 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based assessment of intraoperative surgical skill
May 13, 2022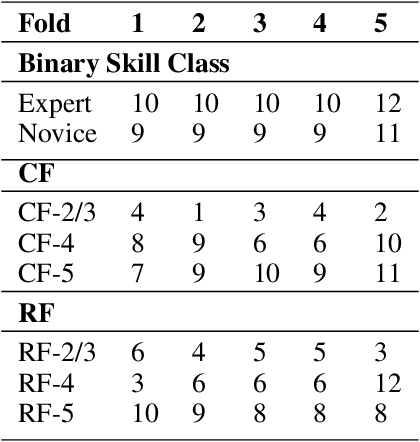
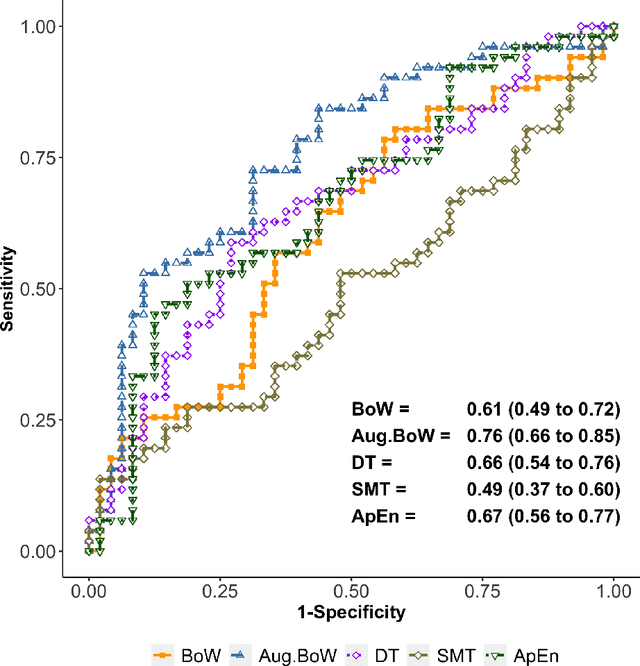
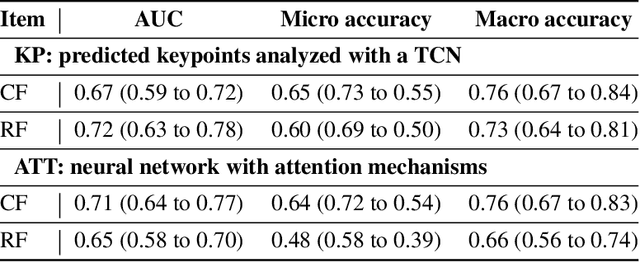
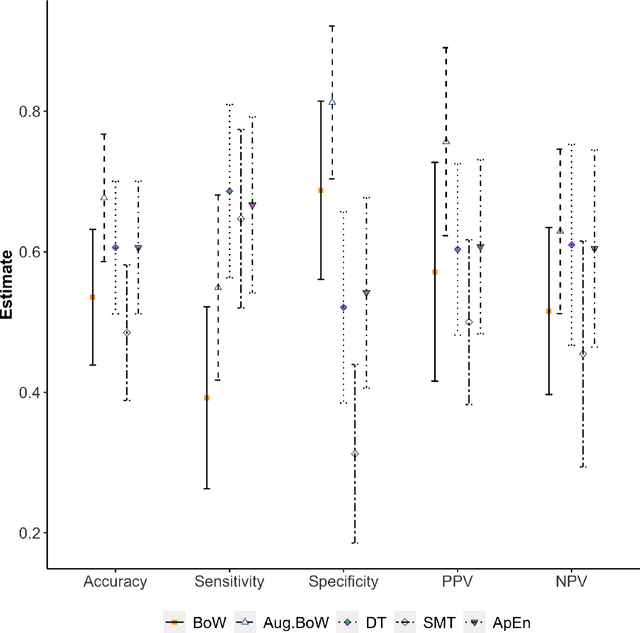
Purpose: The objective of this investigation is to provide a comprehensive analysis of state-of-the-art methods for video-based assessment of surgical skill in the operating room. Methods: Using a data set of 99 videos of capsulorhexis, a critical step in cataract surgery, we evaluate feature based methods previously developed for surgical skill assessment mostly under benchtop settings. In addition, we present and validate two deep learning methods that directly assess skill using RGB videos. In the first method, we predict instrument tips as keypoints, and learn surgical skill using temporal convolutional neural networks. In the second method, we propose a novel architecture for surgical skill assessment that includes a frame-wise encoder (2D convolutional neural network) followed by a temporal model (recurrent neural network), both of which are augmented by visual attention mechanisms. We report the area under the receiver operating characteristic curve, sensitivity, specificity, and predictive values with each method through 5-fold cross-validation. Results: For the task of binary skill classification (expert vs. novice), deep neural network based methods exhibit higher AUC than the classical spatiotemporal interest point based methods. The neural network approach using attention mechanisms also showed high sensitivity and specificity. Conclusion: Deep learning methods are necessary for video-based assessment of surgical skill in the operating room. Our findings of internal validity of a network using attention mechanisms to assess skill directly using RGB videos should be evaluated for external validity in other data sets.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

