 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverhead Wildlife Locator (OWL): Benchmarking Weakly Supervised Learning for Aerial Wildlife Surveys
Jun 11, 2026Automated aerial wildlife surveys increasingly rely on deep learning, yet standard object detectors require bounding-box annotations, reported to be up to seven times slower and three times more expensive to produce than point-level labels. To address this bottleneck, we introduce the Overhead Wildlife Locator (OWL), a weakly supervised density-estimation framework with three variants: OWL-C, a fully convolutional model for high-throughput screening; OWL-T, a Swin-augmented hybrid for heterogeneous, cluttered scenes; and OWL-D, built on a frozen DINOv3 ViT-H+/16 encoder with a DPT-style fusion decoder. We benchmark all three against POLO, YOLOv11n, and YOLOv11l across five public aerial datasets, from sparse fixed-wing savanna surveys to dense UAV paddock imagery, and against the published HerdNet baseline on its native Delplanque split. OWL-D sets a new state of the art on Delplanque (0.934 AP vs. HerdNet's 0.840) and records the highest AP on four of the five datasets. Performance is regime-dependent: on the extreme-density SheepCounter UAV dataset the hybrid OWL-T leads (0.978 AP) and the convolutional variants attain the lowest counting error, whereas the foundation-based OWL-D degrades, indicating which variant suits which survey type. We further validate operational readiness on the Alaska Department of Fish and Game's 2022 Central Arctic Caribou census: under cross-herd and cross-temporal transfer, OWL-C fine-tuned on the 2017 Porcupine Caribou Herd split attains F1 = 0.965 on a held-out patch test set, with a signed count error of +3.1% aggregated across the released test patches. We release the OWL code, model weights, and the annotated Porcupine Caribou Herd 2017 (PCH) and Central Arctic Herd 2022 (CAH) patches, the first open patch-level datasets for large-scale caribou aerial surveys, at https://github.com/microsoft/MegaDetector-Overhead.
A strongly annotated passive acoustic dataset for tropical bird monitoring
May 21, 2026Passive acoustic monitoring enables continuous, non-invasive biodiversity assessment across diverse ecosystems. The scale of these datasets has driven the adoption of machine learning, with supervised approaches showing strong performance. However, supervised methods require time-resolved annotated datasets, which remain scarce, especially in complex tropical soundscapes. We present PteroSet, a curated dataset of strongly annotated Neotropical bird vocalizations recorded in Puerto Asis (Putumayo) and Pivijay (Magdalena), Colombia, between 2023 and 2025. The dataset comprises 563 recordings (73.62 h) and 15,372 time-frequency annotations, including 6,702 events identified to the species level across 168 species. We release the annotations in a COCO-inspired JSON schema that unifies audio files, taxonomic categories, and labels for machine learning workflows. Beyond providing annotated data, PteroSet serves as a realistic benchmark that highlights key characteristics of tropical soundscapes, including acoustic co-occurrence and domain shift across recording sites. We provide a deep learning baseline for binary bird detection, demonstrating PteroSet's usability and the challenges it presents.
A Standardized Benchmark for Multilabel Antimicrobial Peptide Classification
Nov 06, 2025Antimicrobial peptides have emerged as promising molecules to combat antimicrobial resistance. However, fragmented datasets, inconsistent annotations, and the lack of standardized benchmarks hinder computational approaches and slow down the discovery of new candidates. To address these challenges, we present the Expanded Standardized Collection for Antimicrobial Peptide Evaluation (ESCAPE), an experimental framework integrating over 80.000 peptides from 27 validated repositories. Our dataset separates antimicrobial peptides from negative sequences and incorporates their functional annotations into a biologically coherent multilabel hierarchy, capturing activities across antibacterial, antifungal, antiviral, and antiparasitic classes. Building on ESCAPE, we propose a transformer-based model that leverages sequence and structural information to predict multiple functional activities of peptides. Our method achieves up to a 2.56% relative average improvement in mean Average Precision over the second-best method adapted for this task, establishing a new state-of-the-art multilabel peptide classification. ESCAPE provides a comprehensive and reproducible evaluation framework to advance AI-driven antimicrobial peptide research.
