 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
DirectorLLM for Human-Centric Video Generation
Dec 19, 2024



In this paper, we introduce DirectorLLM, a novel video generation model that employs a large language model (LLM) to orchestrate human poses within videos. As foundational text-to-video models rapidly evolve, the demand for high-quality human motion and interaction grows. To address this need and enhance the authenticity of human motions, we extend the LLM from a text generator to a video director and human motion simulator. Utilizing open-source resources from Llama 3, we train the DirectorLLM to generate detailed instructional signals, such as human poses, to guide video generation. This approach offloads the simulation of human motion from the video generator to the LLM, effectively creating informative outlines for human-centric scenes. These signals are used as conditions by the video renderer, facilitating more realistic and prompt-following video generation. As an independent LLM module, it can be applied to different video renderers, including UNet and DiT, with minimal effort. Experiments on automatic evaluation benchmarks and human evaluations show that our model outperforms existing ones in generating videos with higher human motion fidelity, improved prompt faithfulness, and enhanced rendered subject naturalness.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Pixel-Space Post-Training of Latent Diffusion Models
Sep 26, 2024



Latent diffusion models (LDMs) have made significant advancements in the field of image generation in recent years. One major advantage of LDMs is their ability to operate in a compressed latent space, allowing for more efficient training and deployment. However, despite these advantages, challenges with LDMs still remain. For example, it has been observed that LDMs often generate high-frequency details and complex compositions imperfectly. We hypothesize that one reason for these flaws is due to the fact that all pre- and post-training of LDMs are done in latent space, which is typically $8 \times 8$ lower spatial-resolution than the output images. To address this issue, we propose adding pixel-space supervision in the post-training process to better preserve high-frequency details. Experimentally, we show that adding a pixel-space objective significantly improves both supervised quality fine-tuning and preference-based post-training by a large margin on a state-of-the-art DiT transformer and U-Net diffusion models in both visual quality and visual flaw metrics, while maintaining the same text alignment quality.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023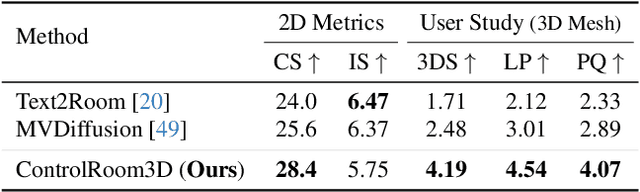
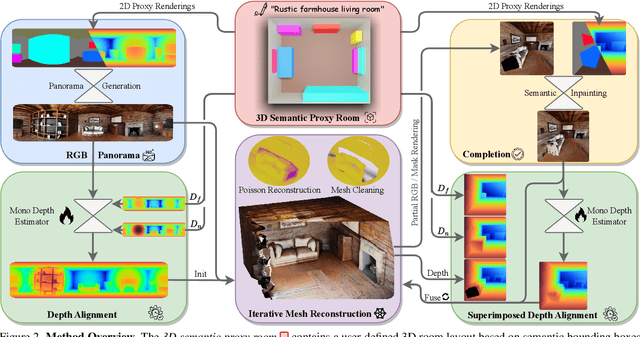
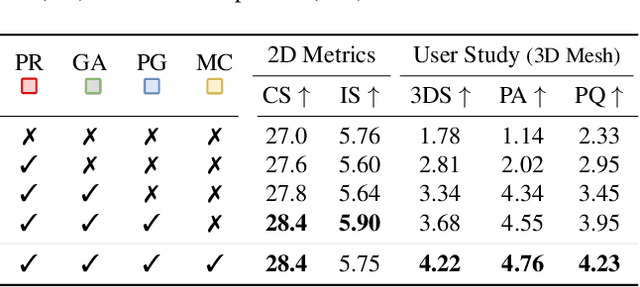
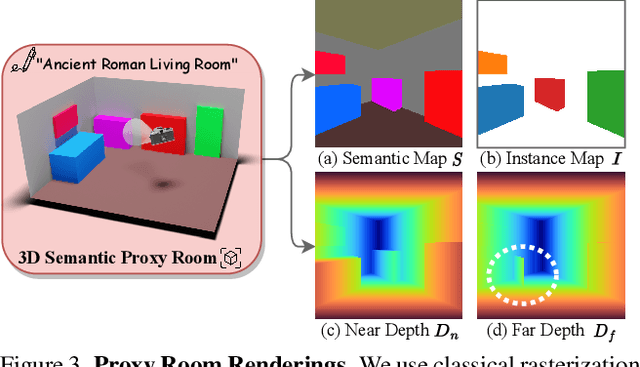
Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023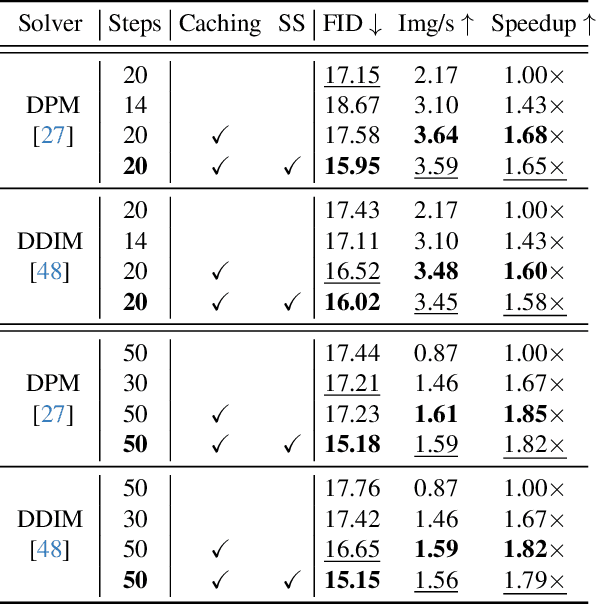

