 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2Manga: Shaded Manga Screening from Sketch with Diffusion Models
Mar 13, 2024While manga is a popular entertainment form, creating manga is tedious, especially adding screentones to the created sketch, namely manga screening. Unfortunately, there is no existing method that tailors for automatic manga screening, probably due to the difficulty of generating high-quality shaded high-frequency screentones. The classic manga screening approaches generally require user input to provide screentone exemplars or a reference manga image. The recent deep learning models enables the automatic generation by learning from a large-scale dataset. However, the state-of-the-art models still fail to generate high-quality shaded screentones due to the lack of a tailored model and high-quality manga training data. In this paper, we propose a novel sketch-to-manga framework that first generates a color illustration from the sketch and then generates a screentoned manga based on the intensity guidance. Our method significantly outperforms existing methods in generating high-quality manga with shaded high-frequency screentones.
Highly Detailed and Temporal Consistent Video Stylization via Synchronized Multi-Frame Diffusion
Nov 24, 2023



Text-guided video-to-video stylization transforms the visual appearance of a source video to a different appearance guided on textual prompts. Existing text-guided image diffusion models can be extended for stylized video synthesis. However, they struggle to generate videos with both highly detailed appearance and temporal consistency. In this paper, we propose a synchronized multi-frame diffusion framework to maintain both the visual details and the temporal consistency. Frames are denoised in a synchronous fashion, and more importantly, information of different frames is shared since the beginning of the denoising process. Such information sharing ensures that a consensus, in terms of the overall structure and color distribution, among frames can be reached in the early stage of the denoising process before it is too late. The optical flow from the original video serves as the connection, and hence the venue for information sharing, among frames. We demonstrate the effectiveness of our method in generating high-quality and diverse results in extensive experiments. Our method shows superior qualitative and quantitative results compared to state-of-the-art video editing methods.
Text-Guided Texturing by Synchronized Multi-View Diffusion
Nov 21, 2023



This paper introduces a novel approach to synthesize texture to dress up a given 3D object, given a text prompt. Based on the pretrained text-to-image (T2I) diffusion model, existing methods usually employ a project-and-inpaint approach, in which a view of the given object is first generated and warped to another view for inpainting. But it tends to generate inconsistent texture due to the asynchronous diffusion of multiple views. We believe such asynchronous diffusion and insufficient information sharing among views are the root causes of the inconsistent artifact. In this paper, we propose a synchronized multi-view diffusion approach that allows the diffusion processes from different views to reach a consensus of the generated content early in the process, and hence ensures the texture consistency. To synchronize the diffusion, we share the denoised content among different views in each denoising step, specifically blending the latent content in the texture domain from views with overlap. Our method demonstrates superior performance in generating consistent, seamless, highly detailed textures, comparing to state-of-the-art methods.
Manga Rescreening with Interpretable Screentone Representation
Jun 07, 2023The process of adapting or repurposing manga pages is a time-consuming task that requires manga artists to manually work on every single screentone region and apply new patterns to create novel screentones across multiple panels. To address this issue, we propose an automatic manga rescreening pipeline that aims to minimize the human effort involved in manga adaptation. Our pipeline automatically recognizes screentone regions and generates novel screentones with newly specified characteristics (e.g., intensity or type). Existing manga generation methods have limitations in understanding and synthesizing complex tone- or intensity-varying regions. To overcome these limitations, we propose a novel interpretable representation of screentones that disentangles their intensity and type features, enabling better recognition and synthesis of screentones. This interpretable screentone representation reduces ambiguity in recognizing intensity-varying regions and provides fine-grained controls during screentone synthesis by decoupling and anchoring the type or the intensity feature. Our proposed method is demonstrated to be effective and convenient through various experiments, showcasing the superiority of the newly proposed pipeline with the interpretable screentone representations.
Video Colorization with Pre-trained Text-to-Image Diffusion Models
Jun 02, 2023
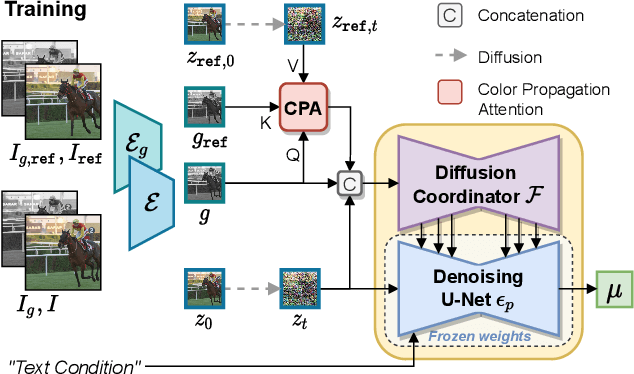


