 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Endoscopic Chisel: Intraoperative Imaging Carves 3D Anatomical Models
Feb 19, 2024Purpose: Preoperative imaging plays a pivotal role in sinus surgery where CTs offer patient-specific insights of complex anatomy, enabling real-time intraoperative navigation to complement endoscopy imaging. However, surgery elicits anatomical changes not represented in the preoperative model, generating an inaccurate basis for navigation during surgery progression. Methods: We propose a first vision-based approach to update the preoperative 3D anatomical model leveraging intraoperative endoscopic video for navigated sinus surgery where relative camera poses are known. We rely on comparisons of intraoperative monocular depth estimates and preoperative depth renders to identify modified regions. The new depths are integrated in these regions through volumetric fusion in a truncated signed distance function representation to generate an intraoperative 3D model that reflects tissue manipulation. Results: We quantitatively evaluate our approach by sequentially updating models for a five-step surgical progression in an ex vivo specimen. We compute the error between correspondences from the updated model and ground-truth intraoperative CT in the region of anatomical modification. The resulting models show a decrease in error during surgical progression as opposed to increasing when no update is employed. Conclusion: Our findings suggest that preoperative 3D anatomical models can be updated using intraoperative endoscopy video in navigated sinus surgery. Future work will investigate improvements to monocular depth estimation as well as removing the need for external navigation systems. The resulting ability to continuously update the patient model may provide surgeons with a more precise understanding of the current anatomical state and paves the way toward a digital twin paradigm for sinus surgery.
A Quantitative Evaluation of Dense 3D Reconstruction of Sinus Anatomy from Monocular Endoscopic Video
Oct 22, 2023



Generating accurate 3D reconstructions from endoscopic video is a promising avenue for longitudinal radiation-free analysis of sinus anatomy and surgical outcomes. Several methods for monocular reconstruction have been proposed, yielding visually pleasant 3D anatomical structures by retrieving relative camera poses with structure-from-motion-type algorithms and fusion of monocular depth estimates. However, due to the complex properties of the underlying algorithms and endoscopic scenes, the reconstruction pipeline may perform poorly or fail unexpectedly. Further, acquiring medical data conveys additional challenges, presenting difficulties in quantitatively benchmarking these models, understanding failure cases, and identifying critical components that contribute to their precision. In this work, we perform a quantitative analysis of a self-supervised approach for sinus reconstruction using endoscopic sequences paired with optical tracking and high-resolution computed tomography acquired from nine ex-vivo specimens. Our results show that the generated reconstructions are in high agreement with the anatomy, yielding an average point-to-mesh error of 0.91 mm between reconstructions and CT segmentations. However, in a point-to-point matching scenario, relevant for endoscope tracking and navigation, we found average target registration errors of 6.58 mm. We identified that pose and depth estimation inaccuracies contribute equally to this error and that locally consistent sequences with shorter trajectories generate more accurate reconstructions. These results suggest that achieving global consistency between relative camera poses and estimated depths with the anatomy is essential. In doing so, we can ensure proper synergy between all components of the pipeline for improved reconstructions that will facilitate clinical application of this innovative technology.
