 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learned Compact and Editable Light Field Representation
Paper and Code
Mar 21, 2021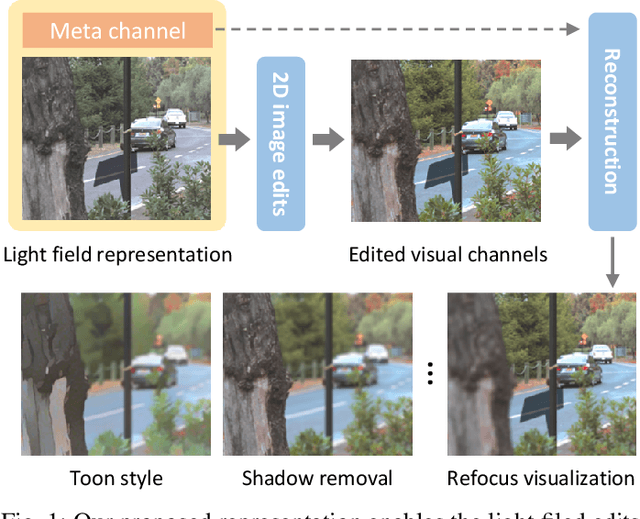



Light fields are 4D scene representation typically structured as arrays of views, or several directional samples per pixel in a single view. This highly correlated structure is not very efficient to transmit and manipulate (especially for editing), though. To tackle these problems, we present a novel compact and editable light field representation, consisting of a set of visual channels (i.e. the central RGB view) and a complementary meta channel that encodes the residual geometric and appearance information. The visual channels in this representation can be edited using existing 2D image editing tools, before accurately reconstructing the whole edited light field back. We propose to learn this representation via an autoencoder framework, consisting of an encoder for learning the representation, and a decoder for reconstructing the light field. To handle the challenging occlusions and propagation of edits, we specifically designed an editing-aware decoding network and its associated training strategy, so that the edits to the visual channels can be consistently propagated to the whole light field upon reconstruction.Experimental results show that our proposed method outperforms related existing methods in reconstruction accuracy, and achieves visually pleasant performance in editing propagation.