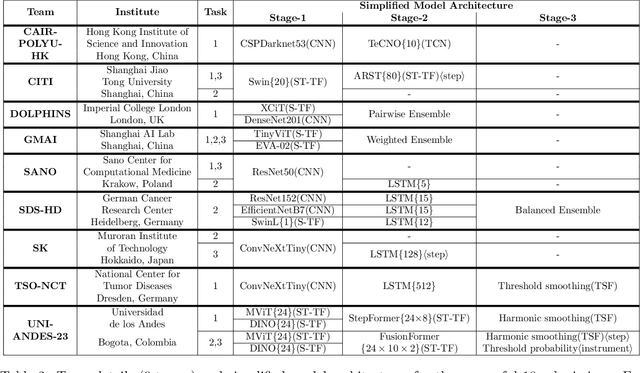
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
SMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024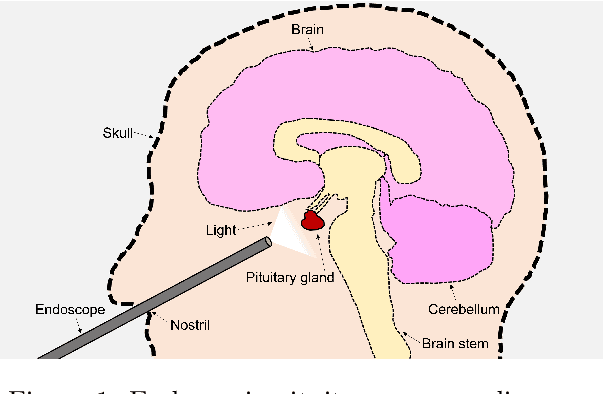

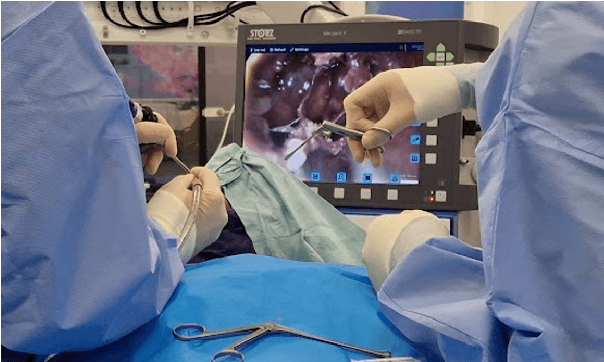
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
Deep Learning at the Intersection: Certified Robustness as a Tool for 3D Vision
Aug 23, 2024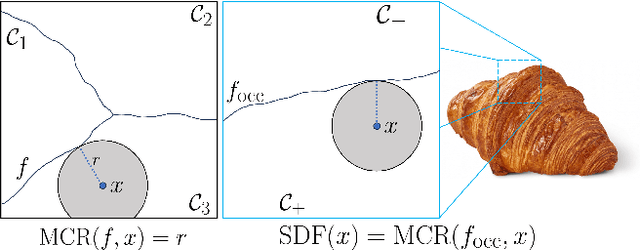
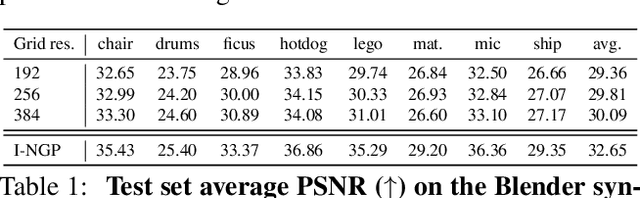

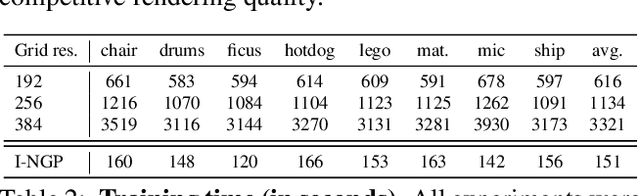
This paper presents preliminary work on a novel connection between certified robustness in machine learning and the modeling of 3D objects. We highlight an intriguing link between the Maximal Certified Radius (MCR) of a classifier representing a space's occupancy and the space's Signed Distance Function (SDF). Leveraging this relationship, we propose to use the certification method of randomized smoothing (RS) to compute SDFs. Since RS' high computational cost prevents its practical usage as a way to compute SDFs, we propose an algorithm to efficiently run RS in low-dimensional applications, such as 3D space, by expressing RS' fundamental operations as Gaussian smoothing on pre-computed voxel grids. Our approach offers an innovative and practical tool to compute SDFs, validated through proof-of-concept experiments in novel view synthesis. This paper bridges two previously disparate areas of machine learning, opening new avenues for further exploration and potential cross-domain advancements.