Video colorization is a challenging task that involves inferring plausible and temporally consistent colors for grayscale frames. In this paper, we present ColorDiffuser, an adaptation of a pre-trained text-to-image latent diffusion model for video colorization. With the proposed adapter-based approach, we repropose the pre-trained text-to-image model to accept input grayscale video frames, with the optional text description, for video colorization. To enhance the temporal coherence and maintain the vividness of colorization across frames, we propose two novel techniques: the Color Propagation Attention and Alternated Sampling Strategy. Color Propagation Attention enables the model to refine its colorization decision based on a reference latent frame, while Alternated Sampling Strategy captures spatiotemporal dependencies by using the next and previous adjacent latent frames alternatively as reference during the generative diffusion sampling steps. This encourages bidirectional color information propagation between adjacent video frames, leading to improved color consistency across frames. We conduct extensive experiments on benchmark datasets, and the results demonstrate the effectiveness of our proposed framework. The evaluations show that ColorDiffuser achieves state-of-the-art performance in video colorization, surpassing existing methods in terms of color fidelity, temporal consistency, and visual quality.
Improved Diffusion-based Image Colorization via Piggybacked Models
Apr 21, 2023



Image colorization has been attracting the research interests of the community for decades. However, existing methods still struggle to provide satisfactory colorized results given grayscale images due to a lack of human-like global understanding of colors. Recently, large-scale Text-to-Image (T2I) models have been exploited to transfer the semantic information from the text prompts to the image domain, where text provides a global control for semantic objects in the image. In this work, we introduce a colorization model piggybacking on the existing powerful T2I diffusion model. Our key idea is to exploit the color prior knowledge in the pre-trained T2I diffusion model for realistic and diverse colorization. A diffusion guider is designed to incorporate the pre-trained weights of the latent diffusion model to output a latent color prior that conforms to the visual semantics of the grayscale input. A lightness-aware VQVAE will then generate the colorized result with pixel-perfect alignment to the given grayscale image. Our model can also achieve conditional colorization with additional inputs (e.g. user hints and texts). Extensive experiments show that our method achieves state-of-the-art performance in terms of perceptual quality.
Screentone-Preserved Manga Retargeting
Mar 07, 2022


As a popular comic style, manga offers a unique impression by utilizing a rich set of bitonal patterns, or screentones, for illustration. However, screentones can easily be contaminated with visual-unpleasant aliasing and/or blurriness after resampling, which harms its visualization on displays of diverse resolutions. To address this problem, we propose the first manga retargeting method that synthesizes a rescaled manga image while retaining the screentone in each screened region. This is a non-trivial task as accurate region-wise segmentation remains challenging. Fortunately, the rescaled manga shares the same region-wise screentone correspondences with the original manga, which enables us to simplify the screentone synthesis problem as an anchor-based proposals selection and rearrangement problem. Specifically, we design a novel manga sampling strategy to generate aliasing-free screentone proposals, based on hierarchical grid-based anchors that connect the correspondences between the original and the target rescaled manga. Furthermore, a Recurrent Proposal Selection Module (RPSM) is proposed to adaptively integrate these proposals for target screentone synthesis. Besides, to deal with the translation insensitivity nature of screentones, we propose a translation-invariant screentone loss to facilitate the training convergence. Extensive qualitative and quantitative experiments are conducted to verify the effectiveness of our method, and notably compelling results are achieved compared to existing alternative techniques.
Exploiting Aliasing for Manga Restoration
May 14, 2021

