 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Doc: Benchmarking Document Image Quality Assessment Capabilities in Multi-modal Large Language Models
Nov 14, 2025The rapid advancement of Multi-modal Large Language Models (MLLMs) has expanded their capabilities beyond high-level vision tasks. Nevertheless, their potential for Document Image Quality Assessment (DIQA) remains underexplored. To bridge this gap, we propose Q-Doc, a three-tiered evaluation framework for systematically probing DIQA capabilities of MLLMs at coarse, middle, and fine granularity levels. a) At the coarse level, we instruct MLLMs to assign quality scores to document images and analyze their correlation with Quality Annotations. b) At the middle level, we design distortion-type identification tasks, including single-choice and multi-choice tests for multi-distortion scenarios. c) At the fine level, we introduce distortion-severity assessment where MLLMs classify distortion intensity against human-annotated references. Our evaluation demonstrates that while MLLMs possess nascent DIQA abilities, they exhibit critical limitations: inconsistent scoring, distortion misidentification, and severity misjudgment. Significantly, we show that Chain-of-Thought (CoT) prompting substantially enhances performance across all levels. Our work provides a benchmark for DIQA capabilities in MLLMs, revealing pronounced deficiencies in their quality perception and promising pathways for enhancement. The benchmark and code are publicly available at: https://github.com/cydxf/Q-Doc.
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
Jul 01, 2021

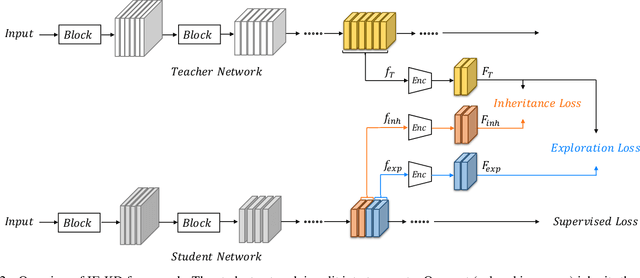

Knowledge Distillation (KD) is a popular technique to transfer knowledge from a teacher model or ensemble to a student model. Its success is generally attributed to the privileged information on similarities/consistency between the class distributions or intermediate feature representations of the teacher model and the student model. However, directly pushing the student model to mimic the probabilities/features of the teacher model to a large extent limits the student model in learning undiscovered knowledge/features. In this paper, we propose a novel inheritance and exploration knowledge distillation framework (IE-KD), in which a student model is split into two parts - inheritance and exploration. The inheritance part is learned with a similarity loss to transfer the existing learned knowledge from the teacher model to the student model, while the exploration part is encouraged to learn representations different from the inherited ones with a dis-similarity loss. Our IE-KD framework is generic and can be easily combined with existing distillation or mutual learning methods for training deep neural networks. Extensive experiments demonstrate that these two parts can jointly push the student model to learn more diversified and effective representations, and our IE-KD can be a general technique to improve the student network to achieve SOTA performance. Furthermore, by applying our IE-KD to the training of two networks, the performance of both can be improved w.r.t. deep mutual learning. The code and models of IE-KD will be make publicly available at https://github.com/yellowtownhz/IE-KD.
Learning Formation of Physically-Based Face Attributes
Apr 24, 2020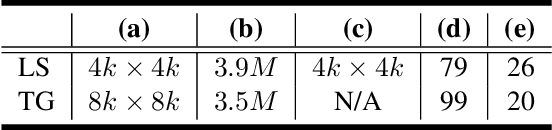

