 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Emphasize: Dataset and Shared Task Models for Selecting Emphasis in Presentation Slides
Jan 02, 2021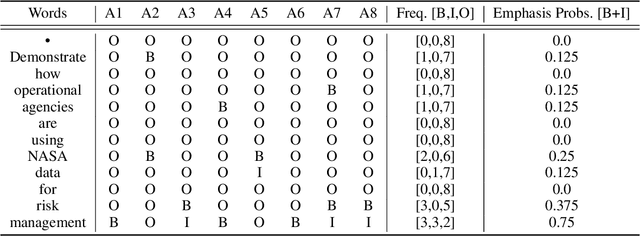
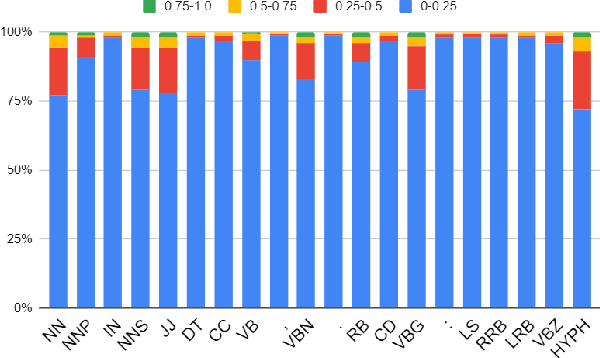
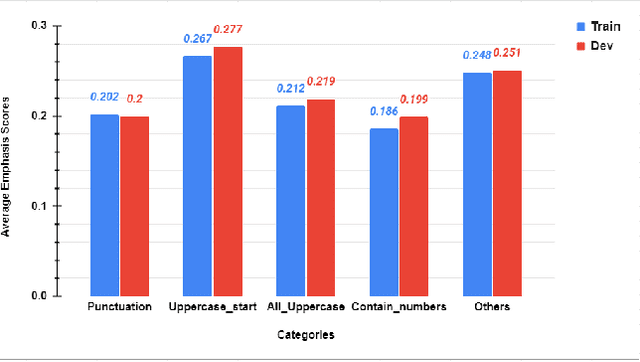
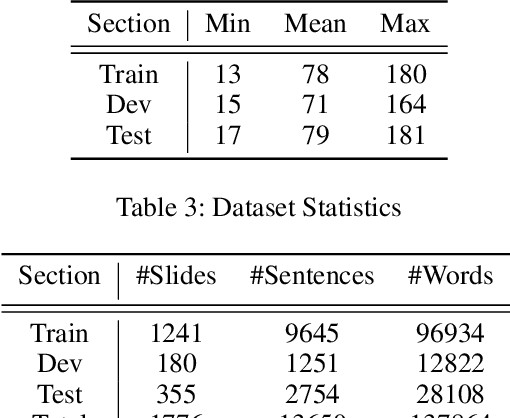
Presentation slides have become a common addition to the teaching material. Emphasizing strong leading words in presentation slides can allow the audience to direct the eye to certain focal points instead of reading the entire slide, retaining the attention to the speaker during the presentation. Despite a large volume of studies on automatic slide generation, few studies have addressed the automation of design assistance during the creation process. Motivated by this demand, we study the problem of Emphasis Selection (ES) in presentation slides, i.e., choosing candidates for emphasis, by introducing a new dataset containing presentation slides with a wide variety of topics, each is annotated with emphasis words in a crowdsourced setting. We evaluate a range of state-of-the-art models on this novel dataset by organizing a shared task and inviting multiple researchers to model emphasis in this new domain. We present the main findings and compare the results of these models, and by examining the challenges of the dataset, we provide different analysis components.
SemEval-2020 Task 10: Emphasis Selection for Written Text in Visual Media
Aug 07, 2020

