 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Distillation of Diffusion Transformers
Apr 15, 2025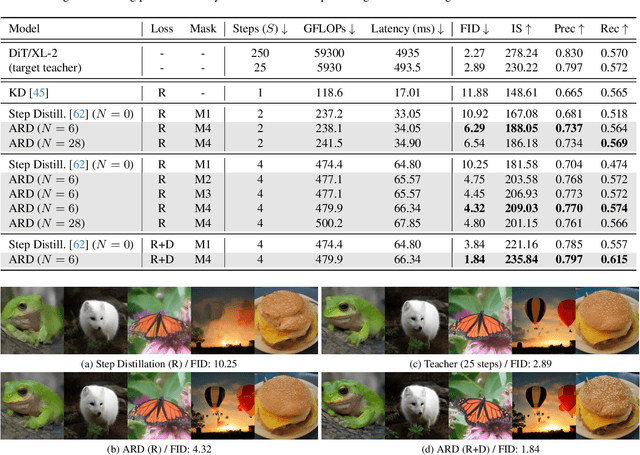
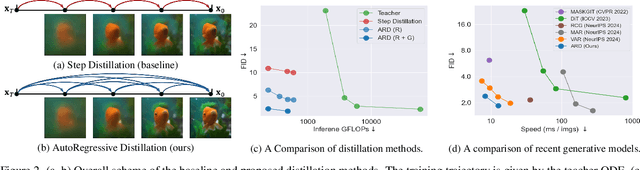
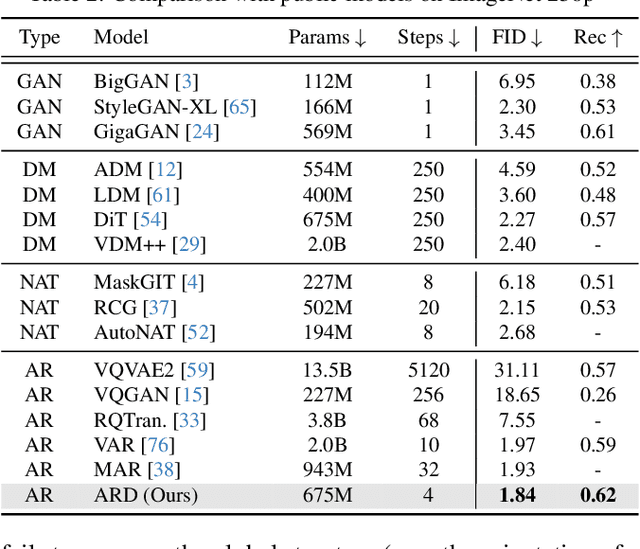
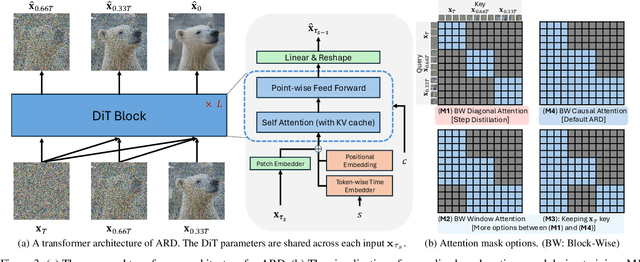
Diffusion models with transformer architectures have demonstrated promising capabilities in generating high-fidelity images and scalability for high resolution. However, iterative sampling process required for synthesis is very resource-intensive. A line of work has focused on distilling solutions to probability flow ODEs into few-step student models. Nevertheless, existing methods have been limited by their reliance on the most recent denoised samples as input, rendering them susceptible to exposure bias. To address this limitation, we propose AutoRegressive Distillation (ARD), a novel approach that leverages the historical trajectory of the ODE to predict future steps. ARD offers two key benefits: 1) it mitigates exposure bias by utilizing a predicted historical trajectory that is less susceptible to accumulated errors, and 2) it leverages the previous history of the ODE trajectory as a more effective source of coarse-grained information. ARD modifies the teacher transformer architecture by adding token-wise time embedding to mark each input from the trajectory history and employs a block-wise causal attention mask for training. Furthermore, incorporating historical inputs only in lower transformer layers enhances performance and efficiency. We validate the effectiveness of ARD in a class-conditioned generation on ImageNet and T2I synthesis. Our model achieves a $5\times$ reduction in FID degradation compared to the baseline methods while requiring only 1.1\% extra FLOPs on ImageNet-256. Moreover, ARD reaches FID of 1.84 on ImageNet-256 in merely 4 steps and outperforms the publicly available 1024p text-to-image distilled models in prompt adherence score with a minimal drop in FID compared to the teacher. Project page: https://github.com/alsdudrla10/ARD.