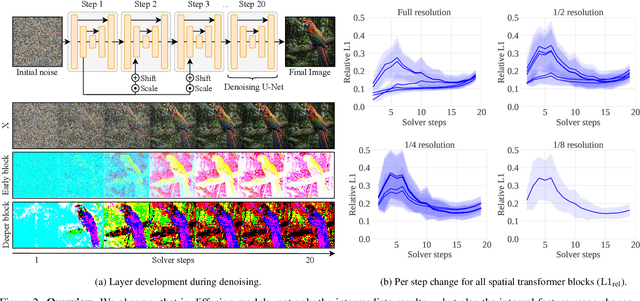
Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023



Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection
Jul 27, 2023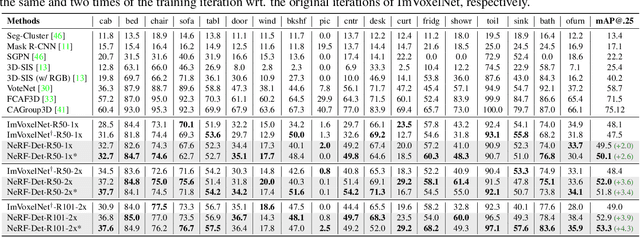
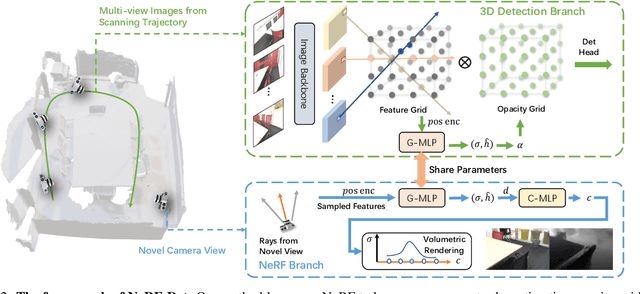
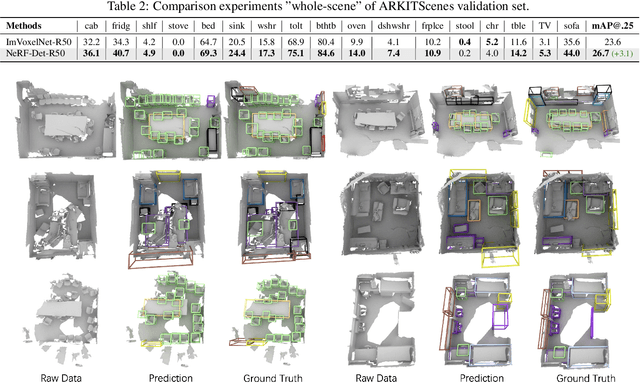
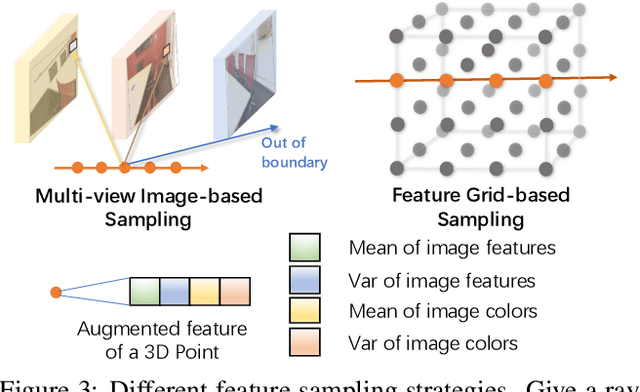
We present NeRF-Det, a novel method for indoor 3D detection with posed RGB images as input. Unlike existing indoor 3D detection methods that struggle to model scene geometry, our method makes novel use of NeRF in an end-to-end manner to explicitly estimate 3D geometry, thereby improving 3D detection performance. Specifically, to avoid the significant extra latency associated with per-scene optimization of NeRF, we introduce sufficient geometry priors to enhance the generalizability of NeRF-MLP. Furthermore, we subtly connect the detection and NeRF branches through a shared MLP, enabling an efficient adaptation of NeRF to detection and yielding geometry-aware volumetric representations for 3D detection. Our method outperforms state-of-the-arts by 3.9 mAP and 3.1 mAP on the ScanNet and ARKITScenes benchmarks, respectively. We provide extensive analysis to shed light on how NeRF-Det works. As a result of our joint-training design, NeRF-Det is able to generalize well to unseen scenes for object detection, view synthesis, and depth estimation tasks without requiring per-scene optimization. Code is available at \url{https://github.com/facebookresearch/NeRF-Det}.
A Practical Stereo Depth System for Smart Glasses
Nov 19, 2022



