representation, consisting of a set of visual channels (i.e. the central RGB view) and a complementary meta channel that encodes the residual geometric and appearance information. The visual channels in this representation can be edited using existing 2D image editing tools, before accurately reconstructing the whole edited light field back. We propose to learn this representation via an autoencoder framework, consisting of an encoder for learning the representation, and a decoder for reconstructing the light field. To handle the challenging occlusions and propagation of edits, we specifically designed an editing-aware decoding network and its associated training strategy, so that the edits to the visual channels can be consistently propagated to the whole light field upon reconstruction.Experimental results show that our proposed method outperforms related existing methods in reconstruction accuracy, and achieves visually pleasant performance in editing propagation.
Learning to Emphasize: Dataset and Shared Task Models for Selecting Emphasis in Presentation Slides
Jan 02, 2021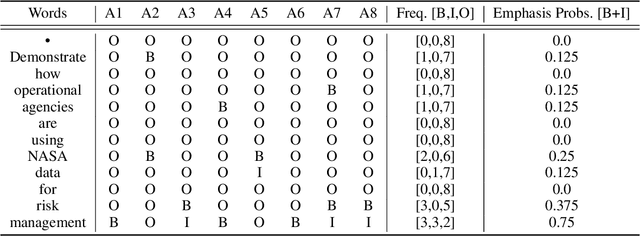
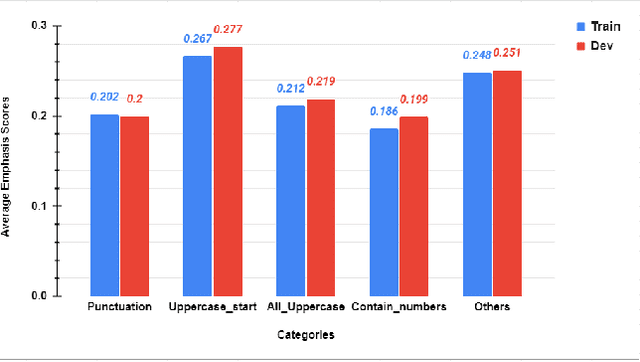
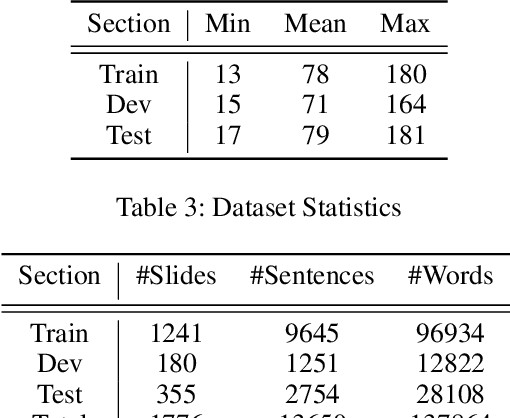
Presentation slides have become a common addition to the teaching material. Emphasizing strong leading words in presentation slides can allow the audience to direct the eye to certain focal points instead of reading the entire slide, retaining the attention to the speaker during the presentation. Despite a large volume of studies on automatic slide generation, few studies have addressed the automation of design assistance during the creation process. Motivated by this demand, we study the problem of Emphasis Selection (ES) in presentation slides, i.e., choosing candidates for emphasis, by introducing a new dataset containing presentation slides with a wide variety of topics, each is annotated with emphasis words in a crowdsourced setting. We evaluate a range of state-of-the-art models on this novel dataset by organizing a shared task and inviting multiple researchers to model emphasis in this new domain. We present the main findings and compare the results of these models, and by examining the challenges of the dataset, we provide different analysis components.
