 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
Dec 19, 2023This paper presents a comprehensive study on the role of Classifier-Free Guidance (CFG) in text-conditioned diffusion models from the perspective of inference efficiency. In particular, we relax the default choice of applying CFG in all diffusion steps and instead search for efficient guidance policies. We formulate the discovery of such policies in the differentiable Neural Architecture Search framework. Our findings suggest that the denoising steps proposed by CFG become increasingly aligned with simple conditional steps, which renders the extra neural network evaluation of CFG redundant, especially in the second half of the denoising process. Building upon this insight, we propose "Adaptive Guidance" (AG), an efficient variant of CFG, that adaptively omits network evaluations when the denoising process displays convergence. Our experiments demonstrate that AG preserves CFG's image quality while reducing computation by 25%. Thus, AG constitutes a plug-and-play alternative to Guidance Distillation, achieving 50% of the speed-ups of the latter while being training-free and retaining the capacity to handle negative prompts. Finally, we uncover further redundancies of CFG in the first half of the diffusion process, showing that entire neural function evaluations can be replaced by simple affine transformations of past score estimates. This method, termed LinearAG, offers even cheaper inference at the cost of deviating from the baseline model. Our findings provide insights into the efficiency of the conditional denoising process that contribute to more practical and swift deployment of text-conditioned diffusion models.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
SEPAL: Spatial Gene Expression Prediction from Local Graphs
Sep 16, 2023



Spatial transcriptomics is an emerging technology that aligns histopathology images with spatially resolved gene expression profiling. It holds the potential for understanding many diseases but faces significant bottlenecks such as specialized equipment and domain expertise. In this work, we present SEPAL, a new model for predicting genetic profiles from visual tissue appearance. Our method exploits the biological biases of the problem by directly supervising relative differences with respect to mean expression, and leverages local visual context at every coordinate to make predictions using a graph neural network. This approach closes the gap between complete locality and complete globality in current methods. In addition, we propose a novel benchmark that aims to better define the task by following current best practices in transcriptomics and restricting the prediction variables to only those with clear spatial patterns. Our extensive evaluation in two different human breast cancer datasets indicates that SEPAL outperforms previous state-of-the-art methods and other mechanisms of including spatial context.
Guarding the Guardians: Automated Analysis of Online Child Sexual Abuse
Aug 10, 2023



Online violence against children has increased globally recently, demanding urgent attention. Competent authorities manually analyze abuse complaints to comprehend crime dynamics and identify patterns. However, the manual analysis of these complaints presents a challenge because it exposes analysts to harmful content during the review process. Given these challenges, we present a novel solution, an automated tool designed to analyze children's sexual abuse reports comprehensively. By automating the analysis process, our tool significantly reduces the risk of exposure to harmful content by categorizing the reports on three dimensions: Subject, Degree of Criminality, and Damage. Furthermore, leveraging our multidisciplinary team's expertise, we introduce a novel approach to annotate the collected data, enabling a more in-depth analysis of the reports. This approach improves the comprehension of fundamental patterns and trends, enabling law enforcement agencies and policymakers to create focused strategies in the fight against children's violence.
BoDiffusion: Diffusing Sparse Observations for Full-Body Human Motion Synthesis
Apr 21, 2023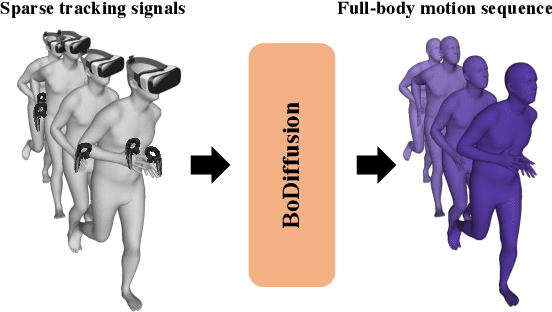