Video-based assessment of intraoperative surgical skill
May 13, 2022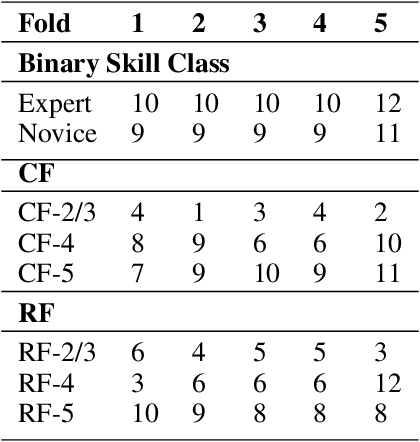
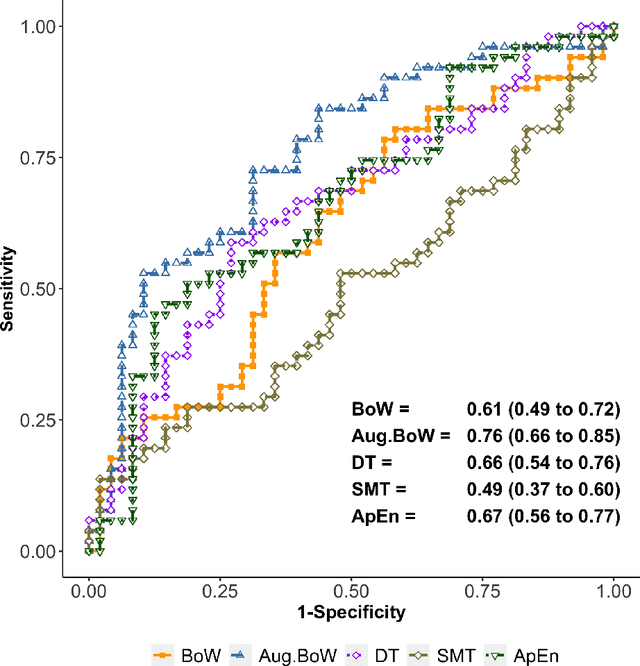
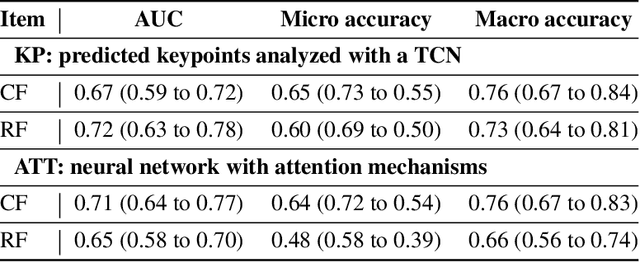
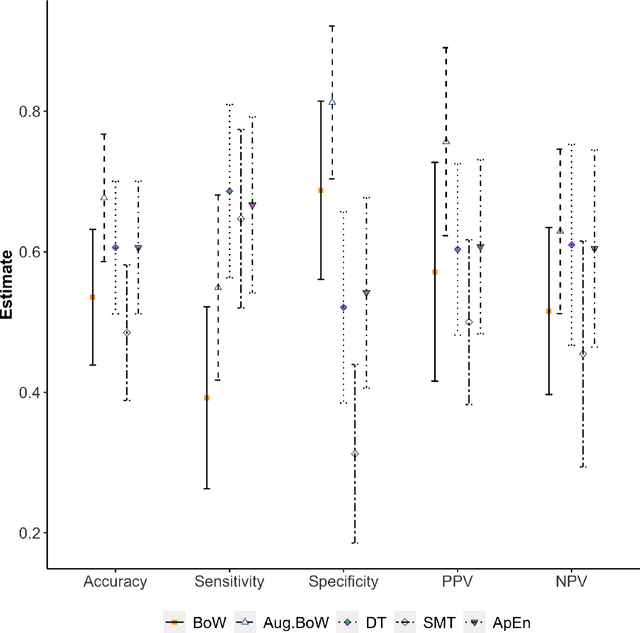
Purpose: The objective of this investigation is to provide a comprehensive analysis of state-of-the-art methods for video-based assessment of surgical skill in the operating room. Methods: Using a data set of 99 videos of capsulorhexis, a critical step in cataract surgery, we evaluate feature based methods previously developed for surgical skill assessment mostly under benchtop settings. In addition, we present and validate two deep learning methods that directly assess skill using RGB videos. In the first method, we predict instrument tips as keypoints, and learn surgical skill using temporal convolutional neural networks. In the second method, we propose a novel architecture for surgical skill assessment that includes a frame-wise encoder (2D convolutional neural network) followed by a temporal model (recurrent neural network), both of which are augmented by visual attention mechanisms. We report the area under the receiver operating characteristic curve, sensitivity, specificity, and predictive values with each method through 5-fold cross-validation. Results: For the task of binary skill classification (expert vs. novice), deep neural network based methods exhibit higher AUC than the classical spatiotemporal interest point based methods. The neural network approach using attention mechanisms also showed high sensitivity and specificity. Conclusion: Deep learning methods are necessary for video-based assessment of surgical skill in the operating room. Our findings of internal validity of a network using attention mechanisms to assess skill directly using RGB videos should be evaluated for external validity in other data sets.
