 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Imputation Fits Which Feature Selection Method? A Survey-Based Simulation Study
Dec 18, 2024



Tree-based learning methods such as Random Forest and XGBoost are still the gold-standard prediction methods for tabular data. Feature importance measures are usually considered for feature selection as well as to assess the effect of features on the outcome variables in the model. This also applies to survey data, which are frequently encountered in the social sciences and official statistics. These types of datasets often present the challenge of missing values. The typical solution is to impute the missing data before applying the learning method. However, given the large number of possible imputation methods available, the question arises as to which should be chosen to achieve the 'best' reflection of feature importance and feature selection in subsequent analyses. In the present paper, we investigate this question in a survey-based simulation study for eight state-of-the art imputation methods and three learners. The imputation methods comprise listwise deletion, three MICE options, four \texttt{missRanger} options as well as the recently proposed mixGBoost imputation approach. As learners, we consider the two most common tree-based methods, Random Forest and XGBoost, and an interpretable linear model with regularization.
Evaluating tree-based imputation methods as an alternative to MICE PMM for drawing inference in empirical studies
Jan 17, 2024Dealing with missing data is an important problem in statistical analysis that is often addressed with imputation procedures. The performance and validity of such methods are of great importance for their application in empirical studies. While the prevailing method of Multiple Imputation by Chained Equations (MICE) with Predictive Mean Matching (PMM) is considered standard in the social science literature, the increase in complex datasets may require more advanced approaches based on machine learning. In particular, tree-based imputation methods have emerged as very competitive approaches. However, the performance and validity are not completely understood, particularly compared to the standard MICE PMM. This is especially true for inference in linear models. In this study, we investigate the impact of various imputation methods on coefficient estimation, Type I error, and power, to