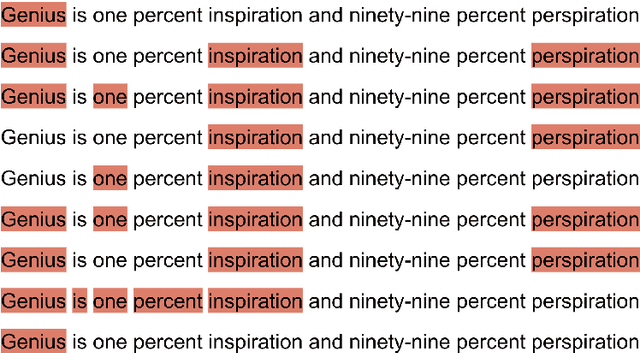

In this paper, we present the main findings and compare the results of SemEval-2020 Task 10, Emphasis Selection for Written Text in Visual Media. The goal of this shared task is to design automatic methods for emphasis selection, i.e. choosing candidates for emphasis in textual content to enable automated design assistance in authoring. The main focus is on short text instances for social media, with a variety of examples, from social media posts to inspirational quotes. Participants were asked to model emphasis using plain text with no additional context from the user or other design considerations. SemEval-2020 Emphasis Selection shared task attracted 197 participants in the early phase and a total of 31 teams made submissions to this task. The highest-ranked submission achieved 0.823 Matchm score. The analysis of systems submitted to the task indicates that BERT and RoBERTa were the most common choice of pre-trained models used, and part of speech tag (POS) was the most useful feature. Full results can be found on the task's website.
Let Me Choose: From Verbal Context to Font Selection
May 03, 2020
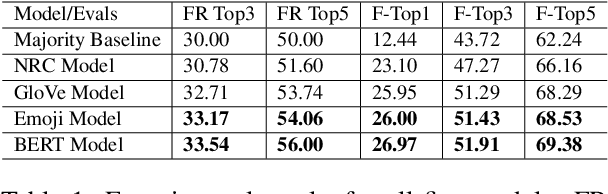
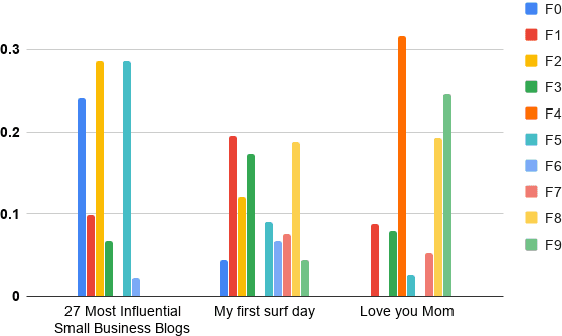
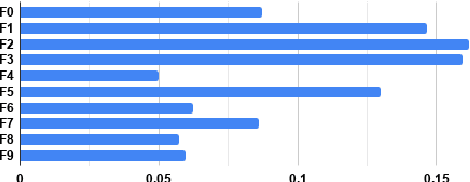
In this paper, we aim to learn associations between visual attributes of fonts and the verbal context of the texts they are typically applied to. Compared to related work leveraging the surrounding visual context, we choose to focus only on the input text as this can enable new applications for which the text is the only visual element in the document. We introduce a new dataset, containing examples of different topics in social media posts and ads, labeled through crowd-sourcing. Due to the subjective nature of the task, multiple fonts might be perceived as acceptable for an input text, which makes this problem challenging. To this end, we investigate different end-to-end models to learn label distributions on crowd-sourced data and capture inter-subjectivity across all annotations.
Question Relatedness on Stack Overflow: The Task, Dataset, and Corpus-inspired Models
May 07, 2019
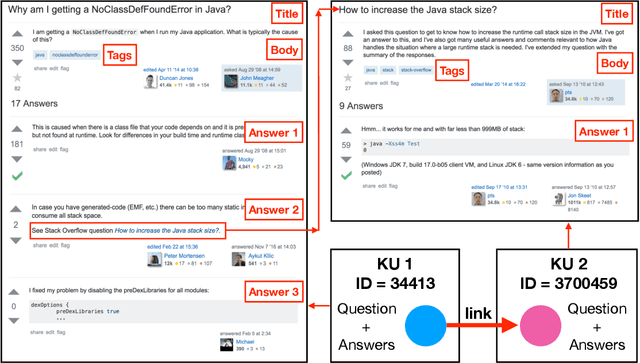
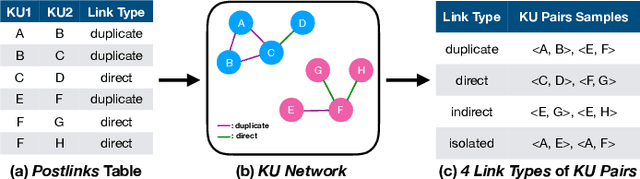

Domain-specific community question answering is becoming an integral part of professions. Finding related questions and answers in these communities can significantly improve the effectiveness and efficiency of information seeking. Stack Overflow is one of the most popular communities that is being used by millions of programmers. In this paper, we analyze the problem of predicting knowledge unit (question thread) relatedness in Stack Overflow. In particular, we formulate the question relatedness task as a multi-class classification problem with four degrees of relatedness. We present a large-scale dataset with more than 300K pairs. To the best of our knowledge, this dataset is the largest domain-specific dataset for Question-Question relatedness. We present the steps that we took to collect, clean, process, and assure the quality of the dataset. The proposed dataset Stack Overflow is a useful resource to develop novel solutions, specifically data-hungry neural network models, for the prediction of relatedness in technical community question-answering forums. We adopt a neural network architecture and a traditional model for this task that effectively utilize information from different parts of knowledge units to compute the relatedness between them. These models can be used to benchmark novel models, as they perform well in our task and in a closely similar task.