 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Me Choose: From Verbal Context to Font Selection
Paper and Code

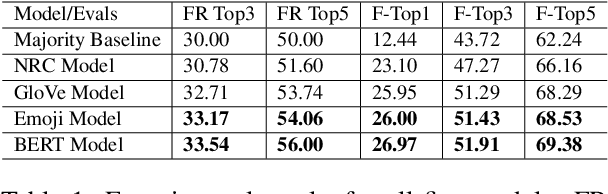
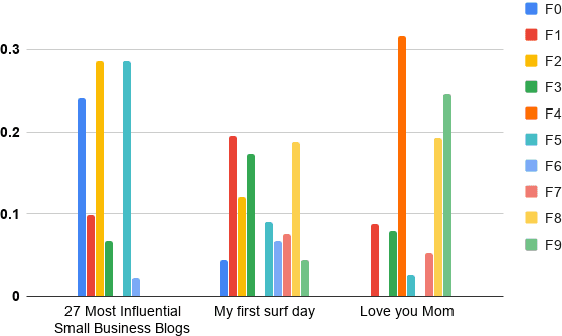
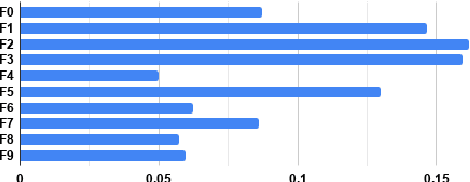
In this paper, we aim to learn associations between visual attributes of fonts and the verbal context of the texts they are typically applied to. Compared to related work leveraging the surrounding visual context, we choose to focus only on the input text as this can enable new applications for which the text is the only visual element in the document. We introduce a new dataset, containing examples of different topics in social media posts and ads, labeled through crowd-sourcing. Due to the subjective nature of the task, multiple fonts might be perceived as acceptable for an input text, which makes this problem challenging. To this end, we investigate different end-to-end models to learn label distributions on crowd-sourced data and capture inter-subjectivity across all annotations.