 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Lyra 2.0: Explorable Generative 3D Worlds
Apr 14, 2026Recent advances in video generation enable a new paradigm for 3D scene creation: generating camera-controlled videos that simulate scene walkthroughs, then lifting them to 3D via feed-forward reconstruction techniques. This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs ready for real-time rendering and simulation. Scaling to large, complex environments requires 3D-consistent video generation over long camera trajectories with large viewpoint changes and location revisits, a setting where current video models degrade quickly. Existing methods for long-horizon generation are fundamentally limited by two forms of degradation: spatial forgetting and temporal drifting. As exploration proceeds, previously observed regions fall outside the model's temporal context, forcing the model to hallucinate structures when revisited. Meanwhile, autoregressive generation accumulates small synthesis errors over time, gradually distorting scene appearance and geometry. We present Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale. To address spatial forgetting, we maintain per-frame 3D geometry and use it solely for information routing -- retrieving relevant past frames and establishing dense correspondences with the target viewpoints -- while relying on the generative prior for appearance synthesis. To address temporal drifting, we train with self-augmented histories that expose the model to its own degraded outputs, teaching it to correct drift rather than propagate it. Together, these enable substantially longer and 3D-consistent video trajectories, which we leverage to fine-tune feed-forward reconstruction models that reliably recover high-quality 3D scenes.
VGG-T$^3$: Offline Feed-Forward 3D Reconstruction at Scale
Feb 26, 2026We present a scalable 3D reconstruction model that addresses a critical limitation in offline feed-forward methods: their computational and memory requirements grow quadratically w.r.t. the number of input images. Our approach is built on the key insight that this bottleneck stems from the varying-length Key-Value (KV) space representation of scene geometry, which we distill into a fixed-size Multi-Layer Perceptron (MLP) via test-time training. VGG-T$^3$ (Visual Geometry Grounded Test Time Training) scales linearly w.r.t. the number of input views, similar to online models, and reconstructs a $1k$ image collection in just $54$ seconds, achieving a $11.6\times$ speed-up over baselines that rely on softmax attention. Since our method retains global scene aggregation capability, our point map reconstruction error outperforming other linear-time methods by large margins. Finally, we demonstrate visual localization capabilities of our model by querying the scene representation with unseen images.
Test-Time Training with KV Binding Is Secretly Linear Attention
Feb 24, 2026Test-time training (TTT) with KV binding as sequence modeling layer is commonly interpreted as a form of online meta-learning that memorizes a key-value mapping at test time. However, our analysis reveals multiple phenomena that contradict this memorization-based interpretation. Motivated by these findings, we revisit the formulation of TTT and show that a broad class of TTT architectures can be expressed as a form of learned linear attention operator. Beyond explaining previously puzzling model behaviors, this perspective yields multiple practical benefits: it enables principled architectural simplifications, admits fully parallel formulations that preserve performance while improving efficiency, and provides a systematic reduction of diverse TTT variants to a standard linear attention form. Overall, our results reframe TTT not as test-time memorization, but as learned linear attention with enhanced representational capacity.
3DGS$^2$-TR: Scalable Second-Order Trust-Region Method for 3D Gaussian Splatting
Jan 30, 2026We propose 3DGS$^2$-TR,a second-order optimizer for accelerating the scene training problem in 3D Gaussian Splatting (3DGS). Unlike existing second-order approaches that rely on explicit or dense curvature representations, such as 3DGS-LM (Höllein et al., 2025) or 3DGS2 (Lan et al., 2025), our method approximates curvature using only the diagonal of the Hessian matrix, efficiently via Hutchinson's method. Our approach is fully matrix-free and has the same complexity as ADAM (Kingma, 2024), $O(n)$ in both computation and memory costs. To ensure stable optimization in the presence of strong nonlinearity in the 3DGS rasterization process, we introduce a parameter-wise trust-region technique based on the squared Hellinger distance, regularizing updates to Gaussian parameters. Under identical parameter initialization and without densification, 3DGS$^2$-TR is able to achieve better reconstruction quality on standard datasets, using 50% fewer training iterations compared to ADAM, while incurring less than 1GB of peak GPU memory overhead (17% more than ADAM and 85% less than 3DGS-LM), enabling scalability to very large scenes and potentially to distributed training settings.
gsplat: An Open-Source Library for Gaussian Splatting
Sep 10, 2024gsplat is an open-source library designed for training and developing Gaussian Splatting methods. It features a front-end with Python bindings compatible with the PyTorch library and a back-end with highly optimized CUDA kernels. gsplat offers numerous features that enhance the optimization of Gaussian Splatting models, which include optimization improvements for speed, memory, and convergence times. Experimental results demonstrate that gsplat achieves up to 10% less training time and 4x less memory than the original implementation. Utilized in several research projects, gsplat is actively maintained on GitHub. Source code is available at https://github.com/nerfstudio-project/gsplat under Apache License 2.0. We welcome contributions from the open-source community.
fVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
NeRF-XL: Scaling NeRFs with Multiple GPUs
Apr 24, 2024


We present NeRF-XL, a principled method for distributing Neural Radiance Fields (NeRFs) across multiple GPUs, thus enabling the training and rendering of NeRFs with an arbitrarily large capacity. We begin by revisiting existing multi-GPU approaches, which decompose large scenes into multiple independently trained NeRFs, and identify several fundamental issues with these methods that hinder improvements in reconstruction quality as additional computational resources (GPUs) are used in training. NeRF-XL remedies these issues and enables the training and rendering of NeRFs with an arbitrary number of parameters by simply using more hardware. At the core of our method lies a novel distributed training and rendering formulation, which is mathematically equivalent to the classic single-GPU case and minimizes communication between GPUs. By unlocking NeRFs with arbitrarily large parameter counts, our approach is the first to reveal multi-GPU scaling laws for NeRFs, showing improvements in reconstruction quality with larger parameter counts and speed improvements with more GPUs. We demonstrate the effectiveness of NeRF-XL on a wide variety of datasets, including the largest open-source dataset to date, MatrixCity, containing 258K images covering a 25km^2 city area.
NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection
Jul 27, 2023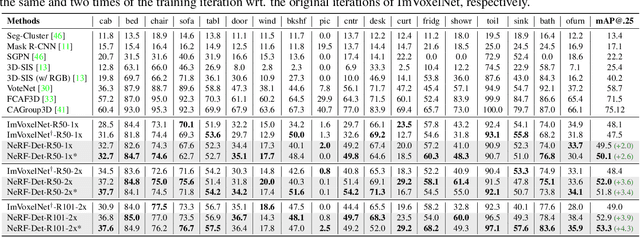
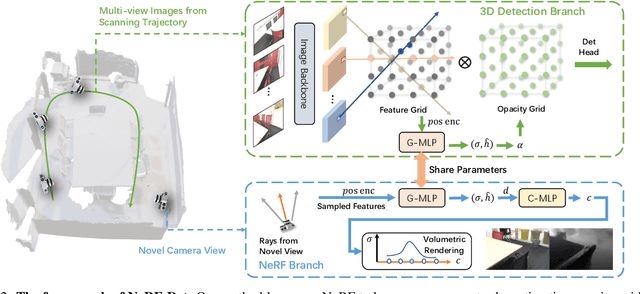
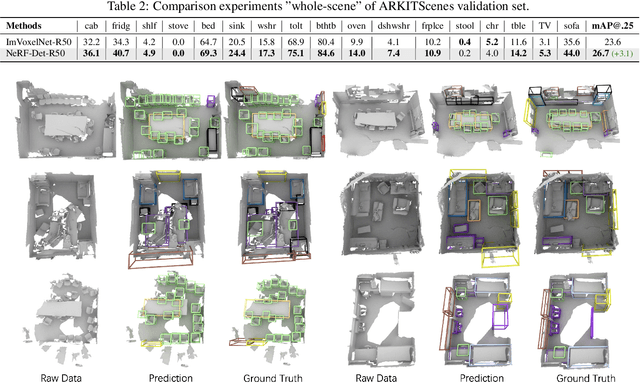
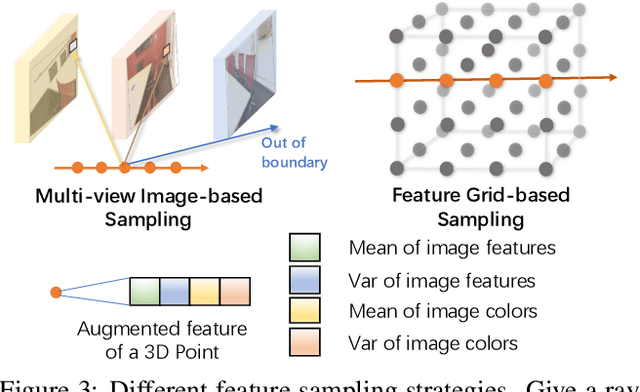
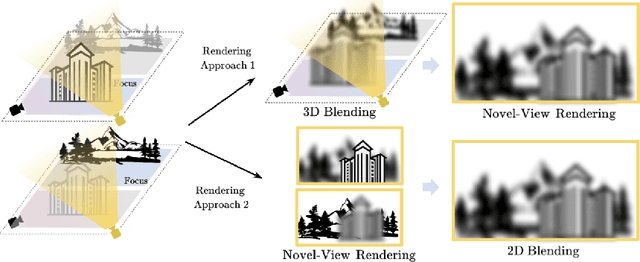
We present NeRF-Det, a novel method for indoor 3D detection with posed RGB images as input. Unlike existing indoor 3D detection methods that struggle to model scene geometry, our method makes novel use of NeRF in an end-to-end manner to explicitly estimate 3D geometry, thereby improving 3D detection performance. Specifically, to avoid the significant extra latency associated with per-scene optimization of NeRF, we introduce sufficient geometry priors to enhance the generalizability of NeRF-MLP. Furthermore, we subtly connect the detection and NeRF branches through a shared MLP, enabling an efficient adaptation of NeRF to detection and yielding geometry-aware volumetric representations for 3D detection. Our method outperforms state-of-the-arts by 3.9 mAP and 3.1 mAP on the ScanNet and ARKITScenes benchmarks, respectively. We provide extensive analysis to shed light on how NeRF-Det works. As a result of our joint-training design, NeRF-Det is able to generalize well to unseen scenes for object detection, view synthesis, and depth estimation tasks without requiring per-scene optimization. Code is available at \url{https://github.com/facebookresearch/NeRF-Det}.
NerfAcc: Efficient Sampling Accelerates NeRFs
May 08, 2023Optimizing and rendering Neural Radiance Fields is computationally expensive due to the vast number of samples required by volume rendering. Recent works have included alternative sampling approaches to help accelerate their methods, however, they are often not the focus of the work. In this paper, we investigate and compare multiple sampling approaches and demonstrate that improved sampling is generally applicable across NeRF variants under an unified concept of transmittance estimator. To facilitate future experiments, we develop NerfAcc, a Python toolbox that provides flexible APIs for incorporating advanced sampling methods into NeRF related methods. We demonstrate its flexibility by showing that it can reduce the training time of several recent NeRF methods by 1.5x to 20x with minimal modifications to the existing codebase. Additionally, highly customized NeRFs, such as Instant-NGP, can be implemented in native PyTorch using NerfAcc.