 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024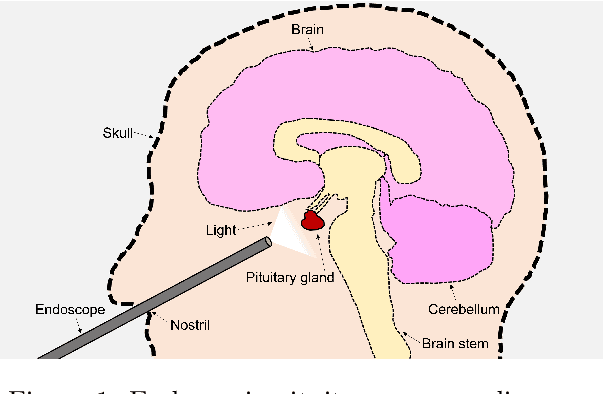

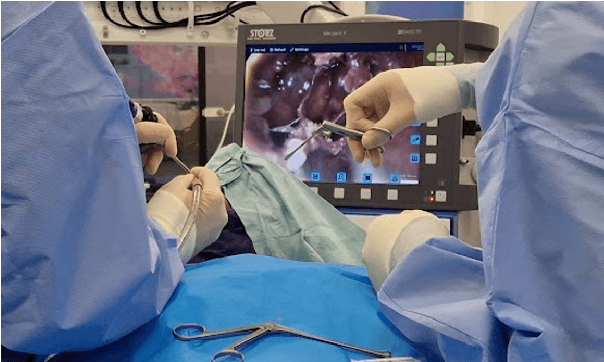
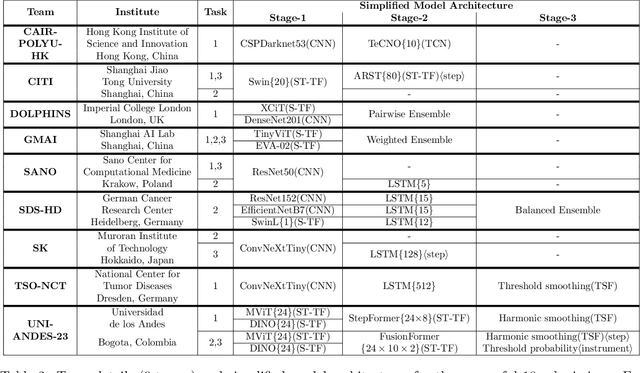
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
MuST: Multi-Scale Transformers for Surgical Phase Recognition
Jul 24, 2024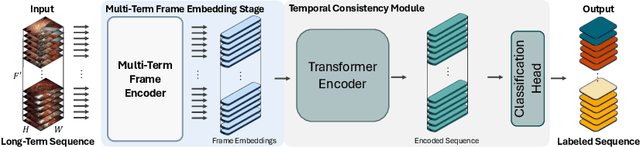
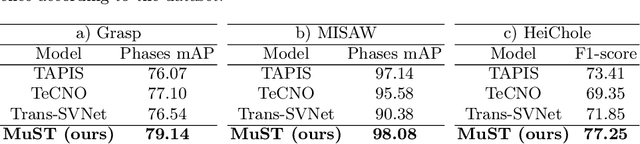

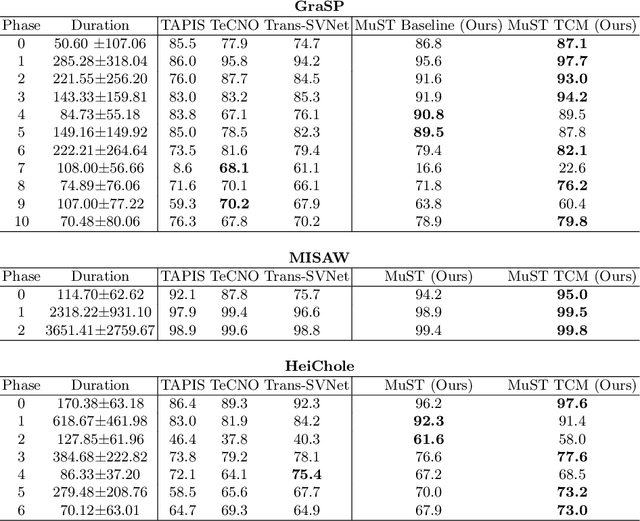
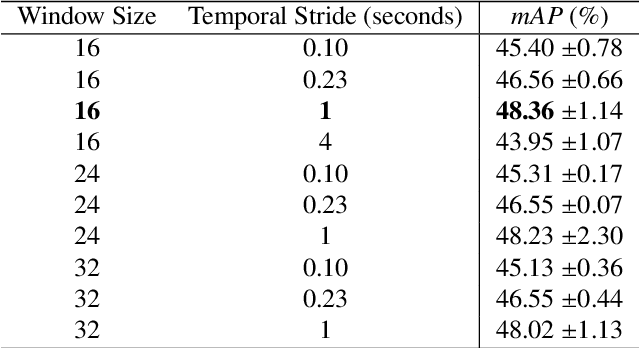
Phase recognition in surgical videos is crucial for enhancing computer-aided surgical systems as it enables automated understanding of sequential procedural stages. Existing methods often rely on fixed temporal windows for video analysis to identify dynamic surgical phases. Thus, they struggle to simultaneously capture short-, mid-, and long-term information necessary to fully understand complex surgical procedures. To address these issues, we propose Multi-Scale Transformers for Surgical Phase Recognition (MuST), a novel Transformer-based approach that combines a Multi-Term Frame encoder with a Temporal Consistency Module to capture information across multiple temporal scales of a surgical video. Our Multi-Term Frame Encoder computes interdependencies across a hierarchy of temporal scales by sampling sequences at increasing strides around the frame of