Cumulative Assessment for Urban 3D Modeling
Jul 09, 2021

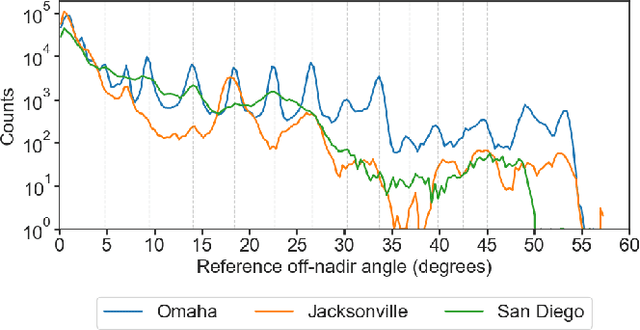
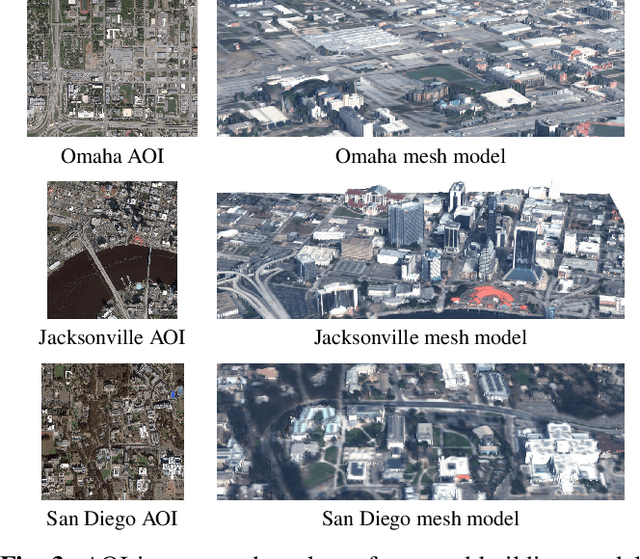
Urban 3D modeling from satellite images requires accurate semantic segmentation to delineate urban features, multiple view stereo for 3D reconstruction of surface heights, and 3D model fitting to produce compact models with accurate surface slopes. In this work, we present a cumulative assessment metric that succinctly captures error contributions from each of these components. We demonstrate our approach by providing challenging public datasets and extending two open source projects to provide an end-to-end 3D modeling baseline solution to stimulate further research and evaluation with a public leaderboard.
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
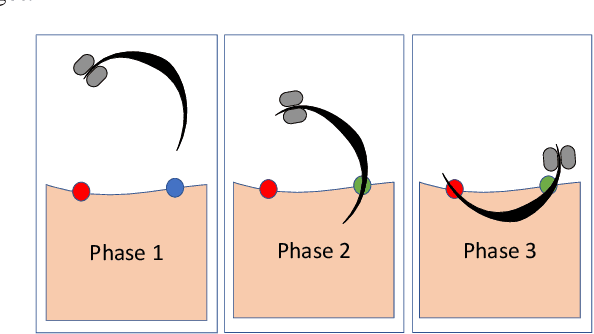
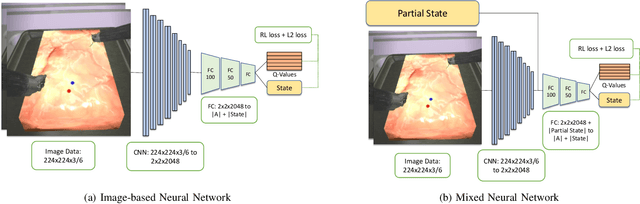
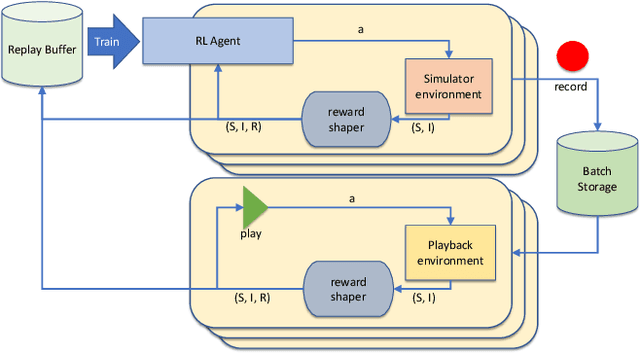
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.