gain insights that can help empirical researchers deal with missingness more effectively. We explore MICE PMM alongside different tree-based methods, such as MICE with Random Forest (RF), Chained Random Forests with and without PMM (missRanger), and Extreme Gradient Boosting (MIXGBoost), conducting a realistic simulation study using the German National Educational Panel Study (NEPS) as the original data source. Our results reveal that Random Forest-based imputations, especially MICE RF and missRanger with PMM, consistently perform better in most scenarios. Standard MICE PMM shows partially increased bias and overly conservative test decisions, particularly with non-true zero coefficients. Our results thus underscore the potential advantages of tree-based imputation methods, albeit with a caveat that all methods perform worse with an increased missingness, particularly missRanger.
Generalized Real-World Super-Resolution through Adversarial Robustness
Aug 25, 2021
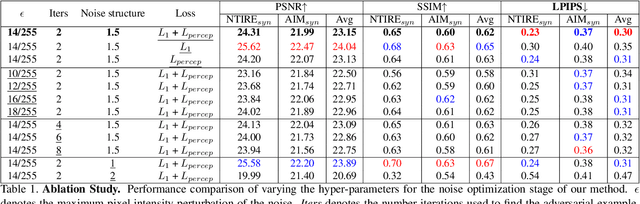
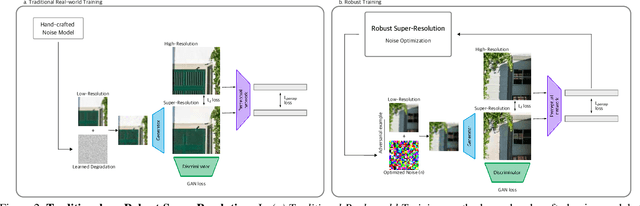
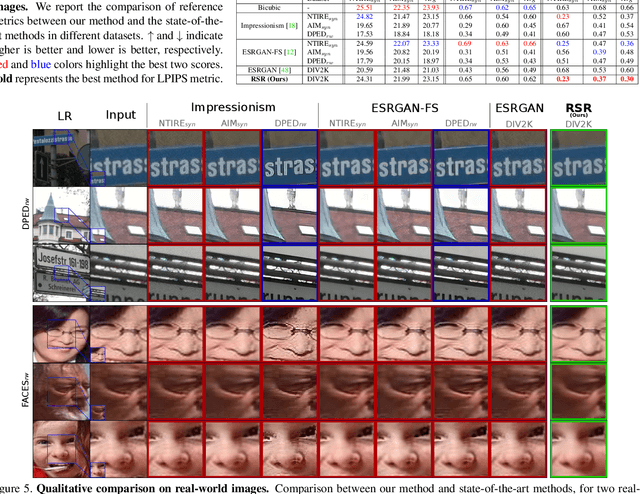
Real-world Super-Resolution (SR) has been traditionally tackled by first learning a specific degradation model that resembles the noise and corruption artifacts in low-resolution imagery. Thus, current methods lack generalization and lose their accuracy when tested on unseen types of corruption. In contrast to the traditional proposal, we present Robust Super-Resolution (RSR), a method that leverages the generalization capability of adversarial attacks to tackle real-world SR. Our novel framework poses a paradigm shift in the development of real-world SR methods. Instead of learning a dataset-specific degradation, we employ adversarial attacks to create difficult examples that target the model's weaknesses. Afterward, we use these adversarial examples during training to improve our model's capacity to process noisy inputs. We perform extensive experimentation on synthetic and real-world images and empirically demonstrate that our RSR method generalizes well across datasets without re-training for specific noise priors. By using a single robust model, we outperform state-of-the-art specialized methods on real-world benchmarks.
Zero-Pair Image to Image Translation using Domain Conditional Normalization
Nov 11, 2020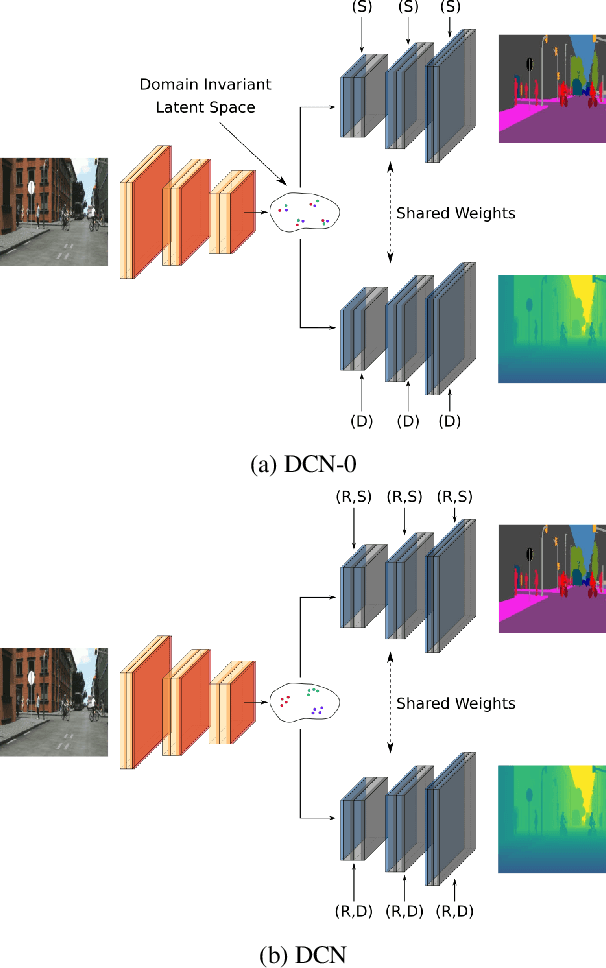
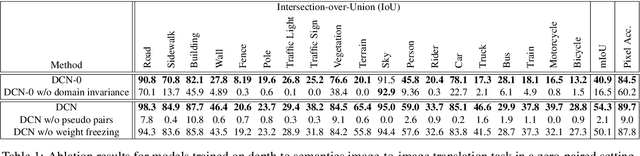