MuST: Multi-Scale Transformers for Surgical Phase Recognition
Jul 24, 2024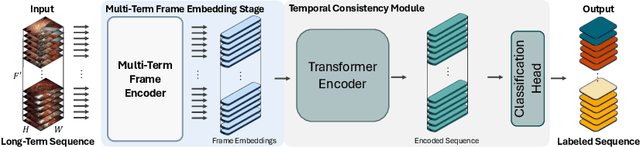

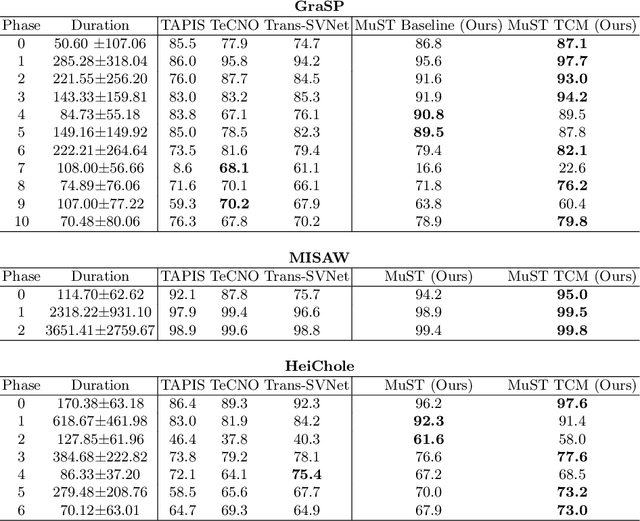
Phase recognition in surgical videos is crucial for enhancing computer-aided surgical systems as it enables automated understanding of sequential procedural stages. Existing methods often rely on fixed temporal windows for video analysis to identify dynamic surgical phases. Thus, they struggle to simultaneously capture short-, mid-, and long-term information necessary to fully understand complex surgical procedures. To address these issues, we propose Multi-Scale Transformers for Surgical Phase Recognition (MuST), a novel Transformer-based approach that combines a Multi-Term Frame encoder with a Temporal Consistency Module to capture information across multiple temporal scales of a surgical video. Our Multi-Term Frame Encoder computes interdependencies across a hierarchy of temporal scales by sampling sequences at increasing strides around the frame of interest. Furthermore, we employ a long-term Transformer encoder over the frame embeddings to further enhance long-term reasoning. MuST achieves higher performance than previous state-of-the-art methods on three different public benchmarks.
Enhancing Gene Expression Prediction from Histology Images with Spatial Transcriptomics Completion
Jul 17, 2024



Spatial Transcriptomics is a novel technology that aligns histology images with spatially resolved gene expression profiles. Although groundbreaking, it struggles with gene capture yielding high corruption in acquired data. Given potential applications, recent efforts have focused on predicting transcriptomic profiles solely from histology images. However, differences in databases, preprocessing techniques, and training hyperparameters hinder a fair comparison between methods. To address these challenges, we present a systematically curated and processed database collected from 26 public sources, representing an 8.6-fold increase compared to previous works. Additionally, we propose a state-of-the-art transformer based completion technique for inferring missing gene expression, which significantly boosts the performance of transcriptomic profile predictions across all datasets. Altogether, our contributions constitute the most comprehensive benchmark of gene expression prediction from histology images to date and a stepping stone for future research on spatial transcriptomics.
