 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleGenes: Discrete and Efficient Latent Distributions for GANs
Apr 30, 2023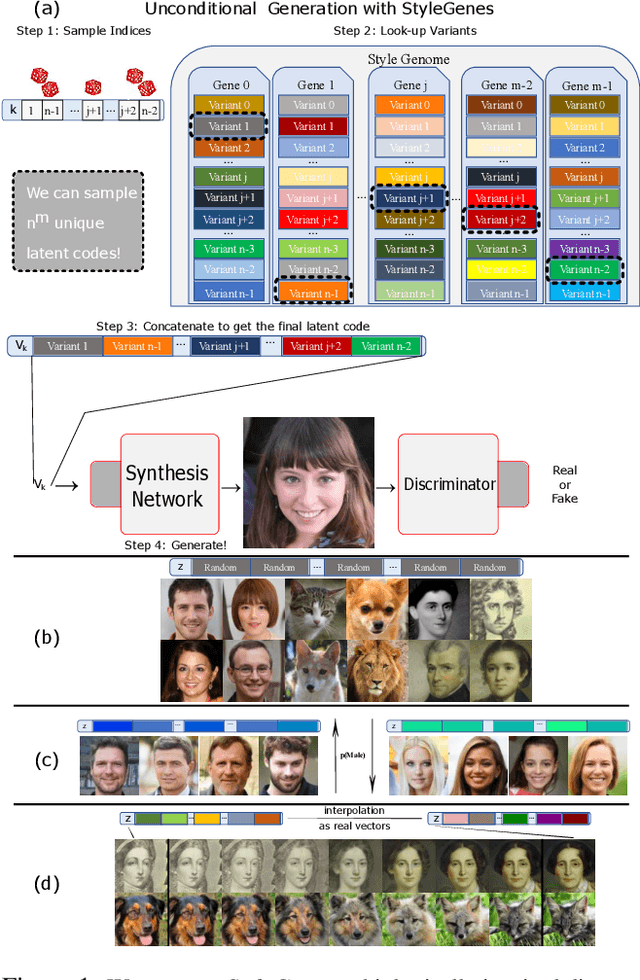



We propose a discrete latent distribution for Generative Adversarial Networks (GANs). Instead of drawing latent vectors from a continuous prior, we sample from a finite set of learnable latents. However, a direct parametrization of such a distribution leads to an intractable linear increase in memory in order to ensure sufficient sample diversity. We address this key issue by taking inspiration from the encoding of information in biological organisms. Instead of learning a separate latent vector for each sample, we split the latent space into a set of genes. For each gene, we train a small bank of gene variants. Thus, by independently sampling a variant for each gene and combining them into the final latent vector, our approach can represent a vast number of unique latent samples from a compact set of learnable parameters. Interestingly, our gene-inspired latent encoding allows for new and intuitive approaches to latent-space exploration, enabling conditional sampling from our unconditionally trained model. Moreover, our approach preserves state-of-the-art photo-realism while achieving better disentanglement than the widely-used StyleMapping network.
Arbitrary-Scale Image Synthesis
Apr 05, 2022Positional encodings have enabled recent works to train a single adversarial network that can generate images of different scales. However, these approaches are either limited to a set of discrete scales or struggle to maintain good perceptual quality at the scales for which the model is not trained explicitly. We propose the design of scale-consistent positional encodings invariant to our generator's layers transformations. This enables the generation of arbitrary-scale images even at scales unseen during training. Moreover, we incorporate novel inter-scale augmentations into our pipeline and partial generation training to facilitate the synthesis of consistent images at arbitrary scales. Lastly, we show competitive results for a continuum of scales on various commonly used datasets for image synthesis.
Uncertainty-aware Remaining Useful Life predictor
Apr 08, 2021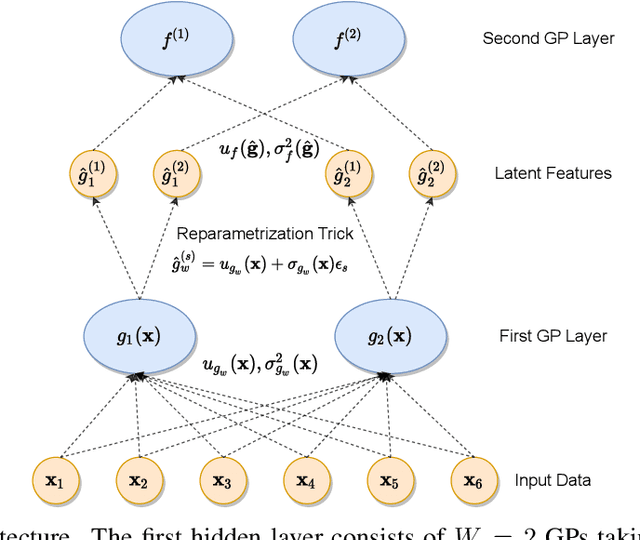

