 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
PULASki: Learning inter-rater variability using statistical distances to improve probabilistic segmentation
Dec 25, 2023



In the domain of medical imaging, many supervised learning based methods for segmentation face several challenges such as high variability in annotations from multiple experts, paucity of labelled data and class imbalanced datasets. These issues may result in segmentations that lack the requisite precision for clinical analysis and can be misleadingly overconfident without associated uncertainty quantification. We propose the PULASki for biomedical image segmentation that accurately captures variability in expert annotations, even in small datasets. Our approach makes use of an improved loss function based on statistical distances in a conditional variational autoencoder structure (Probabilistic UNet), which improves learning of the conditional decoder compared to the standard cross-entropy particularly in class imbalanced problems. We analyse our method for two structurally different segmentation tasks (intracranial vessel and multiple sclerosis (MS) lesion) and compare our results to four well-established baselines in terms of quantitative metrics and qualitative output. Empirical results demonstrate the PULASKi method outperforms all baselines at the 5\% significance level. The generated segmentations are shown to be much more anatomically plausible than in the 2D case, particularly for the vessel task. Our method can also be applied to a wide range of multi-label segmentation tasks and and is useful for downstream tasks such as hemodynamic modelling (computational fluid dynamics and data assimilation), clinical decision making, and treatment planning.