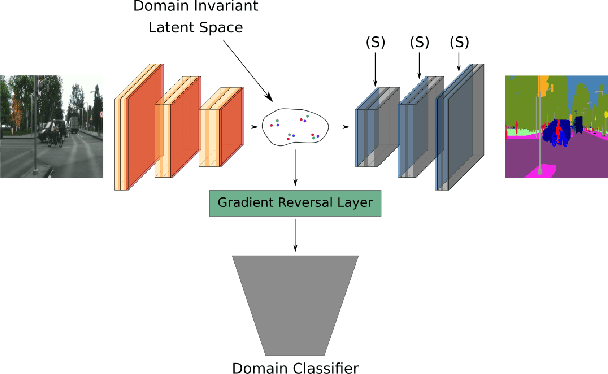

In this paper, we propose an approach based on domain conditional normalization (DCN) for zero-pair image-to-image translation, i.e., translating between two domains which have no paired training data available but each have paired training data with a third domain. We employ a single generator which has an encoder-decoder structure and analyze different implementations of domain conditional normalization to obtain the desired target domain output. The validation benchmark uses RGB-depth pairs and RGB-semantic pairs for training and compares performance for the depth-semantic translation task. The proposed approaches improve in qualitative and quantitative terms over the compared methods, while using much fewer parameters. Code available at https://github.com/samarthshukla/dcn
SMILE: Semantically-guided Multi-attribute Image and Layout Editing
Oct 05, 2020
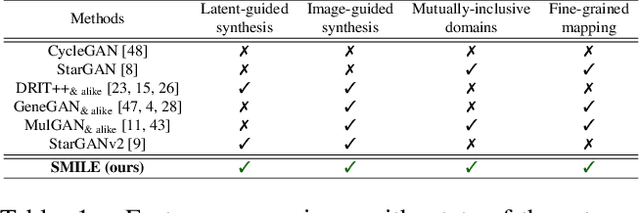
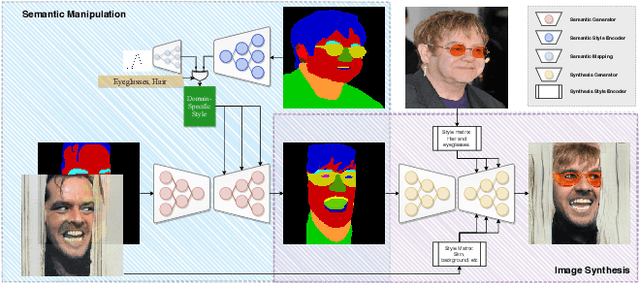

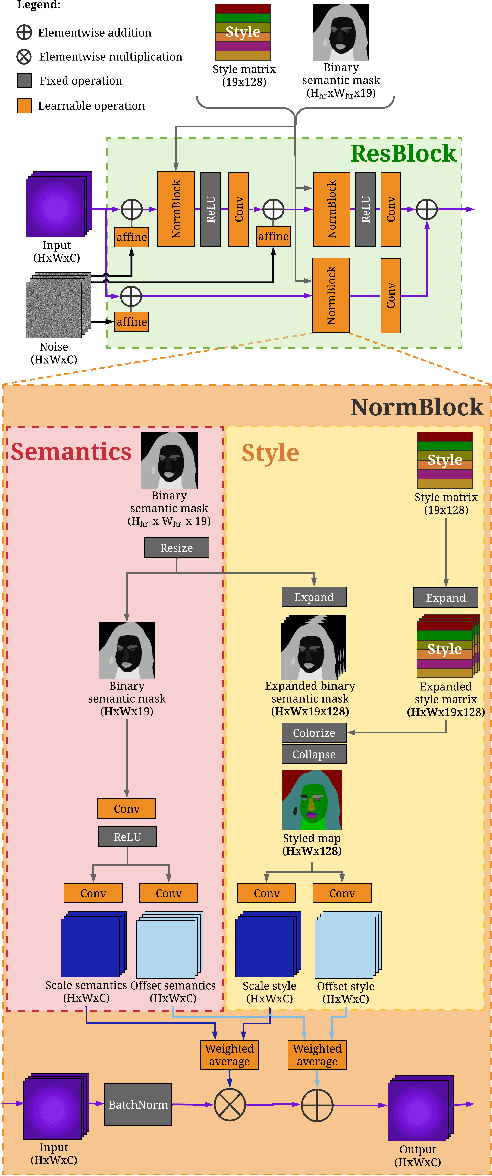
Attribute image manipulation has been a very active topic since the introduction of Generative Adversarial Networks (GANs). Exploring the disentangled attribute space within a transformation is a very challenging task due to the multiple and mutually-inclusive nature of the facial images, where different labels (eyeglasses, hats, hair, identity, etc.) can co-exist at the same time. Several works address this issue either by exploiting the modality of each domain/attribute using a conditional random vector noise, or extracting the modality from an exemplary image. However, existing methods cannot handle both random and reference transformations for multiple attributes, which limits the generality of the solutions. In this paper, we successfully exploit a multimodal representation that handles all attributes, be it guided by random noise or exemplar images, while only using the underlying domain information of the target domain. We present extensive qualitative and quantitative results for facial datasets and several different attributes that show the superiority of our method. Additionally, our method is capable of adding, removing or changing either fine-grained or coarse attributes by using an image as a reference or by exploring the style distribution space, and it can be easily extended to head-swapping and face-reenactment applications without being trained on videos.