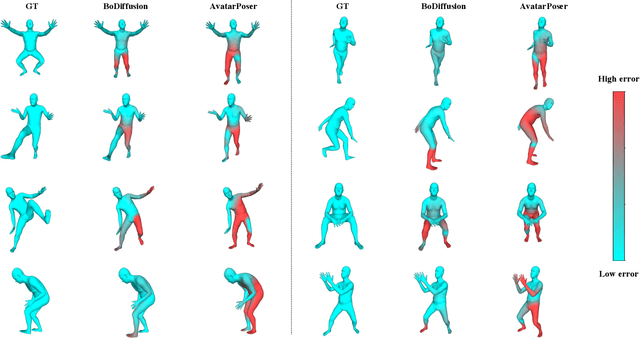
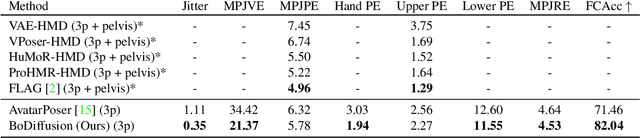
Mixed reality applications require tracking the user's full-body motion to enable an immersive experience. However, typical head-mounted devices can only track head and hand movements, leading to a limited reconstruction of full-body motion due to variability in lower body configurations. We propose BoDiffusion -- a generative diffusion model for motion synthesis to tackle this under-constrained reconstruction problem. We present a time and space conditioning scheme that allows BoDiffusion to leverage sparse tracking inputs while generating smooth and realistic full-body motion sequences. To the best of our knowledge, this is the first approach that uses the reverse diffusion process to model full-body tracking as a conditional sequence generation task. We conduct experiments on the large-scale motion-capture dataset AMASS and show that our approach outperforms the state-of-the-art approaches by a significant margin in terms of full-body motion realism and joint reconstruction error.
Generalized Real-World Super-Resolution through Adversarial Robustness
Aug 25, 2021
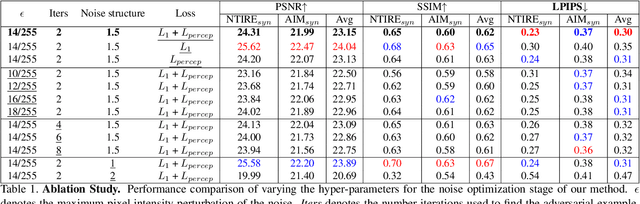
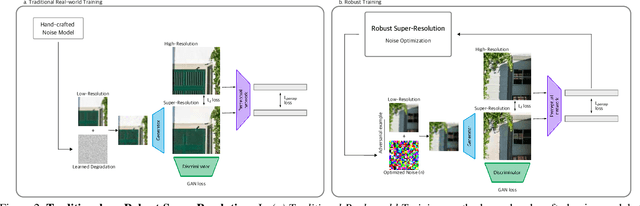
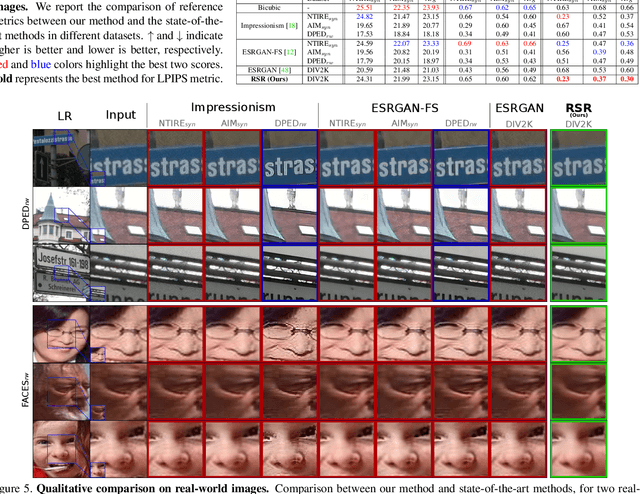
Real-world Super-Resolution (SR) has been traditionally tackled by first learning a specific degradation model that resembles the noise and corruption artifacts in low-resolution imagery. Thus, current methods lack generalization and lose their accuracy when tested on unseen types of corruption. In contrast to the traditional proposal, we present Robust Super-Resolution (RSR), a method that leverages the generalization capability of adversarial attacks to tackle real-world SR. Our novel framework poses a paradigm shift in the development of real-world SR methods. Instead of learning a dataset-specific degradation, we employ adversarial attacks to create difficult examples that target the model's weaknesses. Afterward, we use these adversarial examples during training to improve our model's capacity to process noisy inputs. We perform extensive experimentation on synthetic and real-world images and empirically demonstrate that our RSR method generalizes well across datasets without re-training for specific noise priors. By using a single robust model, we outperform state-of-the-art specialized methods on real-world benchmarks.