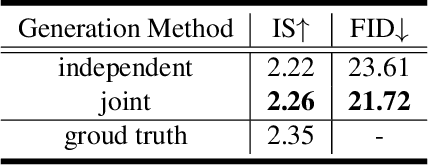
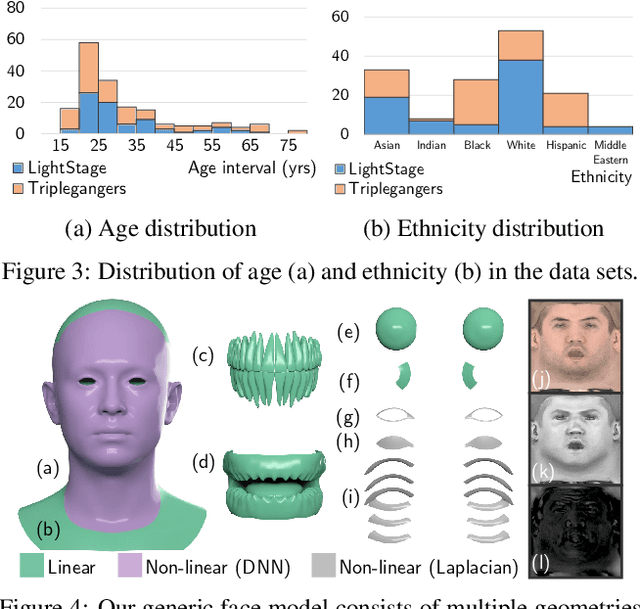
Based on a combined data set of 4000 high resolution facial scans, we introduce a non-linear morphable face model, capable of producing multifarious face geometry of pore-level resolution, coupled with material attributes for use in physically-based rendering. We aim to maximize the variety of face identities, while increasing the robustness of correspondence between unique components, including middle-frequency geometry, albedo maps, specular intensity maps and high-frequency displacement details. Our deep learning based generative model learns to correlate albedo and geometry, which ensures the anatomical correctness of the generated assets. We demonstrate potential use of our generative model for novel identity generation, model fitting, interpolation, animation, high fidelity data visualization, and low-to-high resolution data domain transferring. We hope the release of this generative model will encourage further cooperation between all graphics, vision, and data focused professionals while demonstrating the cumulative value of every individual's complete biometric profile.
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Apr 15, 2020
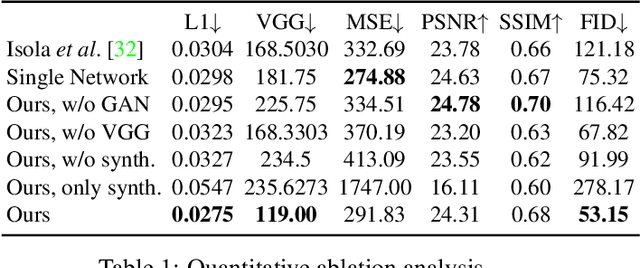
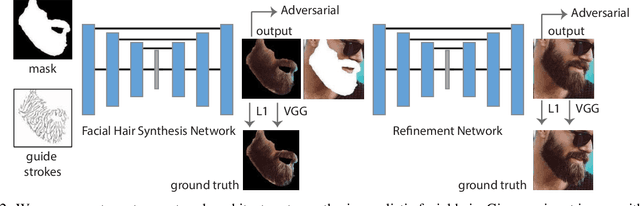

We present an interactive approach to synthesizing realistic variations in facial hair in images, ranging from subtle edits to existing hair to the addition of complex and challenging hair in images of clean-shaven subjects. To circumvent the tedious and computationally expensive tasks of modeling, rendering and compositing the 3D geometry of the target hairstyle using the traditional graphics pipeline, we employ a neural network pipeline that synthesizes realistic and detailed images of facial hair directly in the target image in under one second. The synthesis is controlled by simple and sparse guide strokes from the user defining the general structural and color properties of the target hairstyle. We qualitatively and quantitatively evaluate our chosen method compared to several alternative approaches. We show compelling interactive editing results with a prototype user interface that allows novice users to progressively refine the generated image to match their desired hairstyle, and demonstrate that our approach also allows for flexible and high-fidelity scalp hair synthesis.
Quantization Networks
Nov 28, 2019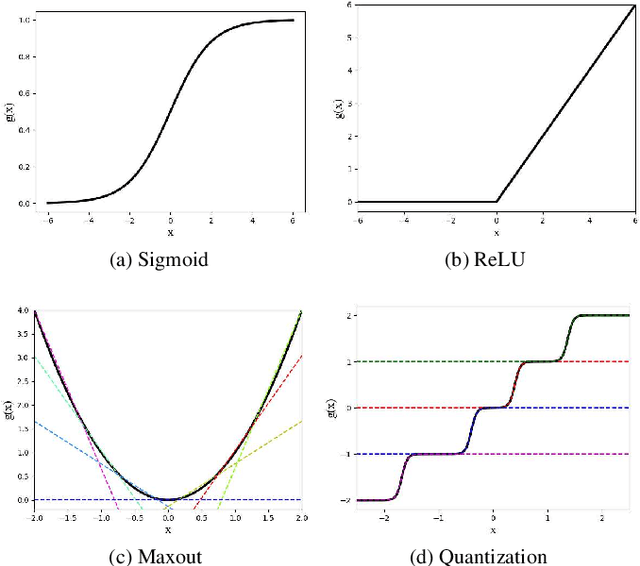
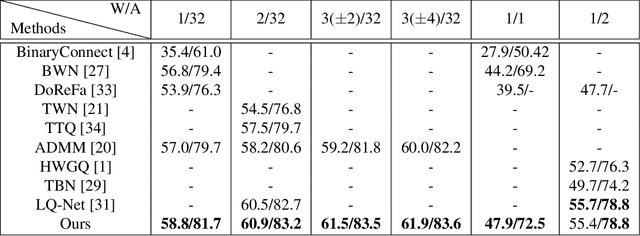