AIM 2020 Challenge on Image Extreme Inpainting
Oct 02, 2020
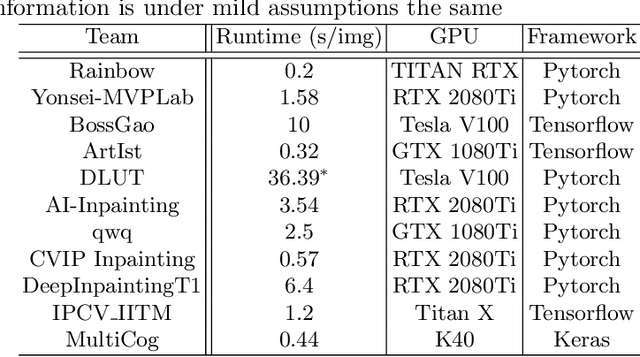
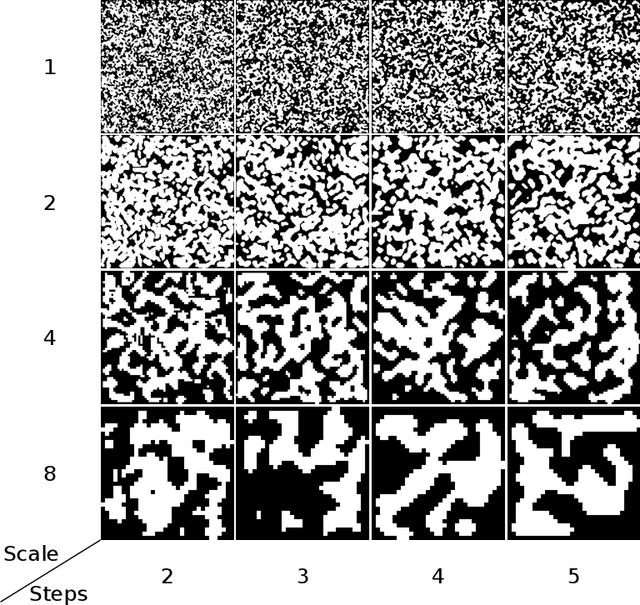
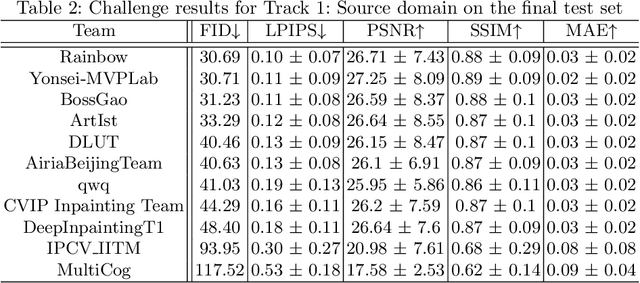
This paper reviews the AIM 2020 challenge on extreme image inpainting. This report focuses on proposed solutions and results for two different tracks on extreme image inpainting: classical image inpainting and semantically guided image inpainting. The goal of track 1 is to inpaint considerably large part of the image using no supervision but the context. Similarly, the goal of track 2 is to inpaint the image by having access to the entire semantic segmentation map of the image to inpaint. The challenge had 88 and 74 participants, respectively. 11 and 6 teams competed in the final phase of the challenge, respectively. This report gauges current solutions and set a benchmark for future extreme image inpainting methods.