From the DESK to the Battlefield -- A Robotics Exploratory Study
Nov 30, 2020
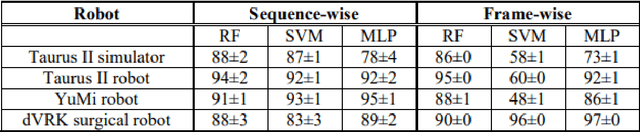
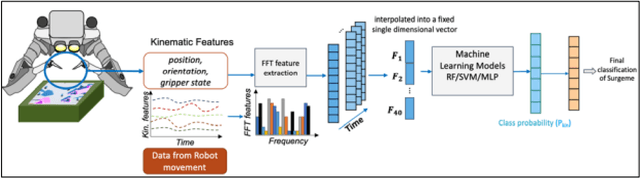
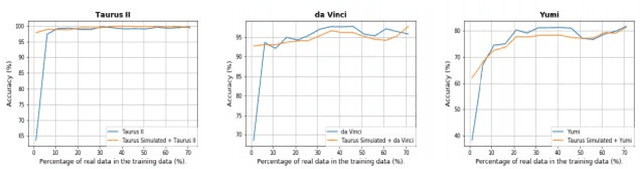
Short response time is critical for future military medical operations in austere settings or remote areas. Such effective patient care at the point of injury can greatly benefit from the integration of semi-autonomous robotic systems. To achieve autonomy, robots would require massive libraries of maneuvers. While this is possible in controlled settings, obtaining surgical data in austere settings can be difficult. Hence, in this paper, we present the Dexterous Surgical Skill (DESK) database for knowledge transfer between robots. The peg transfer task was selected as it is one of 6 main tasks of laparoscopic training. Also, we provide a ML framework to evaluate novel transfer learning methodologies on this database. The collected DESK dataset comprises a set of surgical robotic skills using the four robotic platforms: Taurus II, simulated Taurus II, YuMi, and the da Vinci Research Kit. Then, we explored two different learning scenarios: no-transfer and domain-transfer. In the no-transfer scenario, the training and testing data were obtained from the same domain; whereas in the domain-transfer scenario, the training data is a blend of simulated and real robot data that is tested on a real robot. Using simulation data enhances the performance of the real robot where limited or no real data is available. The transfer model showed an accuracy of 81% for the YuMi robot when the ratio of real-to-simulated data was 22%-78%. For Taurus II and da Vinci robots, the model showed an accuracy of 97.5% and 93% respectively, training only with simulation data. Results indicate that simulation can be used to augment training data to enhance the performance of models in real scenarios. This shows the potential for future use of surgical data from the operating room in deployable surgical robots in remote areas.
* First 3 authors share equal contribution
The Role of Robotics in Infectious Disease Crises
Oct 19, 2020The recent coronavirus pandemic has highlighted the many challenges faced by the healthcare, public safety, and economic systems when confronted with a surge in patients that require intensive treatment and a population that must be quarantined or shelter in place. The most obvious and pressing challenge is taking care of acutely ill patients while managing spread of infection within the care facility, but this is just the tip of the iceberg if we consider what could be done to prepare in advance for future pandemics. Beyond the obvious need for strengthening medical knowledge and preparedness, there is a complementary need to anticipate and address the engineering challenges associated with infectious disease emergencies. Robotic technologies are inherently programmable, and robotic systems have been adapted and deployed, to some extent, in the current crisis for such purposes as transport, logistics, and disinfection. As technical capabilities advance and as the installed base of robotic systems increases in the future, they could play a much more significant role in future crises. This report is the outcome of a virtual workshop co-hosted by the National Academy of Engineering (NAE) and the Computing Community Consortium (CCC) held on July 9-10, 2020. The workshop consisted of over forty participants including representatives from the engineering/robotics community, clinicians, critical care workers, public health and safety experts, and emergency responders. It identifies key challenges faced by healthcare responders and the general population and then identifies robotic/technological responses to these challenges. Then it identifies the key research/knowledge barriers that need to be addressed in developing effective, scalable solutions. Finally, the report ends with the following recommendations on how to implement this strategy.