SemEval-2020 Task 10: Emphasis Selection for Written Text in Visual Media
Aug 07, 2020

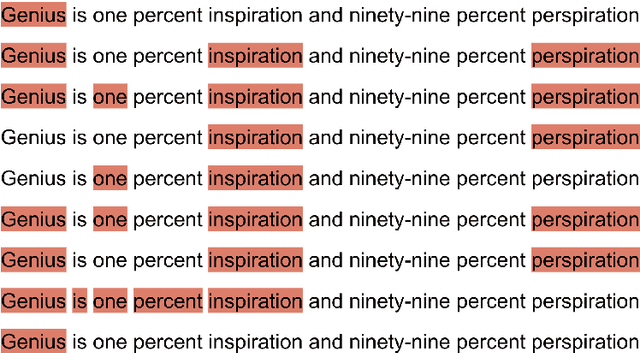

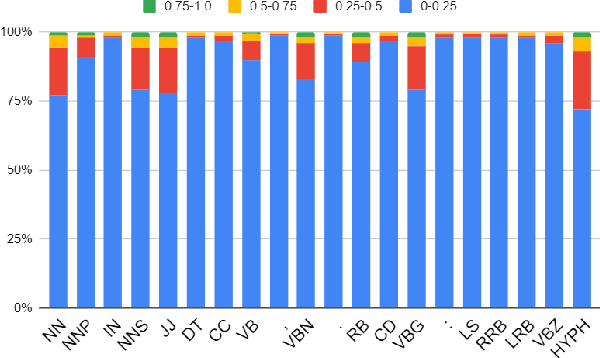
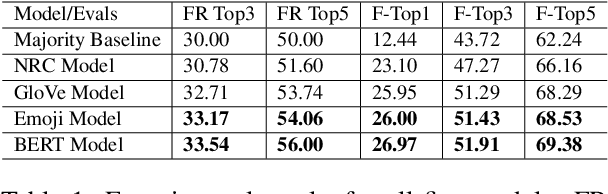
In this paper, we present the main findings and compare the results of SemEval-2020 Task 10, Emphasis Selection for Written Text in Visual Media. The goal of this shared task is to design automatic methods for emphasis selection, i.e. choosing candidates for emphasis in textual content to enable automated design assistance in authoring. The main focus is on short text instances for social media, with a variety of examples, from social media posts to inspirational quotes. Participants were asked to model emphasis using plain text with no additional context from the user or other design considerations. SemEval-2020 Emphasis Selection shared task attracted 197 participants in the early phase and a total of 31 teams made submissions to this task. The highest-ranked submission achieved 0.823 Matchm score. The analysis of systems submitted to the task indicates that BERT and RoBERTa were the most common choice of pre-trained models used, and part of speech tag (POS) was the most useful feature. Full results can be found on the task's website.
Let Me Choose: From Verbal Context to Font Selection
May 03, 2020
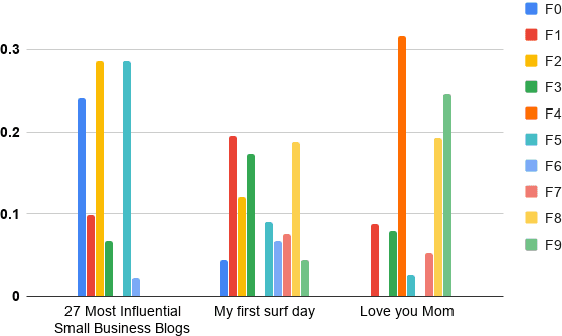
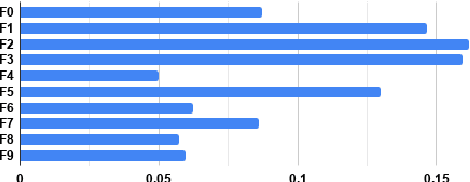
In this paper, we aim to learn associations between visual attributes of fonts and the verbal context of the texts they are typically applied to. Compared to related work leveraging the surrounding visual context, we choose to focus only on the input text as this can enable new applications for which the text is the only visual element in the document. We introduce a new dataset, containing examples of different topics in social media posts and ads, labeled through crowd-sourcing. Due to the subjective nature of the task, multiple fonts might be perceived as acceptable for an input text, which makes this problem challenging. To this end, we investigate different end-to-end models to learn label distributions on crowd-sourced data and capture inter-subjectivity across all annotations.