Automated SSIM Regression for Detection and Quantification of Motion Artefacts in Brain MR Images
Jun 14, 2022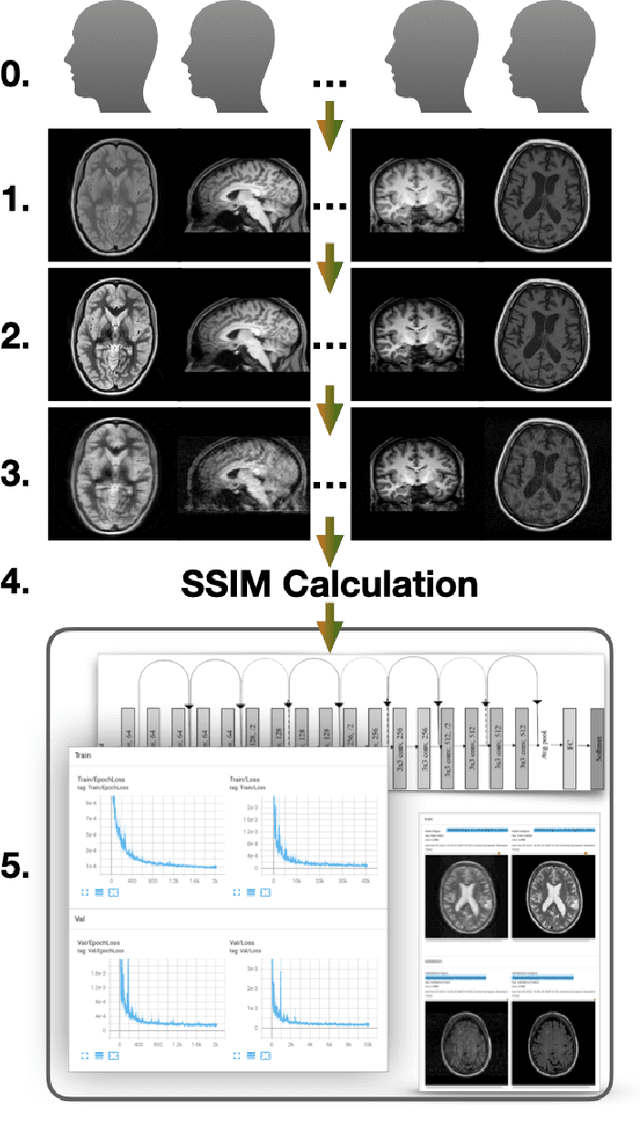
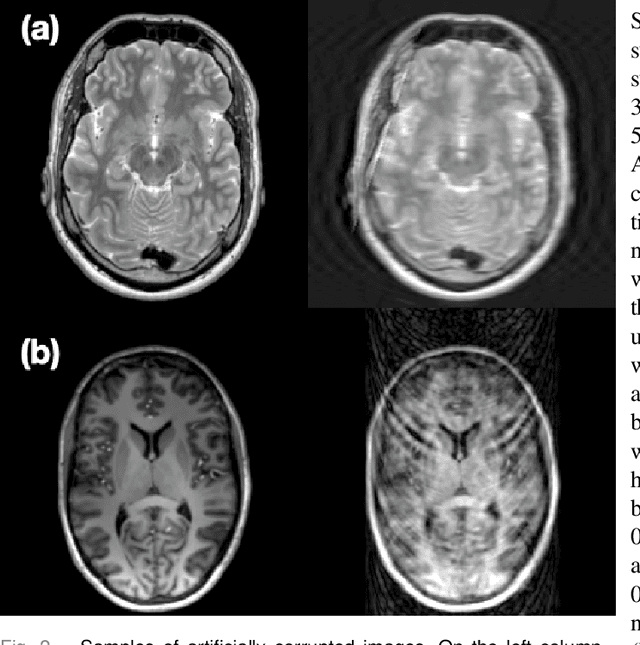
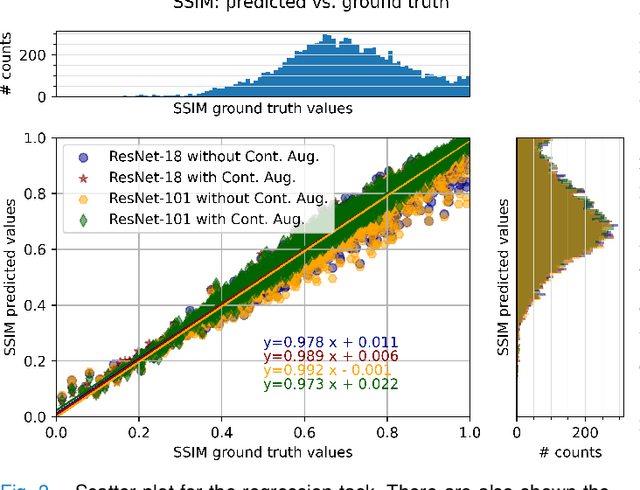
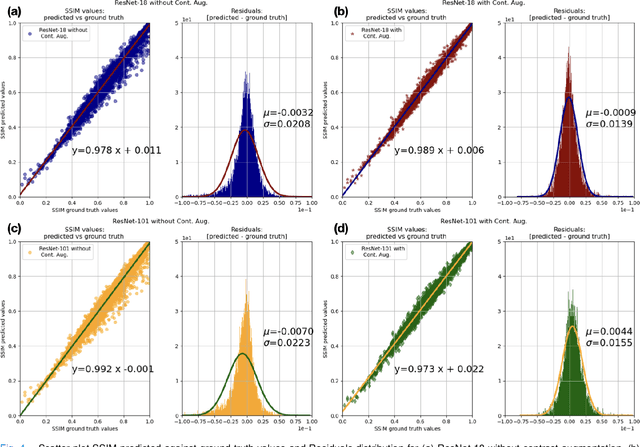
Motion artefacts in magnetic resonance brain images are a crucial issue. The assessment of MR image quality is fundamental before proceeding with the clinical diagnosis. If the motion artefacts alter a correct delineation of structure and substructures of the brain, lesions, tumours and so on, the patients need to be re-scanned. Otherwise, neuro-radiologists could report an inaccurate or incorrect diagnosis. The first step right after scanning a patient is the "\textit{image quality assessment}" in order to decide if the acquired images are diagnostically acceptable. An automated image quality assessment based on the structural similarity index (SSIM) regression through a residual neural network has been proposed here, with the possibility to perform also the classification in different groups - by subdividing with SSIM ranges. This method predicts SSIM values of an input image in the absence of a reference ground truth image. The networks were able to detect motion artefacts, and the best performance for the regression and classification task has always been achieved with ResNet-18 with contrast augmentation. Mean and standard deviation of residuals' distribution were $\mu=-0.0009$ and $\sigma=0.0139$, respectively. Whilst for the classification task in 3, 5 and 10 classes, the best accuracies were 97, 95 and 89\%, respectively. The obtained results show that the proposed method could be a tool in supporting neuro-radiologists and radiographers in evaluating the image quality before the diagnosis.