Learning from Synthetic Animals
Dec 17, 2019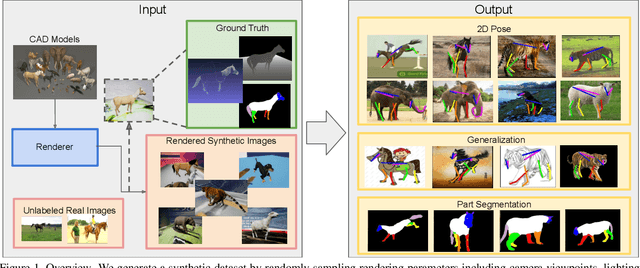
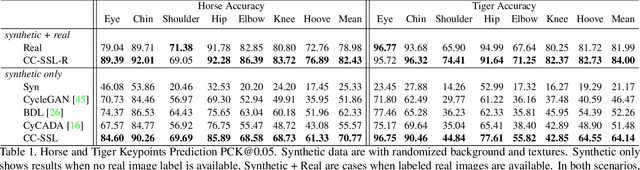
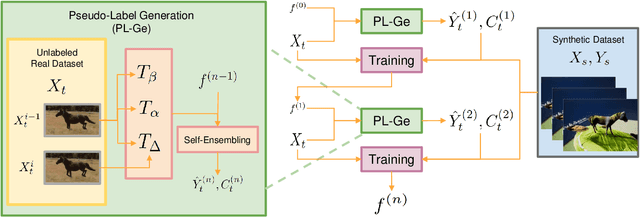

Despite great success in human parsing, progress for parsing other deformable articulated objects, like animals, is still limited by the lack of labeled data. In this paper, we use synthetic images and ground truth generated from CAD animal models to address this challenge. To bridge the gap between real and synthetic images, we propose a novel consistency-constrained semi-supervised learning method (CC-SSL). Our method leverages both spatial and temporal consistencies, to bootstrap weak models trained on synthetic data with unlabeled real images. We demonstrate the effectiveness of our method on highly deformable animals, such as horses and tigers. Without using any real image label, our method allows for accurate keypoints prediction on real images. Moreover, we quantitatively show that models using synthetic data achieve better generalization performance than models trained on real images across different domains in the Visual Domain Adaptation Challenge dataset. Our synthetic dataset contains 10+ animals with diverse poses and rich ground truth, which enables us to use the multi-task learning strategy to further boost models' performance.
Toward a Science of Autonomy for Physical Systems: Paths
Sep 19, 2016An Autonomous Physical System (APS) will be expected to reliably and independently evaluate, execute, and achieve goals while respecting surrounding rules, laws, or conventions. In doing so, an APS must rely on a broad spectrum of dynamic, complex, and often imprecise information about its surroundings, the task it is to perform, and its own sensors and actuators. For example, cleaning in a home or commercial setting requires the ability to perceive, grasp, and manipulate many physical objects, the ability to reliably perform a variety of subtasks such as washing, folding, and stacking, and knowledge about local conventions such as how objects are classified and where they should be stored. The information required for reliable autonomous operation may come from external sources and from the robot's own sensor observations or in the form of direct instruction by a trainer. Similar considerations apply across many domains - construction, manufacturing, in-home assistance, and healthcare. For example, surgeons spend many years learning about physiology and anatomy before they touch a patient. They then perform roughly 1000 surgeries under the tutelage of an expert surgeon, and they practice basic maneuvers such as suture tying thousands of times outside the operating room. All of these elements come together to achieve expertise at this task. Endowing a system with robust autonomy by traditional programming methods has thus far had limited success. Several promising new paths to acquiring and processing such data are emerging. This white paper outlines three promising research directions for enabling an APS to learn the physical and information skills necessary to perform tasks with independence and flexibility: Deep Reinforcement Learning, Human-Robot Interaction, and Cloud Robotics.