Although deep neural networks are highly effective, their high computational and memory costs severely challenge their applications on portable devices. As a consequence, low-bit quantization, which converts a full-precision neural network into a low-bitwidth integer version, has been an active and promising research topic. Existing methods formulate the low-bit quantization of networks as an approximation or optimization problem. Approximation-based methods confront the gradient mismatch problem, while optimization-based methods are only suitable for quantizing weights and could introduce high computational cost in the training stage. In this paper, we propose a novel perspective of interpreting and implementing neural network quantization by formulating low-bit quantization as a differentiable non-linear function (termed quantization function). The proposed quantization function can be learned in a lossless and end-to-end manner and works for any weights and activations of neural networks in a simple and uniform way. Extensive experiments on image classification and object detection tasks show that our quantization networks outperform the state-of-the-art methods. We believe that the proposed method will shed new insights on the interpretation of neural network quantization. Our code is available at https://github.com/aliyun/alibabacloud-quantization-networks.
Learning Perspective Undistortion of Portraits
May 18, 2019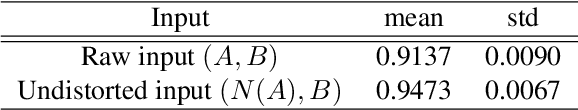



Near-range portrait photographs often contain perspective distortion artifacts that bias human perception and challenge both facial recognition and reconstruction techniques. We present the first deep learning based approach to remove such artifacts from unconstrained portraits. In contrast to the previous state-of-the-art approach, our method handles even portraits with extreme perspective distortion, as we avoid the inaccurate and error-prone step of first fitting a 3D face model. Instead, we predict a distortion correction flow map that encodes a per-pixel displacement that removes distortion artifacts when applied to the input image. Our method also automatically infers missing facial features, i.e. occluded ears caused by strong perspective distortion, with coherent details. We demonstrate that our approach significantly outperforms the previous state-of-the-art both qualitatively and quantitatively, particularly for portraits with extreme perspective distortion or facial expressions. We further show that our technique benefits a number of fundamental tasks, significantly improving the accuracy of both face recognition and 3D reconstruction and enables a novel camera calibration technique from a single portrait. Moreover, we also build the first perspective portrait database with a large diversity in identities, expression and poses, which will benefit the related research in this area.
Deep RBFNet: Point Cloud Feature Learning using Radial Basis Functions
Dec 11, 2018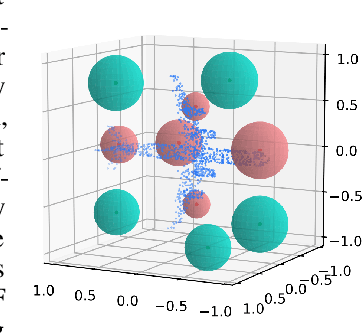
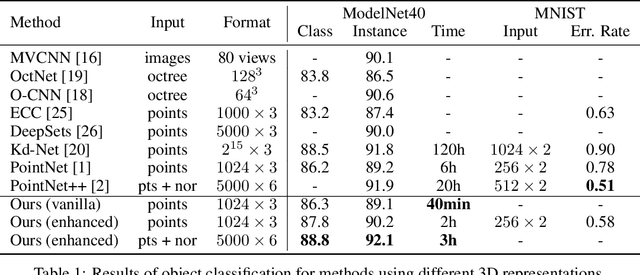
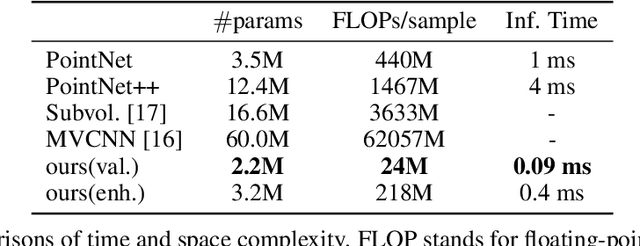