StRegA: Unsupervised Anomaly Detection in Brain MRIs using a Compact Context-encoding Variational Autoencoder
Jan 31, 2022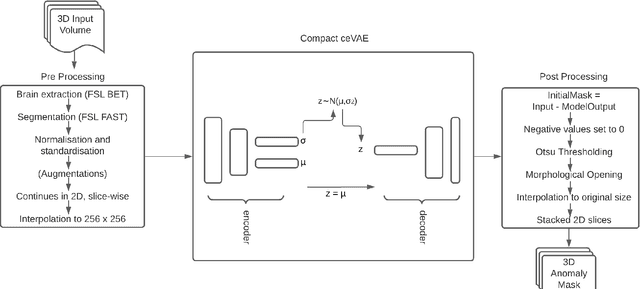



Expert interpretation of anatomical images of the human brain is the central part of neuro-radiology. Several machine learning-based techniques have been proposed to assist in the analysis process. However, the ML models typically need to be trained to perform a specific task, e.g., brain tumour segmentation or classification. Not only do the corresponding training data require laborious manual annotations, but a wide variety of abnormalities can be present in a human brain MRI - even more than one simultaneously, which renders representation of all possible anomalies very challenging. Hence, a possible solution is an unsupervised anomaly detection (UAD) system that can learn a data distribution from an unlabelled dataset of healthy subjects and then be applied to detect out of distribution samples. Such a technique can then be used to detect anomalies - lesions or abnormalities, for example, brain tumours, without explicitly training the model for that specific pathology. Several Variational Autoencoder (VAE) based techniques have been proposed in the past for this task. Even though they perform very well on controlled artificially simulated anomalies, many of them perform poorly while detecting anomalies in clinical data. This research proposes a compact version of the "context-encoding" VAE (ceVAE) model, combined with pre and post-processing steps, creating a UAD pipeline (StRegA), which is more robust on clinical data, and shows its applicability in detecting anomalies such as tumours in brain MRIs. The proposed pipeline achieved a Dice score of 0.642$\pm$0.101 while detecting tumours in T2w images of the BraTS dataset and 0.859$\pm$0.112 while detecting artificially induced anomalies, while the best performing baseline achieved 0.522$\pm$0.135 and 0.783$\pm$0.111, respectively.
ShuffleUNet: Super resolution of diffusion-weighted MRIs using deep learning
Feb 25, 2021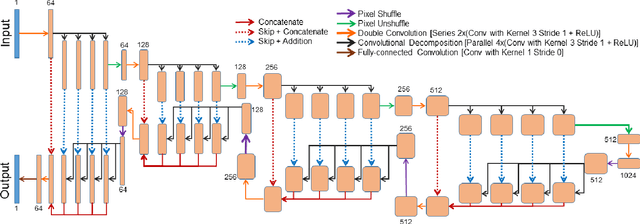
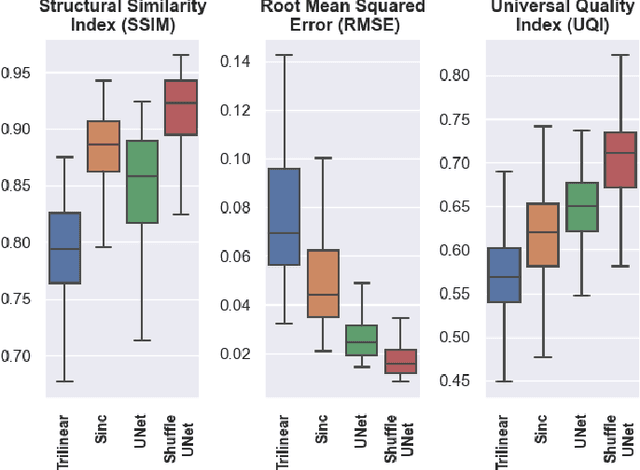
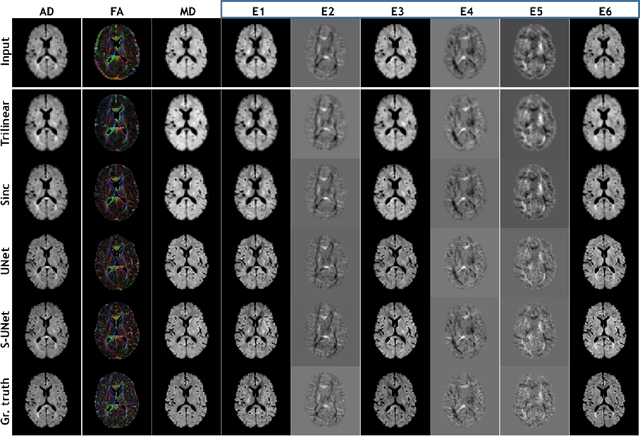