Dynamic Template Tracking and Recognition
Apr 19, 2012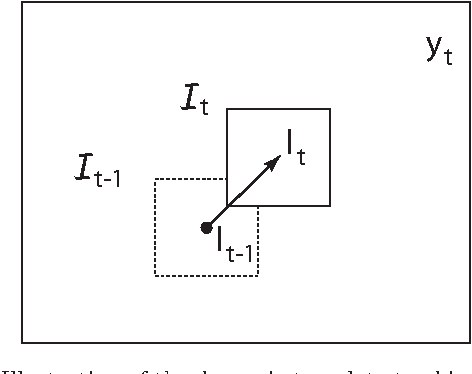
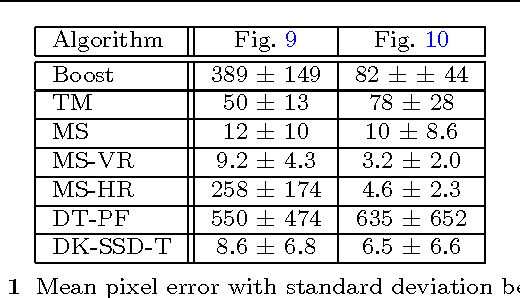
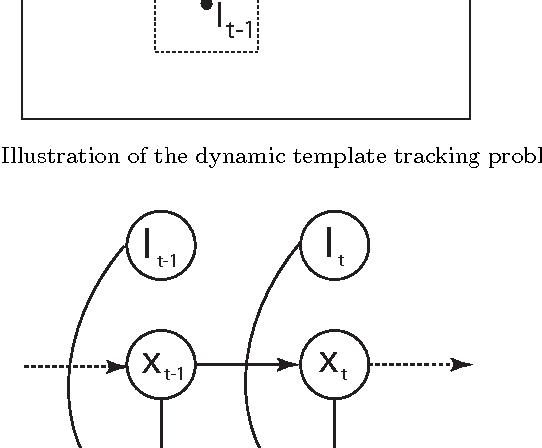
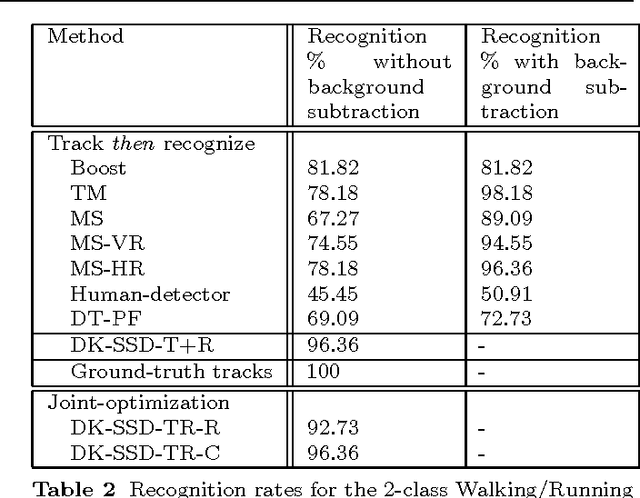
In this paper we address the problem of tracking non-rigid objects whose local appearance and motion changes as a function of time. This class of objects includes dynamic textures such as steam, fire, smoke, water, etc., as well as articulated objects such as humans performing various actions. We model the temporal evolution of the object's appearance/motion using a Linear Dynamical System (LDS). We learn such models from sample videos and use them as dynamic templates for tracking objects in novel videos. We pose the problem of tracking a dynamic non-rigid object in the current frame as a maximum a-posteriori estimate of the location of the object and the latent state of the dynamical system, given the current image features and the best estimate of the state in the previous frame. The advantage of our approach is that we can specify a-priori the type of texture to be tracked in the scene by using previously trained models for the dynamics of these textures. Our framework naturally generalizes common tracking methods such as SSD and kernel-based tracking from static templates to dynamic templates. We test our algorithm on synthetic as well as real examples of dynamic textures and show that our simple dynamics-based trackers perform at par if not better than the state-of-the-art. Since our approach is general and applicable to any image feature, we also apply it to the problem of human action tracking and build action-specific optical flow trackers that perform better than the state-of-the-art when tracking a human performing a particular action. Finally, since our approach is generative, we can use a-priori trained trackers for different texture or action classes to simultaneously track and recognize the texture or action in the video.