We present the design of a productionized end-to-end stereo depth sensing system that does pre-processing, online stereo rectification, and stereo depth estimation with a fallback to monocular depth estimation when rectification is unreliable. The output of our depth sensing system is then used in a novel view generation pipeline to create 3D computational photography effect using point-of-view images captured by smart glasses. All these steps are executed on-device on the stringent compute budget of a mobile phone, and because we expect the users can use a wide range of smartphones, our design needs to be general and cannot be dependent on a particular hardware or ML accelerator such as a smartphone GPU. Although each of these steps is well-studied, a description of a practical system is still lacking. For such a system, each of these steps need to work in tandem with one another and fallback gracefully on failures within the system or less than ideal input data. We show how we handle unforeseen changes to calibration, e.g. due to heat, robustly support depth estimation in the wild, and still abide by the memory and latency constraints required for a smooth user experience. We show that our trained models are fast, that run in less than 1s on a six-year-old Samsung Galaxy S8 phone's CPU. Our models generalize well to unseen data and achieve good results on Middlebury and in-the-wild images captured from the smart glasses.
Efficient Segmentation: Learning Downsampling Near Semantic Boundaries
Jul 16, 2019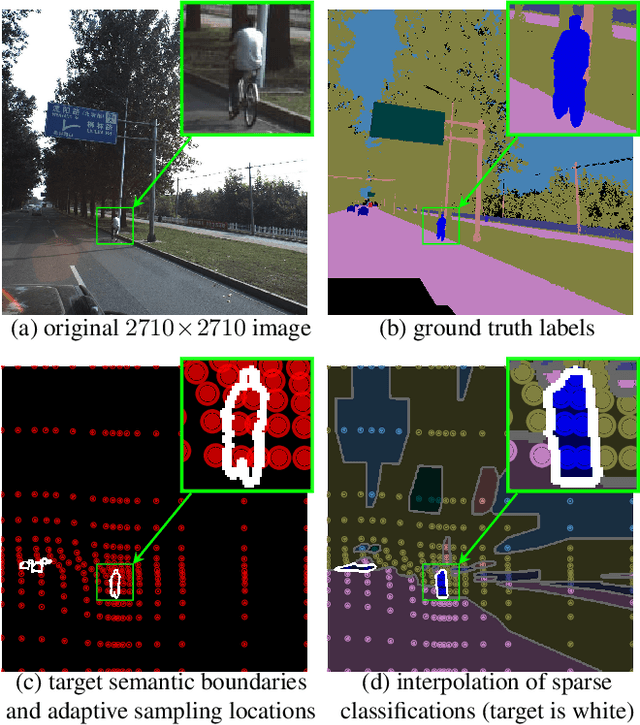
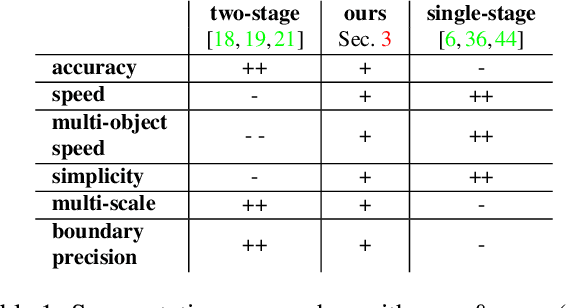
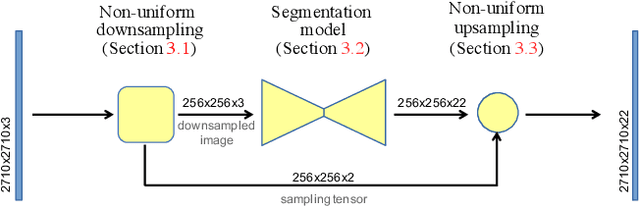
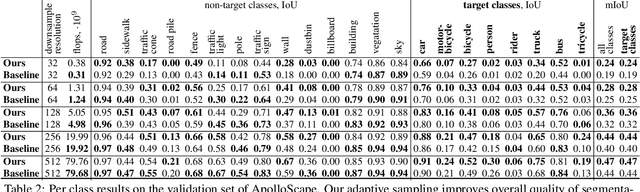
Many automated processes such as auto-piloting rely on a good semantic segmentation as a critical component. To speed up performance, it is common to downsample the input frame. However, this comes at the cost of missed small objects and reduced accuracy at semantic boundaries. To address this problem, we propose a new content-adaptive downsampling technique that learns to favor sampling locations near semantic boundaries of target classes. Cost-performance analysis shows that our method consistently outperforms the uniform sampling improving balance between accuracy and computational efficiency. Our adaptive sampling gives segmentation with better quality of boundaries and more reliable support for smaller-size objects.