Storybooth: Training-free Multi-Subject Consistency for Improved Visual Storytelling
Apr 08, 2025Training-free consistent text-to-image generation depicting the same subjects across different images is a topic of widespread recent interest. Existing works in this direction predominantly rely on cross-frame self-attention; which improves subject-consistency by allowing tokens in each frame to pay attention to tokens in other frames during self-attention computation. While useful for single subjects, we find that it struggles when scaling to multiple characters. In this work, we first analyze the reason for these limitations. Our exploration reveals that the primary-issue stems from self-attention-leakage, which is exacerbated when trying to ensure consistency across multiple-characters. This happens when tokens from one subject pay attention to other characters, causing them to appear like each other (e.g., a dog appearing like a duck). Motivated by these findings, we propose StoryBooth: a training-free approach for improving multi-character consistency. In particular, we first leverage multi-modal chain-of-thought reasoning and region-based generation to apriori localize the different subjects across the desired story outputs. The final outputs are then generated using a modified diffusion model which consists of two novel layers: 1) a bounded cross-frame self-attention layer for reducing inter-character attention leakage, and 2) token-merging layer for improving consistency of fine-grain subject details. Through both qualitative and quantitative results we find that the proposed approach surpasses prior state-of-the-art, exhibiting improved consistency across both multiple-characters and fine-grain subject details.
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025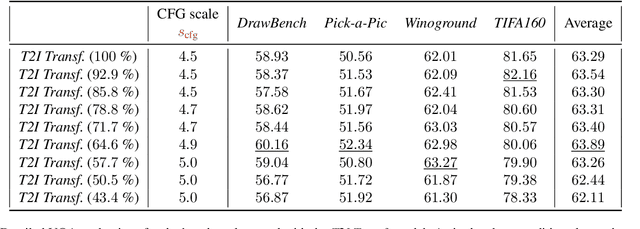


Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
Jan 31, 2025



The performance of large language models (LLMs) is closely linked to their underlying size, leading to ever-growing networks and hence slower inference. Speculative decoding has been proposed as a technique to accelerate autoregressive generation, leveraging a fast draft model to propose candidate tokens, which are then verified in parallel based on their likelihood under the target model. While this approach guarantees to reproduce the target output, it incurs a substantial penalty: many high-quality draft tokens are rejected, even when they represent objectively valid continuations. Indeed, we show that even powerful draft models such as GPT-4o, as well as human text cannot achieve high acceptance rates under the standard verification scheme. This severely limits the speedup potential of current speculative decoding methods, as an early rejection becomes overwhelmingly likely when solely relying on alignment of draft and target. We thus ask the following question: Can we adapt verification to recognize correct, but non-aligned replies? To this end, we draw inspiration from the LLM-as-a-judge framework, which demonstrated that LLMs are able to rate answers in a versatile way. We carefully design a dataset to elicit the same capability in the target model by training a compact module on top of the embeddings to produce ``judgements" of the current continuation. We showcase our strategy on the Llama-3.1 family, where our 8b/405B-Judge achieves a speedup of 9x over Llama-405B, while maintaining its quality on a large range of benchmarks. These benefits remain present even in optimized inference frameworks, where our method reaches up to 141 tokens/s for 8B/70B-Judge and 129 tokens/s for 8B/405B on 2 and 8 H100s respectively.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
May 08, 2024Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable to the teacher model using only three denoising steps, enabling efficient high-quality generation.
fMPI: Fast Novel View Synthesis in the Wild with Layered Scene Representations
Dec 26, 2023



In this study, we propose two novel input processing paradigms for novel view synthesis (NVS) methods based on layered scene representations that significantly improve their runtime without compromising quality. Our approach identifies and mitigates the two most time-consuming aspects of traditional pipelines: building and processing the so-called plane sweep volume (PSV), which is a high-dimensional tensor of planar re-projections of the input camera views. In particular, we propose processing this tensor in parallel groups for improved compute efficiency as well as super-sampling adjacent input planes to generate denser, and hence more accurate scene representation. The proposed enhancements offer significant flexibility, allowing for a balance between performance and speed, thus making substantial steps toward real-time applications. Furthermore, they are very general in the sense that any PSV-based method can make use of them, including methods that employ multiplane images, multisphere images, and layered depth images. In a comprehensive set of experiments, we demonstrate that our proposed paradigms enable the design of an NVS method that achieves state-of-the-art on public benchmarks while being up to $50x$ faster than existing state-of-the-art methods. It also beats the current forerunner in terms of speed by over $3x$, while achieving significantly better rendering quality.
Adaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
Dec 19, 2023This paper presents a comprehensive study on the role of Classifier-Free Guidance (CFG) in text-conditioned diffusion models from the perspective of inference efficiency. In particular, we relax the default choice of applying CFG in all diffusion steps and instead search for efficient guidance policies. We formulate the discovery of such policies in the differentiable Neural Architecture Search framework. Our findings suggest that the denoising steps proposed by CFG become increasingly aligned with simple conditional steps, which renders the extra neural network evaluation of CFG redundant, especially in the second half of the denoising process. Building upon this insight, we propose "Adaptive Guidance" (AG), an efficient variant of CFG, that adaptively omits network evaluations when the denoising process displays convergence. Our experiments demonstrate that AG preserves CFG's image quality while reducing computation by 25%. Thus, AG constitutes a plug-and-play alternative to Guidance Distillation, achieving 50% of the speed-ups of the latter while being training-free and retaining the capacity to handle negative prompts. Finally, we uncover further redundancies of CFG in the first half of the diffusion process, showing that entire neural function evaluations can be replaced by simple affine transformations of past score estimates. This method, termed LinearAG, offers even cheaper inference at the cost of deviating from the baseline model. Our findings provide insights into the efficiency of the conditional denoising process that contribute to more practical and swift deployment of text-conditioned diffusion models.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023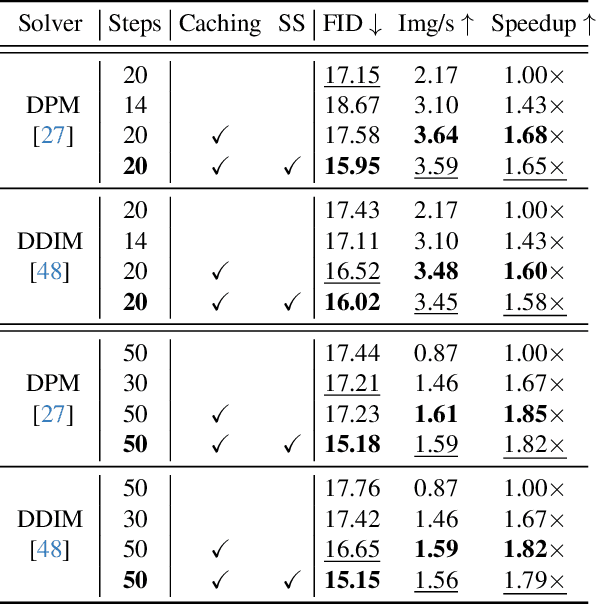

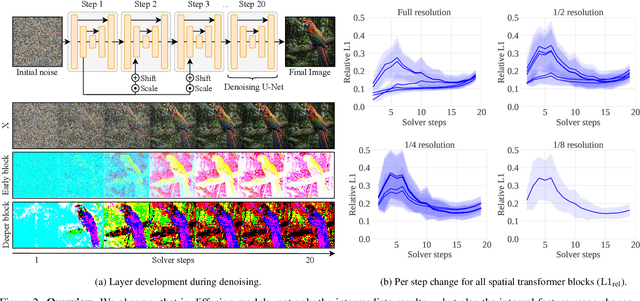
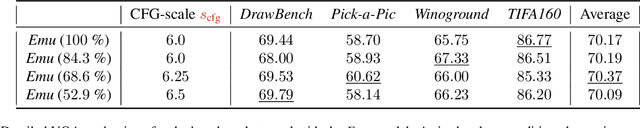
Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
Synthesizing Speech from Intracranial Depth Electrodes using an Encoder-Decoder Framework
Nov 02, 2021
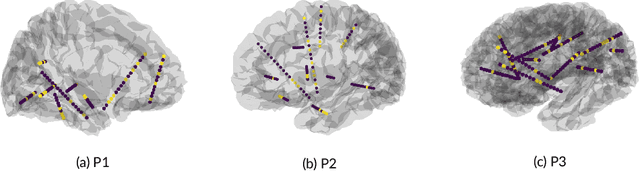
Speech Neuroprostheses have the potential to enable communication for people with dysarthria or anarthria. Recent advances have demonstrated high-quality text decoding and speech synthesis from electrocorticographic grids placed on the cortical surface. Here, we investigate a less invasive measurement modality, namely stereotactic EEG (sEEG) that provides sparse sampling from multiple brain regions, including subcortical regions. To evaluate whether sEEG can also be used to synthesize high-quality audio from neural recordings, we employ a recurrent encoder-decoder framework based on modern deep learning methods. We demonstrate that high-quality speech can be reconstructed from these minimally invasive recordings, despite a limited amount of training data. Finally, we utilize variational feature dropout to successfully identify the most informative electrode contacts.