Pixel-Wise Recognition for Holistic Surgical Scene Understanding
Jan 26, 2024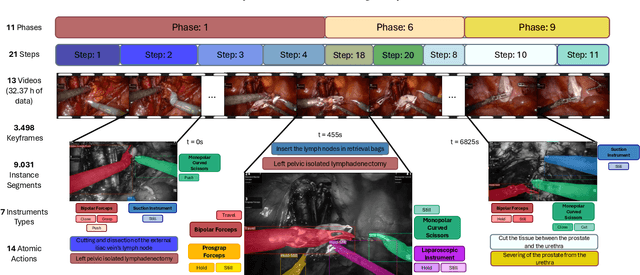
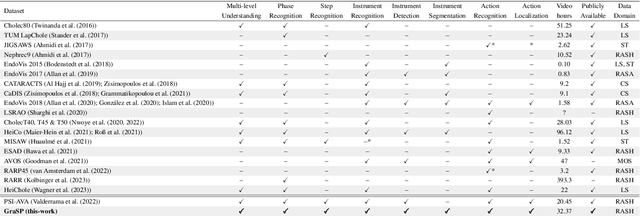
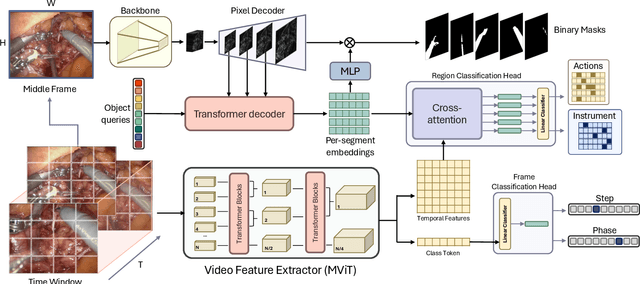
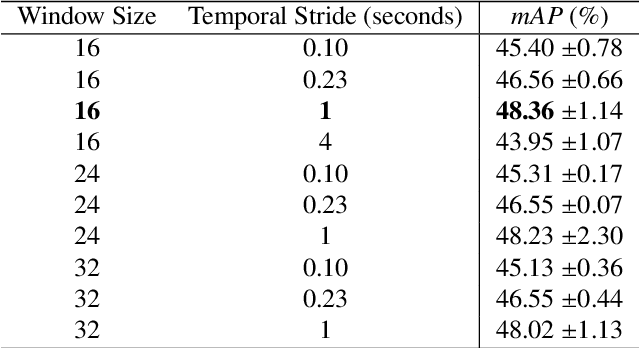
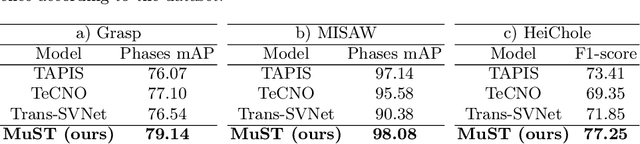
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach enables a multi-level comprehension of surgical activities, encompassing long-term tasks such as surgical phases and steps recognition and short-term tasks including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. Through extensive experimentation, we demonstrate the impact of including segmentation annotations in short-term recognition tasks, highlight the varying granularity requirements of each task, and establish TAPIS's superiority over previously proposed baselines and conventional CNN-based models. Additionally, we validate the robustness of our method across multiple public benchmarks, confirming the reliability and applicability of our dataset. This work represents a significant step forward in Endoscopic Vision, offering a novel and comprehensive framework for future research towards a holistic understanding of surgical procedures.