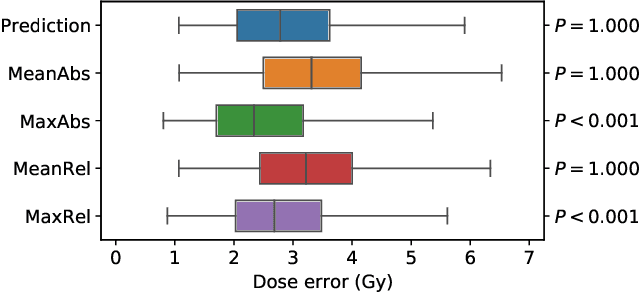
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP
Jul 26, 2021

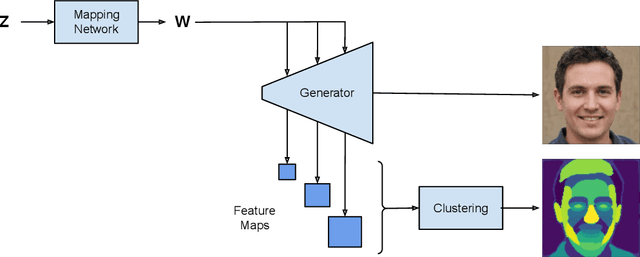
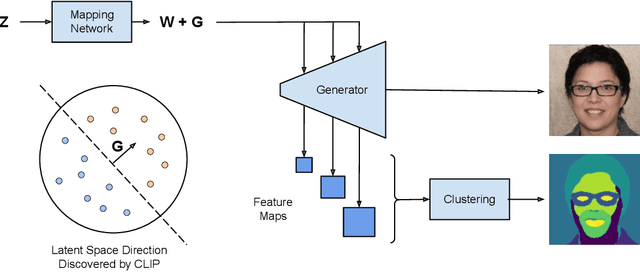
We introduce a method that allows to automatically segment images into semantically meaningful regions without human supervision. Derived regions are consistent across different images and coincide with human-defined semantic classes on some datasets. In cases where semantic regions might be hard for human to define and consistently label, our method is still able to find meaningful and consistent semantic classes. In our work, we use pretrained StyleGAN2~\cite{karras2020analyzing} generative model: clustering in the feature space of the generative model allows to discover semantic classes. Once classes are discovered, a synthetic dataset with generated images and corresponding segmentation masks can be created. After that a segmentation model is trained on the synthetic dataset and is able to generalize to real images. Additionally, by using CLIP~\cite{radford2021learning} we are able to use prompts defined in a natural language to discover some desired semantic classes. We test our method on publicly available datasets and show state-of-the-art results.
Delta Sampling R-BERT for limited data and low-light action recognition
Jul 12, 2021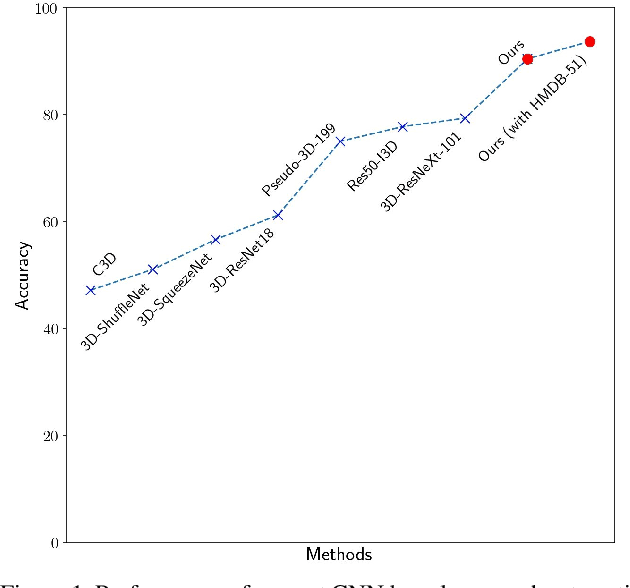


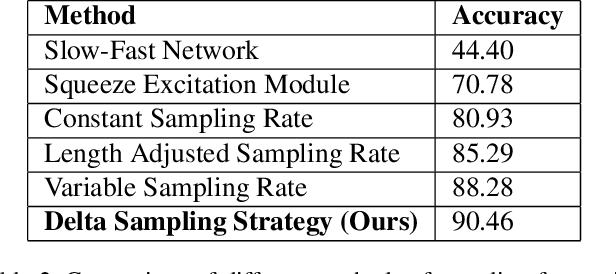
We present an approach to perform supervised action recognition in the dark. In this work, we present our results on the ARID dataset. Most previous works only evaluate performance on large, well illuminated datasets like Kinetics and HMDB51. We demonstrate that our work is able to achieve a very low error rate while being trained on a much smaller dataset of dark videos. We also explore a variety of training and inference strategies including domain transfer methodologies and also propose a simple but useful frame selection strategy. Our empirical results demonstrate that we beat previously published baseline models by 11%.