 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee-through: Single-image Layer Decomposition for Anime Characters
Feb 03, 2026We introduce a framework that automates the transformation of static anime illustrations into manipulatable 2.5D models. Current professional workflows require tedious manual segmentation and the artistic ``hallucination'' of occluded regions to enable motion. Our approach overcomes this by decomposing a single image into fully inpainted, semantically distinct layers with inferred drawing orders. To address the scarcity of training data, we introduce a scalable engine that bootstraps high-quality supervision from commercial Live2D models, capturing pixel-perfect semantics and hidden geometry. Our methodology couples a diffusion-based Body Part Consistency Module, which enforces global geometric coherence, with a pixel-level pseudo-depth inference mechanism. This combination resolves the intricate stratification of anime characters, e.g., interleaving hair strands, allowing for dynamic layer reconstruction. We demonstrate that our approach yields high-fidelity, manipulatable models suitable for professional, real-time animation applications.
What Do Agents Learn from Trajectory-SFT: Semantics or Interfaces?
Feb 02, 2026Large language models are increasingly evaluated as interactive agents, yet standard agent benchmarks conflate two qualitatively distinct sources of success: semantic tool-use and interface-specific interaction pattern memorization. Because both mechanisms can yield identical task success on the original interface, benchmark scores alone are not identifiable evidence of environment-invariant capability. We propose PIPE, a protocol-level evaluation augmentation for diagnosing interface reliance by minimally rewriting environment interfaces while preserving task semantics and execution behavior. Across 16 environments from AgentBench and AgentGym and a range of open-source and API-based agents, PIPE reveals that trajectory-SFT substantially amplifies interface shortcutting: trained agents degrade sharply under minimal interface rewrites, while non-trajectory-trained models remain largely stable. We further introduce Interface Reliance (IR), a counterbalanced alias-based metric that quantifies preference for training-time interfaces, and show that interface shortcutting exhibits environment-dependent, non-monotonic training dynamics that remain invisible under standard evaluation. Our code is available at https://anonymous.4open.science/r/What-Do-Agents-Learn-from-Trajectory-SFT-Semantics-or-Interfaces--0831/.
FeatBench: Evaluating Coding Agents on Feature Implementation for Vibe Coding
Sep 26, 2025The rapid advancement of Large Language Models (LLMs) has given rise to a novel software development paradigm known as "vibe coding," where users interact with coding agents through high-level natural language. However, existing evaluation benchmarks for code generation inadequately assess an agent's vibe coding capabilities. Existing benchmarks are misaligned, as they either require code-level specifications or focus narrowly on issue-solving, neglecting the critical scenario of feature implementation within the vibe coding paradiam. To address this gap, we propose FeatBench, a novel benchmark for vibe coding that focuses on feature implementation. Our benchmark is distinguished by several key features: 1. Pure Natural Language Prompts. Task inputs consist solely of abstract natural language descriptions, devoid of any code or structural hints. 2. A Rigorous & Evolving Data Collection Process. FeatBench is built on a multi-level filtering pipeline to ensure quality and a fully automated pipeline to evolve the benchmark, mitigating data contamination. 3. Comprehensive Test Cases. Each task includes Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests to verify correctness and prevent regressions. 4. Diverse Application Domains. The benchmark includes repositories from diverse domains to ensure it reflects real-world scenarios. We evaluate two state-of-the-art agent frameworks with four leading LLMs on FeatBench. Our evaluation reveals that feature implementation within the vibe coding paradigm is a significant challenge, with the highest success rate of only 29.94%. Our analysis also reveals a tendency for "aggressive implementation," a strategy that paradoxically leads to both critical failures and superior software design. We release FeatBench, our automated collection pipeline, and all experimental results to facilitate further community research.