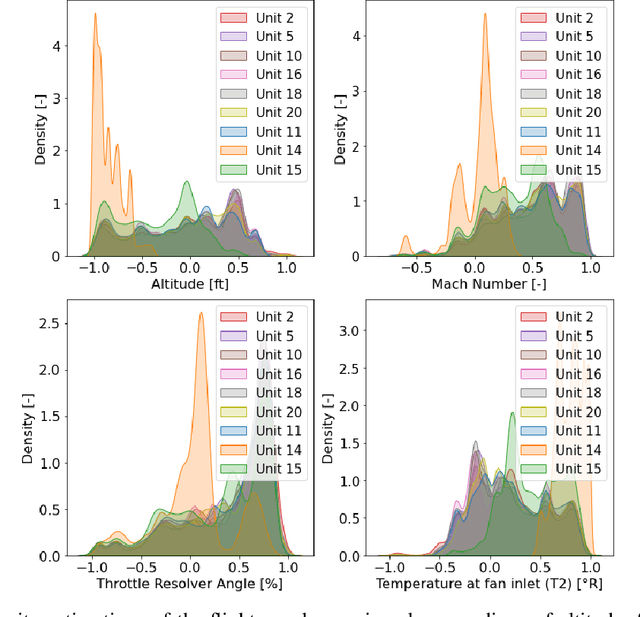

Remaining Useful Life (RUL) estimation is the problem of inferring how long a certain industrial asset can be expected to operate within its defined specifications. Deploying successful RUL prediction methods in real-life applications is a prerequisite for the design of intelligent maintenance strategies with the potential of drastically reducing maintenance costs and machine downtimes. In light of their superior performance in a wide range of engineering fields, Machine Learning (ML) algorithms are natural candidates to tackle the challenges involved in the design of intelligent maintenance systems. In particular, given the potentially catastrophic consequences or substantial costs associated with maintenance decisions that are either too late or too early, it is desirable that ML algorithms provide uncertainty estimates alongside their predictions. However, standard data-driven methods used for uncertainty estimation in RUL problems do not scale well to large datasets or are not sufficiently expressive to model the high-dimensional mapping from raw sensor data to RUL estimates. In this work, we consider Deep Gaussian Processes (DGPs) as possible solutions to the aforementioned limitations. We perform a thorough evaluation and comparison of several variants of DGPs applied to RUL predictions. The performance of the algorithms is evaluated on the N-CMAPSS (New Commercial Modular Aero-Propulsion System Simulation) dataset from NASA for aircraft engines. The results show that the proposed methods are able to provide very accurate RUL predictions along with sensible uncertainty estimates, providing more reliable solutions for (safety-critical) real-life industrial applications.
SESAME: Semantic Editing of Scenes by Adding, Manipulating or Erasing Objects
Apr 10, 2020
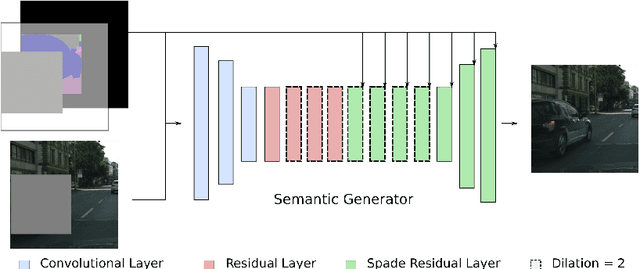

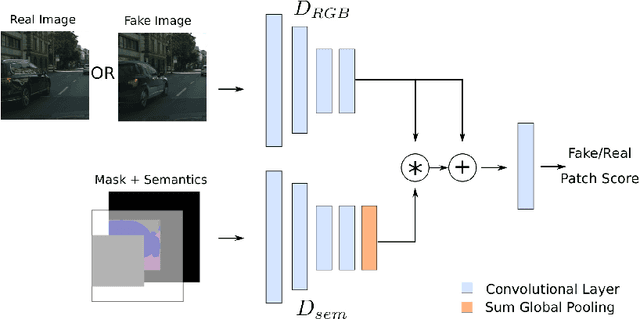
Recent advances in image generation gave rise to powerful tools for semantic image editing. However, existing approaches can either operate on a single image or require an abundance of additional information. They are not capable of handling the complete set of editing operations, that is addition, manipulation or removal of semantic concepts. To address these limitations, we propose SESAME, a novel generator-discriminator pair for Semantic Editing of Scenes by Adding, Manipulating or Erasing objects. In our setup, the user provides the semantic labels of the areas to be edited and the generator synthesizes the corresponding pixels. In contrast to previous methods that employ a discriminator that trivially concatenates semantics and image as an input, the SESAME discriminator is composed of two input streams that independently process the image and its semantics, using the latter to manipulate the results of the former. We evaluate our model on a diverse set of datasets and report state-of-the-art performance on two tasks: (a) image manipulation and (b) image generation conditioned on semantic labels.