 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2020 Task 10: Emphasis Selection for Written Text in Visual Media
Paper and Code


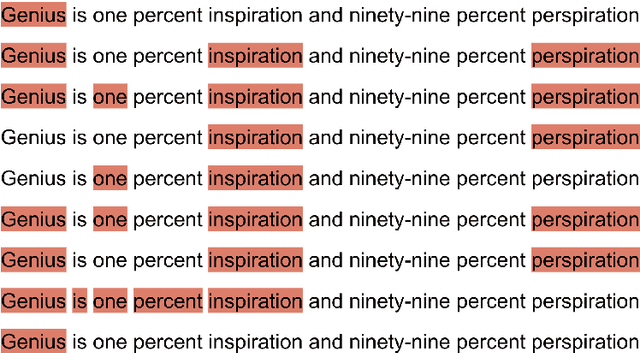

In this paper, we present the main findings and compare the results of SemEval-2020 Task 10, Emphasis Selection for Written Text in Visual Media. The goal of this shared task is to design automatic methods for emphasis selection, i.e. choosing candidates for emphasis in textual content to enable automated design assistance in authoring. The main focus is on short text instances for social media, with a variety of examples, from social media posts to inspirational quotes. Participants were asked to model emphasis using plain text with no additional context from the user or other design considerations. SemEval-2020 Emphasis Selection shared task attracted 197 participants in the early phase and a total of 31 teams made submissions to this task. The highest-ranked submission achieved 0.823 Matchm score. The analysis of systems submitted to the task indicates that BERT and RoBERTa were the most common choice of pre-trained models used, and part of speech tag (POS) was the most useful feature. Full results can be found on the task's website.