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
Apr 15, 2025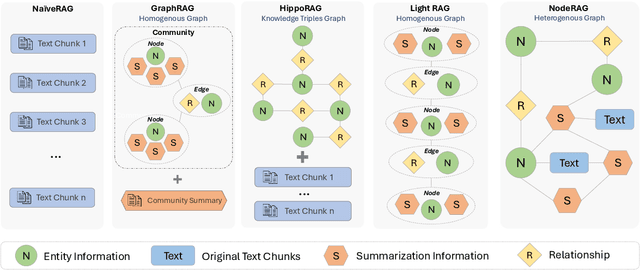
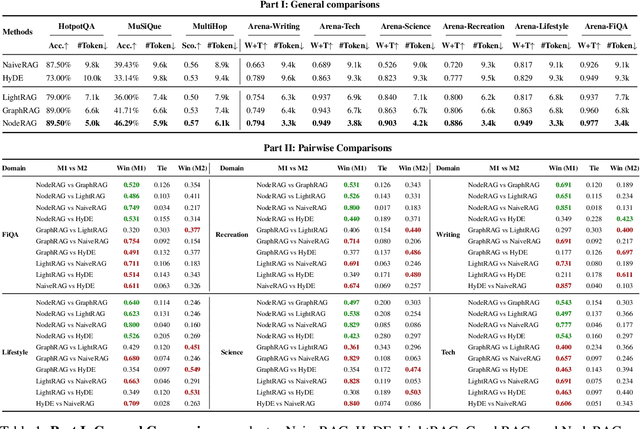
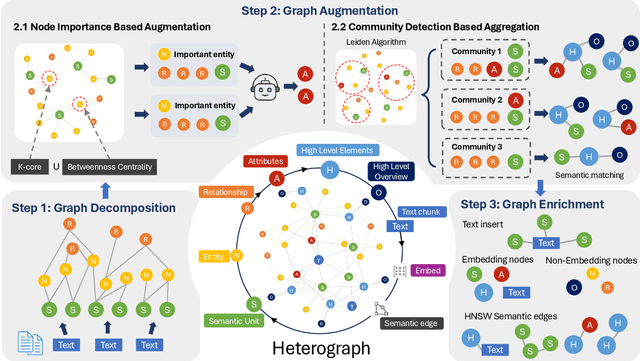
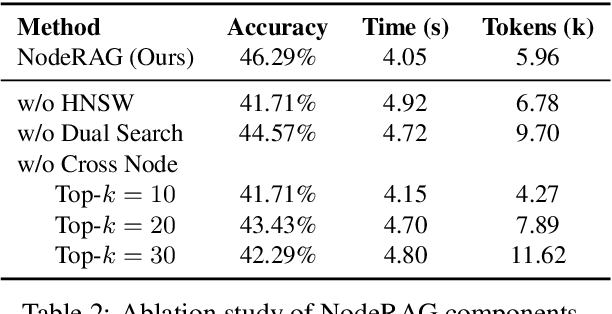
Retrieval-augmented generation (RAG) empowers large language models to access external and private corpus, enabling factually consistent responses in specific domains. By exploiting the inherent structure of the corpus, graph-based RAG methods further enrich this process by building a knowledge graph index and leveraging the structural nature of graphs. However, current graph-based RAG approaches seldom prioritize the design of graph structures. Inadequately designed graph not only impede the seamless integration of diverse graph algorithms but also result in workflow inconsistencies and degraded performance. To further unleash the potential of graph for RAG, we propose NodeRAG, a graph-centric framework introducing heterogeneous graph structures that enable the seamless and holistic integration of graph-based methodologies into the RAG workflow. By aligning closely with the capabilities of LLMs, this framework ensures a fully cohesive and efficient end-to-end process. Through extensive experiments, we demonstrate that NodeRAG exhibits performance advantages over previous methods, including GraphRAG and LightRAG, not only in indexing time, query time, and storage efficiency but also in delivering superior question-answering performance on multi-hop benchmarks and open-ended head-to-head evaluations with minimal retrieval tokens. Our GitHub repository could be seen at https://github.com/Terry-Xu-666/NodeRAG.
Hyperstroke: A Novel High-quality Stroke Representation for Assistive Artistic Drawing
Aug 18, 2024Assistive drawing aims to facilitate the creative process by providing intelligent guidance to artists. Existing solutions often fail to effectively model intricate stroke details or adequately address the temporal aspects of drawing. We introduce hyperstroke, a novel stroke representation designed to capture precise fine stroke details, including RGB appearance and alpha-channel opacity. Using a Vector Quantization approach, hyperstroke learns compact tokenized representations of strokes from real-life drawing videos of artistic drawing. With hyperstroke, we propose to model assistive drawing via a transformer-based architecture, to enable intuitive and user-friendly drawing applications, which are experimented in our exploratory evaluation.
Sketch2Manga: Shaded Manga Screening from Sketch with Diffusion Models
Mar 13, 2024While manga is a popular entertainment form, creating manga is tedious, especially adding screentones to the created sketch, namely manga screening. Unfortunately, there is no existing method that tailors for automatic manga screening, probably due to the difficulty of generating high-quality shaded high-frequency screentones. The classic manga screening approaches generally require user input to provide screentone exemplars or a reference manga image. The recent deep learning models enables the automatic generation by learning from a large-scale dataset. However, the state-of-the-art models still fail to generate high-quality shaded screentones due to the lack of a tailored model and high-quality manga training data. In this paper, we propose a novel sketch-to-manga framework that first generates a color illustration from the sketch and then generates a screentoned manga based on the intensity guidance. Our method significantly outperforms existing methods in generating high-quality manga with shaded high-frequency screentones.