Diffusion-weighted magnetic resonance imaging (DW-MRI) can be used to characterise the microstructure of the nervous tissue, e.g. to delineate brain white matter connections in a non-invasive manner via fibre tracking. Magnetic Resonance Imaging (MRI) in high spatial resolution would play an important role in visualising such fibre tracts in a superior manner. However, obtaining an image of such resolution comes at the expense of longer scan time. Longer scan time can be associated with the increase of motion artefacts, due to the patient's psychological and physical conditions. Single Image Super-Resolution (SISR), a technique aimed to obtain high-resolution (HR) details from one single low-resolution (LR) input image, achieved with Deep Learning, is the focus of this study. Compared to interpolation techniques or sparse-coding algorithms, deep learning extracts prior knowledge from big datasets and produces superior MRI images from the low-resolution counterparts. In this research, a deep learning based super-resolution technique is proposed and has been applied for DW-MRI. Images from the IXI dataset have been used as the ground-truth and were artificially downsampled to simulate the low-resolution images. The proposed method has shown statistically significant improvement over the baselines and achieved an SSIM of $0.913\pm0.045$.
Retrospective Motion Correction of MR Images using Prior-Assisted Deep Learning
Nov 28, 2020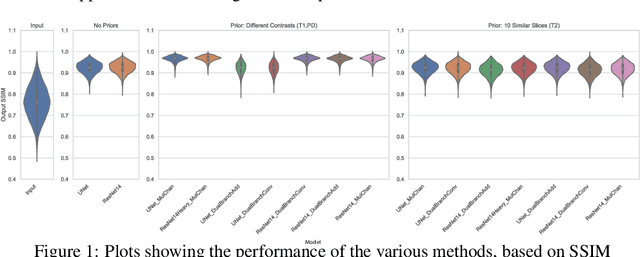
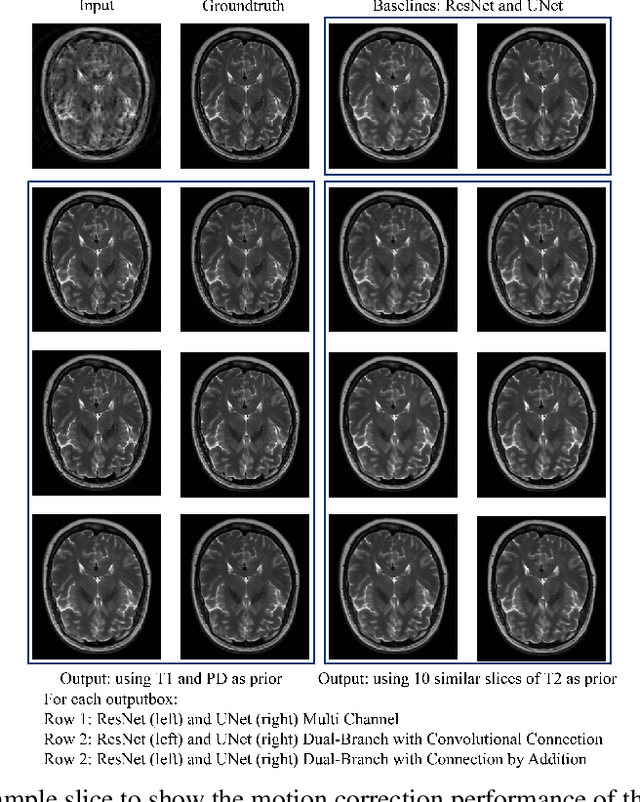
In MRI, motion artefacts are among the most common types of artefacts. They can degrade images and render them unusable for accurate diagnosis. Traditional methods, such as prospective or retrospective motion correction, have been proposed to avoid or alleviate motion artefacts. Recently, several other methods based on deep learning approaches have been proposed to solve this problem. This work proposes to enhance the performance of existing deep learning models by the inclusion of additional information present as image priors. The proposed approach has shown promising results and will be further investigated for clinical validity.