 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Wise Recognition for Holistic Surgical Scene Understanding
Jan 26, 2024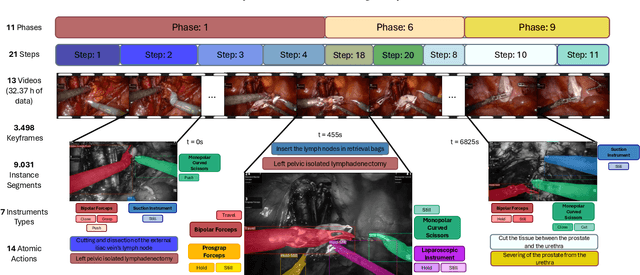
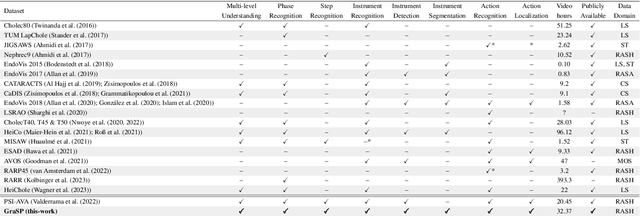
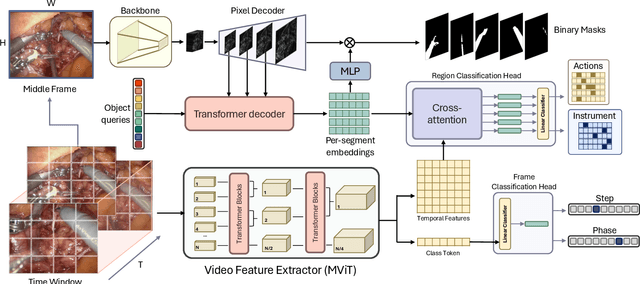
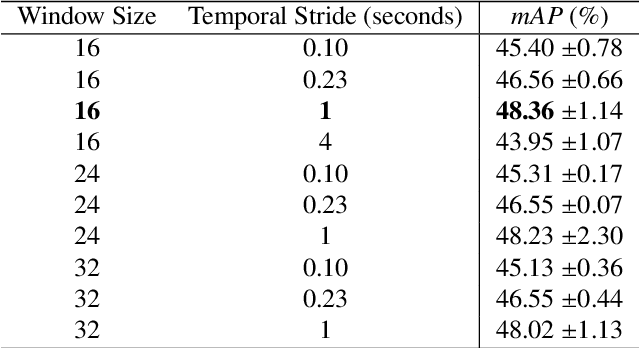
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach enables a multi-level comprehension of surgical activities, encompassing long-term tasks such as surgical phases and steps recognition and short-term tasks including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. Through extensive experimentation, we demonstrate the impact of including segmentation annotations in short-term recognition tasks, highlight the varying granularity requirements of each task, and establish TAPIS's superiority over previously proposed baselines and conventional CNN-based models. Additionally, we validate the robustness of our method across multiple public benchmarks, confirming the reliability and applicability of our dataset. This work represents a significant step forward in Endoscopic Vision, offering a novel and comprehensive framework for future research towards a holistic understanding of surgical procedures.
A Quantitative Evaluation of Dense 3D Reconstruction of Sinus Anatomy from Monocular Endoscopic Video
Oct 22, 2023



Generating accurate 3D reconstructions from endoscopic video is a promising avenue for longitudinal radiation-free analysis of sinus anatomy and surgical outcomes. Several methods for monocular reconstruction have been proposed, yielding visually pleasant 3D anatomical structures by retrieving relative camera poses with structure-from-motion-type algorithms and fusion of monocular depth estimates. However, due to the complex properties of the underlying algorithms and endoscopic scenes, the reconstruction pipeline may perform poorly or fail unexpectedly. Further, acquiring medical data conveys additional challenges, presenting difficulties in quantitatively benchmarking these models, understanding failure cases, and identifying critical components that contribute to their precision. In this work, we perform a quantitative analysis of a self-supervised approach for sinus reconstruction using endoscopic sequences paired with optical tracking and high-resolution computed tomography acquired from nine ex-vivo specimens. Our results show that the generated reconstructions are in high agreement with the anatomy, yielding an average point-to-mesh error of 0.91 mm between reconstructions and CT segmentations. However, in a point-to-point matching scenario, relevant for endoscope tracking and navigation, we found average target registration errors of 6.58 mm. We identified that pose and depth estimation inaccuracies contribute equally to this error and that locally consistent sequences with shorter trajectories generate more accurate reconstructions. These results suggest that achieving global consistency between relative camera poses and estimated depths with the anatomy is essential. In doing so, we can ensure proper synergy between all components of the pipeline for improved reconstructions that will facilitate clinical application of this innovative technology.
Towards Holistic Surgical Scene Understanding
Dec 13, 2022Most benchmarks for studying surgical interventions focus on a specific challenge instead of leveraging the intrinsic complementarity among different tasks. In this work, we present a new experimental framework towards holistic surgical scene understanding. First, we introduce the Phase, Step, Instrument, and Atomic Visual Action recognition (PSI-AVA) Dataset. PSI-AVA includes annotations for both long-term (Phase and Step recognition) and short-term reasoning (Instrument detection and novel Atomic Action recognition) in robot-assisted radical prostatectomy videos. Second, we present Transformers for Action, Phase, Instrument, and steps Recognition (TAPIR) as a strong baseline for surgical scene understanding. TAPIR leverages our dataset's multi-level annotations as it benefits from the learned representation on the instrument detection task to improve its classification capacity. Our experimental results in both PSI-AVA and other publicly available databases demonstrate the adequacy of our framework to spur future research on holistic surgical scene understanding.