Instance-guided Cartoon Editing with a Large-scale Dataset
Dec 04, 2023Cartoon editing, appreciated by both professional illustrators and hobbyists, allows extensive creative freedom and the development of original narratives within the cartoon domain. However, the existing literature on cartoon editing is complex and leans heavily on manual operations, owing to the challenge of automatic identification of individual character instances. Therefore, an automated segmentation of these elements becomes imperative to facilitate a variety of cartoon editing applications such as visual style editing, motion decomposition and transfer, and the computation of stereoscopic depths for an enriched visual experience. Unfortunately, most current segmentation methods are designed for natural photographs, failing to recognize from the intricate aesthetics of cartoon subjects, thus lowering segmentation quality. The major challenge stems from two key shortcomings: the rarity of high-quality cartoon dedicated datasets and the absence of competent models for high-resolution instance extraction on cartoons. To address this, we introduce a high-quality dataset of over 100k paired high-resolution cartoon images and their instance labeling masks. We also present an instance-aware image segmentation model that can generate accurate, high-resolution segmentation masks for characters in cartoon images. We present that the proposed approach enables a range of segmentation-dependent cartoon editing applications like 3D Ken Burns parallax effects, text-guided cartoon style editing, and puppet animation from illustrations and manga.
Highly Detailed and Temporal Consistent Video Stylization via Synchronized Multi-Frame Diffusion
Nov 24, 2023



Text-guided video-to-video stylization transforms the visual appearance of a source video to a different appearance guided on textual prompts. Existing text-guided image diffusion models can be extended for stylized video synthesis. However, they struggle to generate videos with both highly detailed appearance and temporal consistency. In this paper, we propose a synchronized multi-frame diffusion framework to maintain both the visual details and the temporal consistency. Frames are denoised in a synchronous fashion, and more importantly, information of different frames is shared since the beginning of the denoising process. Such information sharing ensures that a consensus, in terms of the overall structure and color distribution, among frames can be reached in the early stage of the denoising process before it is too late. The optical flow from the original video serves as the connection, and hence the venue for information sharing, among frames. We demonstrate the effectiveness of our method in generating high-quality and diverse results in extensive experiments. Our method shows superior qualitative and quantitative results compared to state-of-the-art video editing methods.
Manga Rescreening with Interpretable Screentone Representation
Jun 07, 2023The process of adapting or repurposing manga pages is a time-consuming task that requires manga artists to manually work on every single screentone region and apply new patterns to create novel screentones across multiple panels. To address this issue, we propose an automatic manga rescreening pipeline that aims to minimize the human effort involved in manga adaptation. Our pipeline automatically recognizes screentone regions and generates novel screentones with newly specified characteristics (e.g., intensity or type). Existing manga generation methods have limitations in understanding and synthesizing complex tone- or intensity-varying regions. To overcome these limitations, we propose a novel interpretable representation of screentones that disentangles their intensity and type features, enabling better recognition and synthesis of screentones. This interpretable screentone representation reduces ambiguity in recognizing intensity-varying regions and provides fine-grained controls during screentone synthesis by decoupling and anchoring the type or the intensity feature. Our proposed method is demonstrated to be effective and convenient through various experiments, showcasing the superiority of the newly proposed pipeline with the interpretable screentone representations.
Video Colorization with Pre-trained Text-to-Image Diffusion Models
Jun 02, 2023
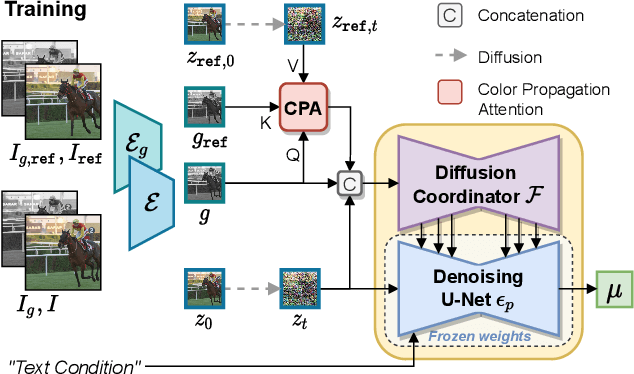


Video colorization is a challenging task that involves inferring plausible and temporally consistent colors for grayscale frames. In this paper, we present ColorDiffuser, an adaptation of a pre-trained text-to-image latent diffusion model for video colorization. With the proposed adapter-based approach, we repropose the pre-trained text-to-image model to accept input grayscale video frames, with the optional text description, for video colorization. To enhance the temporal coherence and maintain the vividness of colorization across frames, we propose two novel techniques: the Color Propagation Attention and Alternated Sampling Strategy. Color Propagation Attention enables the model to refine its colorization decision based on a reference latent frame, while Alternated Sampling Strategy captures spatiotemporal dependencies by using the next and previous adjacent latent frames alternatively as reference during the generative diffusion sampling steps. This encourages bidirectional color information propagation between adjacent video frames, leading to improved color consistency across frames. We conduct extensive experiments on benchmark datasets, and the results demonstrate the effectiveness of our proposed framework. The evaluations show that ColorDiffuser achieves state-of-the-art performance in video colorization, surpassing existing methods in terms of color fidelity, temporal consistency, and visual quality.