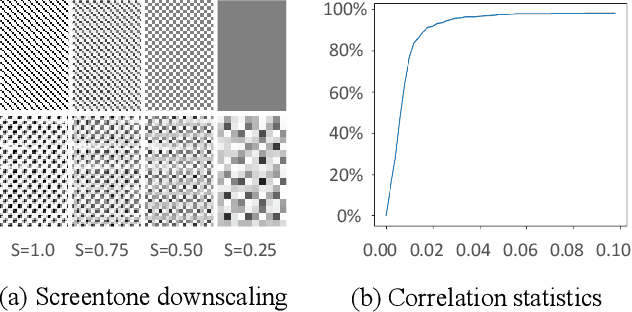

As a popular entertainment art form, manga enriches the line drawings details with bitonal screentones. However, manga resources over the Internet usually show screentone artifacts because of inappropriate scanning/rescaling resolution. In this paper, we propose an innovative two-stage method to restore quality bitonal manga from degraded ones. Our key observation is that the aliasing induced by downsampling bitonal screentones can be utilized as informative clues to infer the original resolution and screentones. First, we predict the target resolution from the degraded manga via the Scale Estimation Network (SE-Net) with spatial voting scheme. Then, at the target resolution, we restore the region-wise bitonal screentones via the Manga Restoration Network (MR-Net) discriminatively, depending on the degradation degree. Specifically, the original screentones are directly restored in pattern-identifiable regions, and visually plausible screentones are synthesized in pattern-agnostic regions. Quantitative evaluation on synthetic data and visual assessment on real-world cases illustrate the effectiveness of our method.
Realistic face animation generation from videos
Mar 27, 20213D face reconstruction and face alignment are two fundamental and highly related topics in computer vision. Recently, some works start to use deep learning models to estimate the 3DMM coefficients to reconstruct 3D face geometry. However, the performance is restricted due to the limitation of the pre-defined face templates. To address this problem, some end-to-end methods, which can completely bypass the calculation of 3DMM coefficients, are proposed and attract much attention. In this report, we introduce and analyse three state-of-the-art methods in 3D face reconstruction and face alignment. Some potential improvement on PRN are proposed to further enhance its accuracy and speed.
A Learned Compact and Editable Light Field Representation
Mar 21, 2021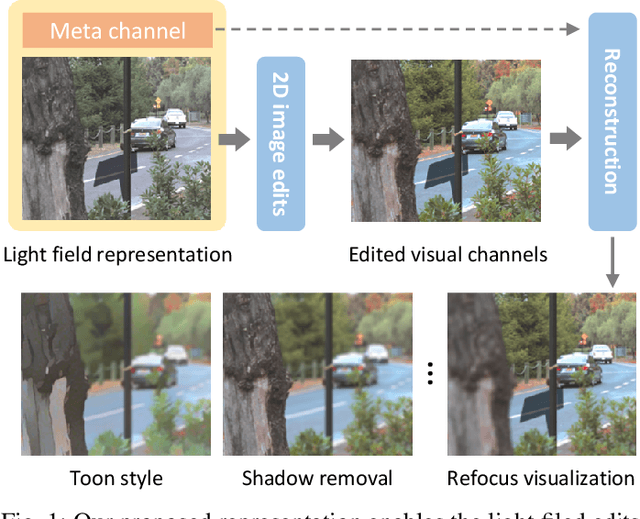



Light fields are 4D scene representation typically structured as arrays of views, or several directional samples per pixel in a single view. This highly correlated structure is not very efficient to transmit and manipulate (especially for editing), though. To tackle these problems, we present a novel compact and editable light field representation, consisting of a set of visual channels (i.e. the central RGB view) and a complementary meta channel that encodes the residual geometric and appearance information. The visual channels in this representation can be edited using existing 2D image editing tools, before accurately reconstructing the whole edited light field back. We propose to learn this representation via an autoencoder framework, consisting of an encoder for learning the representation, and a decoder for reconstructing the light field. To handle the challenging occlusions and propagation of edits, we specifically designed an editing-aware decoding network and its associated training strategy, so that the edits to the visual channels can be consistently propagated to the whole light field upon reconstruction.Experimental results show that our proposed method outperforms related existing methods in reconstruction accuracy, and achieves visually pleasant performance in editing propagation.