SESAME: Semantic Editing of Scenes by Adding, Manipulating or Erasing Objects
Apr 10, 2020
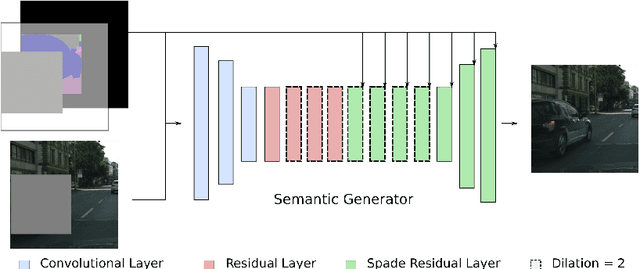

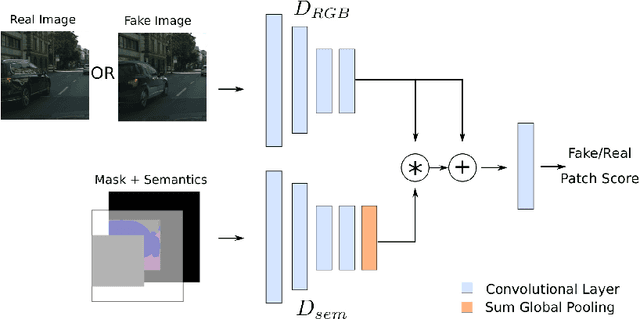
Recent advances in image generation gave rise to powerful tools for semantic image editing. However, existing approaches can either operate on a single image or require an abundance of additional information. They are not capable of handling the complete set of editing operations, that is addition, manipulation or removal of semantic concepts. To address these limitations, we propose SESAME, a novel generator-discriminator pair for Semantic Editing of Scenes by Adding, Manipulating or Erasing objects. In our setup, the user provides the semantic labels of the areas to be edited and the generator synthesizes the corresponding pixels. In contrast to previous methods that employ a discriminator that trivially concatenates semantics and image as an input, the SESAME discriminator is composed of two input streams that independently process the image and its semantics, using the latter to manipulate the results of the former. We evaluate our model on a diverse set of datasets and report state-of-the-art performance on two tasks: (a) image manipulation and (b) image generation conditioned on semantic labels.
DeepSEE: Deep Disentangled Semantic Explorative Extreme Super-Resolution
Apr 09, 2020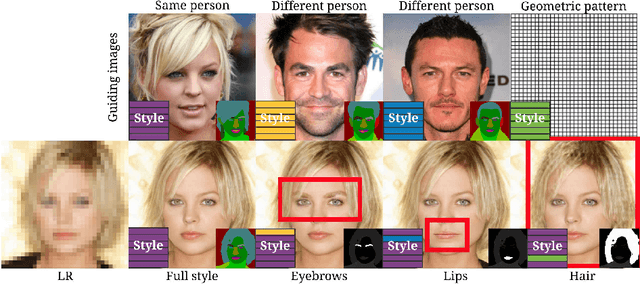
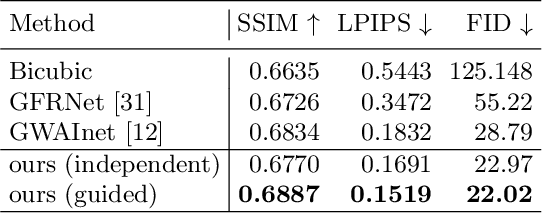
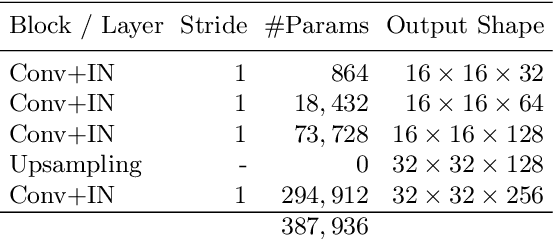
Super-resolution (SR) is by definition ill-posed. There are infinitely many plausible high-resolution variants for a given low-resolution natural image. This is why example-based SR methods study upscaling factors up to 4x (or up to 8x for face hallucination). Most of the current literature aims at a single deterministic solution of either high reconstruction fidelity or photo-realistic perceptual quality. In this work, we propose a novel framework, DeepSEE, for Deep disentangled Semantic Explorative Extreme super-resolution. To the best of our knowledge, DeepSEE is the first method to leverage semantic maps for explorative super-resolution. In particular, it provides control of the semantic regions, their disentangled appearance and it allows a broad range of image manipulations. We validate DeepSEE for up to 32x magnification and exploration of the space of super-resolution.