interest. Furthermore, we employ a long-term Transformer encoder over the frame embeddings to further enhance long-term reasoning. MuST achieves higher performance than previous state-of-the-art methods on three different public benchmarks.
Pixel-Wise Recognition for Holistic Surgical Scene Understanding
Jan 26, 2024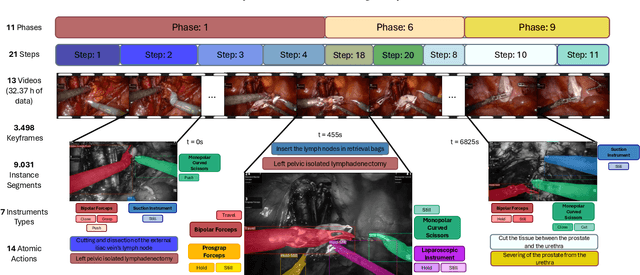
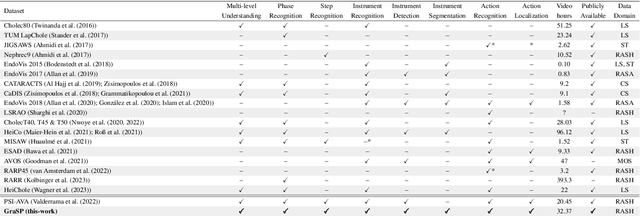
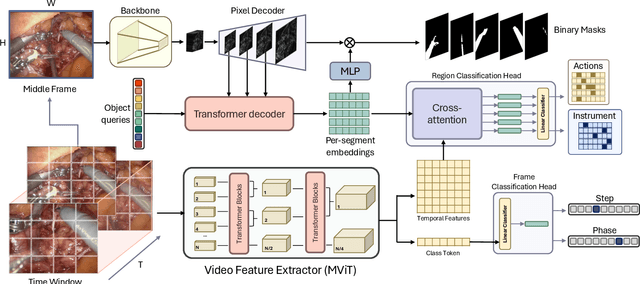
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach enables a multi-level comprehension of surgical activities, encompassing long-term tasks such as surgical phases and steps recognition and short-term tasks including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. Through extensive experimentation, we demonstrate the impact of including segmentation annotations in short-term recognition tasks, highlight the varying granularity requirements of each task, and establish TAPIS's superiority over previously proposed baselines and conventional CNN-based models. Additionally, we validate the robustness of our method across multiple public benchmarks, confirming the reliability and applicability of our dataset. This work represents a significant step forward in Endoscopic Vision, offering a novel and comprehensive framework for future research towards a holistic understanding of surgical procedures.