MakeItTalk: Speaker-Aware Talking-Head Animation
Apr 27, 2020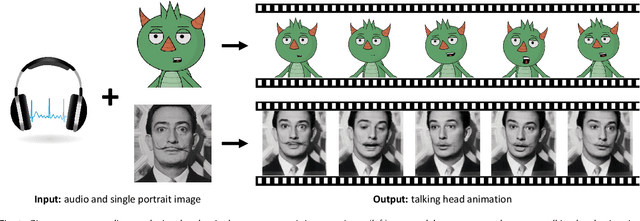

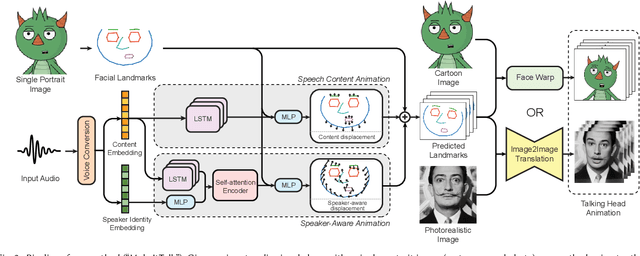
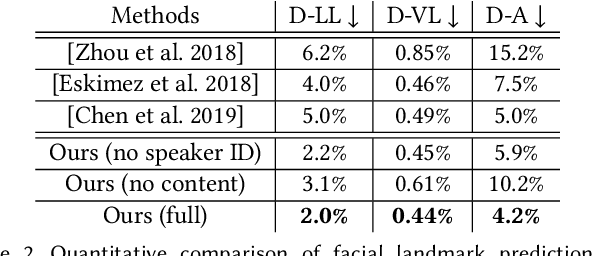
We present a method that generates expressive talking heads from a single facial image with audio as the only input. In contrast to previous approaches that attempt to learn direct mappings from audio to raw pixels or points for creating talking faces, our method first disentangles the content and speaker information in the input audio signal. The audio content robustly controls the motion of lips and nearby facial regions, while the speaker information determines the specifics of facial expressions and the rest of the talking head dynamics. Another key component of our method is the prediction of facial landmarks reflecting speaker-aware dynamics. Based on this intermediate representation, our method is able to synthesize photorealistic videos of entire talking heads with full range of motion and also animate artistic paintings, sketches, 2D cartoon characters, Japanese mangas, stylized caricatures in a single unified framework. We present extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating generated talking heads of significantly higher quality compared to prior state-of-the-art.
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Apr 15, 2020
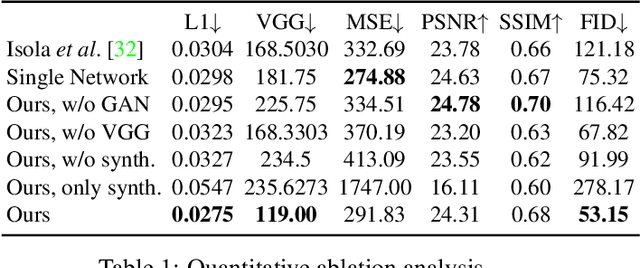
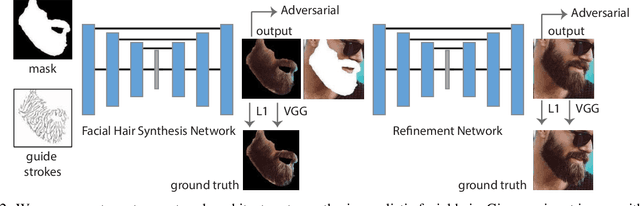

We present an interactive approach to synthesizing realistic variations in facial hair in images, ranging from subtle edits to existing hair to the addition of complex and challenging hair in images of clean-shaven subjects. To circumvent the tedious and computationally expensive tasks of modeling, rendering and compositing the 3D geometry of the target hairstyle using the traditional graphics pipeline, we employ a neural network pipeline that synthesizes realistic and detailed images of facial hair directly in the target image in under one second. The synthesis is controlled by simple and sparse guide strokes from the user defining the general structural and color properties of the target hairstyle. We qualitatively and quantitatively evaluate our chosen method compared to several alternative approaches. We show compelling interactive editing results with a prototype user interface that allows novice users to progressively refine the generated image to match their desired hairstyle, and demonstrate that our approach also allows for flexible and high-fidelity scalp hair synthesis.