SMIT: Stochastic Multi-Label Image-to-Image Translation
Dec 10, 2018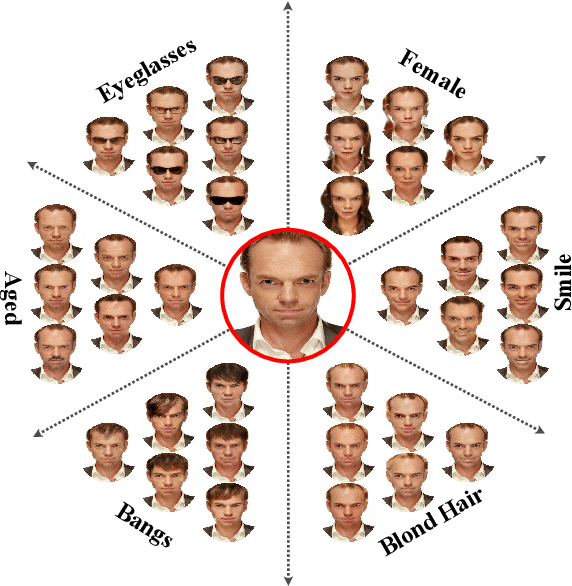

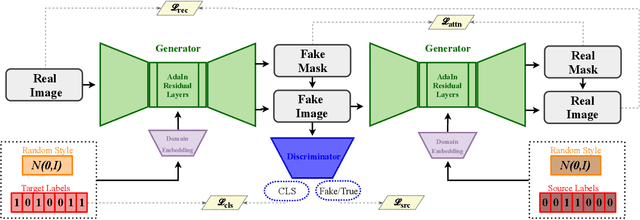
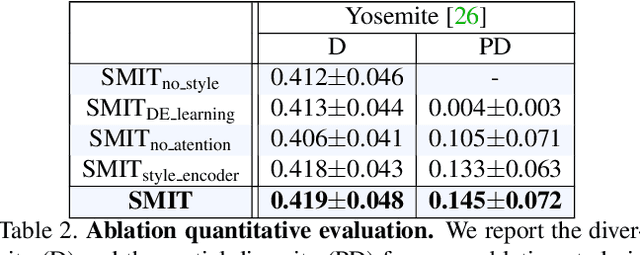
Cross-domain mapping has been a very active topic in recent years. Given one image, its main purpose is to translate it to the desired target domain, or multiple domains in the case of multiple labels. This problem is highly challenging due to three main reasons: (i) unpaired datasets, (ii) multiple attributes, and (iii) the multimodality associated with the translation. Most of the existing state-of-the-art has focused only on two reasons, i.e. producing disentangled representations from unpaired datasets in a one-to-one domain translation or producing multiple unimodal attributes from unpaired datasets. In this work, we propose a joint framework of diversity and multi-mapping image-to-image translations, using a single generator to conditionally produce countless and unique fake images that hold the underlying characteristics of the source image. Extensive experiments over different datasets demonstrate the effectiveness of our proposed approach with comparisons to the state-of-the-art in both multi-label and multimodal problems. Additionally, our method is able to generalize under different scenarios: continuous style interpolation, continuous label interpolation, and multi-label mapping.