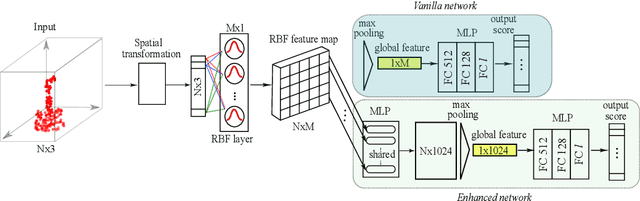
Three-dimensional object recognition has recently achieved great progress thanks to the development of effective point cloud-based learning frameworks, such as PointNet and its extensions. However, existing methods rely heavily on fully connected layers, which introduce a significant amount of parameters, making the network harder to train and prone to overfitting problems. In this paper, we propose a simple yet effective framework for point set feature learning by leveraging a nonlinear activation layer encoded by Radial Basis Function (RBF) kernels. Unlike PointNet variants, that fail to recognize local point patterns, our approach explicitly models the spatial distribution of point clouds by aggregating features from sparsely distributed RBF kernels. A typical RBF kernel, e.g. Gaussian function, naturally penalizes long-distance response and is only activated by neighboring points. Such localized response generates highly discriminative features given different point distributions. In addition, our framework allows the joint optimization of kernel distribution and its receptive field, automatically evolving kernel configurations in an end-to-end manner. We demonstrate that the proposed network with a single RBF layer can outperform the state-of-the-art Pointnet++ in terms of classification accuracy for 3D object recognition tasks. Moreover, the introduction of nonlinear mappings significantly reduces the number of network parameters and computational cost, enabling significantly faster training and a deployable point cloud recognition solution on portable devices with limited resources.
Identity Preserving Face Completion for Large Ocular Region Occlusion
Jul 23, 2018

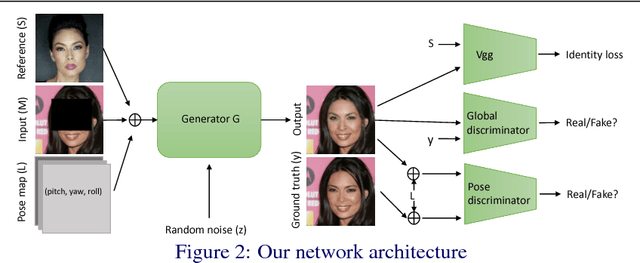

We present a novel deep learning approach to synthesize complete face images in the presence of large ocular region occlusions. This is motivated by recent surge of VR/AR displays that hinder face-to-face communications. Different from the state-of-the-art face inpainting methods that have no control over the synthesized content and can only handle frontal face pose, our approach can faithfully recover the missing content under various head poses while preserving the identity. At the core of our method is a novel generative network with dedicated constraints to regularize the synthesis process. To preserve the identity, our network takes an arbitrary occlusion-free image of the target identity to infer the missing content, and its high-level CNN features as an identity prior to regularize the searching space of generator. Since the input reference image may have a different pose, a pose map and a novel pose discriminator are further adopted to supervise the learning of implicit pose transformations. Our method is capable of generating coherent facial inpainting with consistent identity over videos with large variations of head motions. Experiments on both synthesized and real data demonstrate that our method greatly outperforms the state-of-the-art methods in terms of both synthesis quality and robustness.
* 12 pages,9 figures