Texture Hallucination for Large-Scale Painting Super-Resolution
Dec 01, 2019
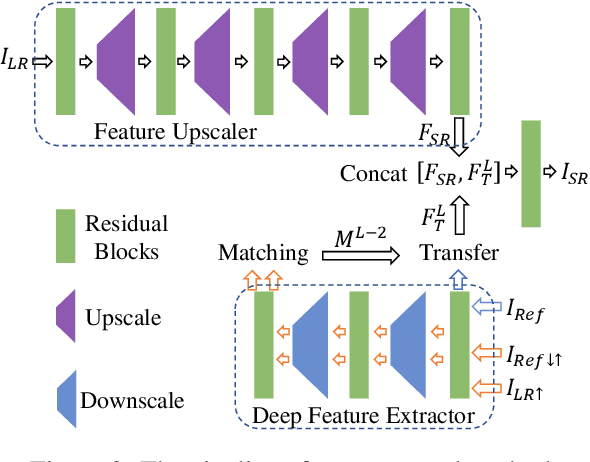
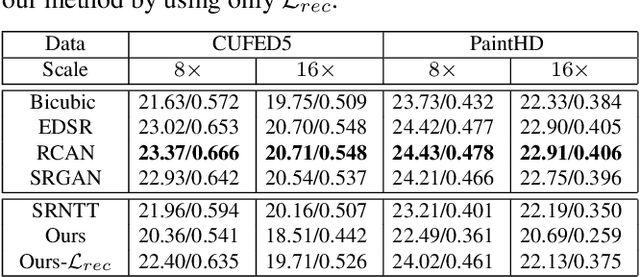
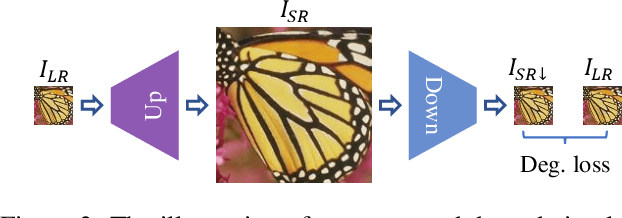
We aim to super-resolve digital paintings, synthesizing realistic details from high-resolution reference painting materials for very large scaling factors (e.g., 8x, 16x). However, previous single image super-resolution (SISR) methods would either lose textural details or introduce unpleasing artifacts. On the other hand, reference-based SR (Ref-SR) methods can transfer textures to some extent, but is still impractical to handle very large scales and keep fidelity with original input. To solve these problems, we propose an efficient high-resolution hallucination network for very large scaling factors with efficient network structure and feature transferring. To transfer more detailed textures, we design a wavelet texture loss, which helps to enhance more high-frequency components. At the same time, to reduce the smoothing effect brought by the image reconstruction loss, we further relax the reconstruction constraint with a degradation loss which ensures the consistency between downscaled super-resolution results and low-resolution inputs. We also collected a high-resolution (e.g., 4K resolution) painting dataset PaintHD by considering both physical size and image resolution. We demonstrate the effectiveness of our method with extensive experiments on PaintHD by comparing with SISR and Ref-SR state-of-the-art methods.