 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models
Oct 16, 2021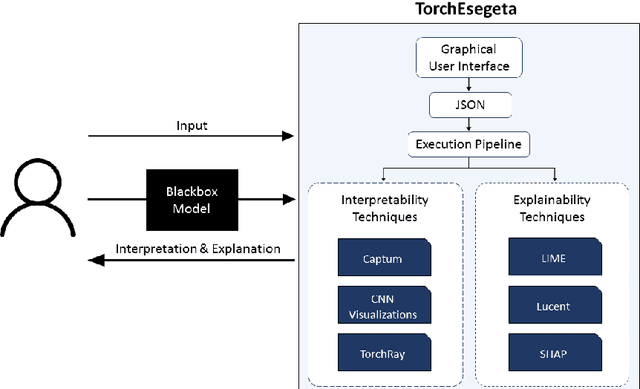
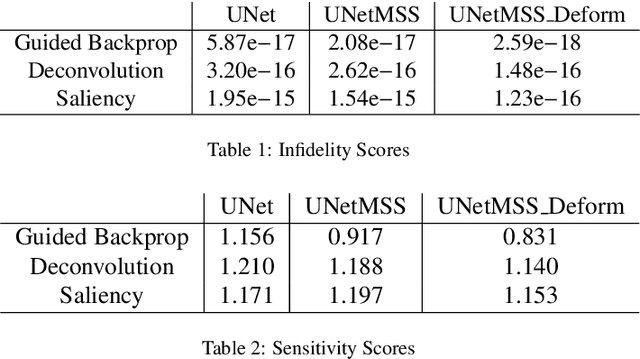
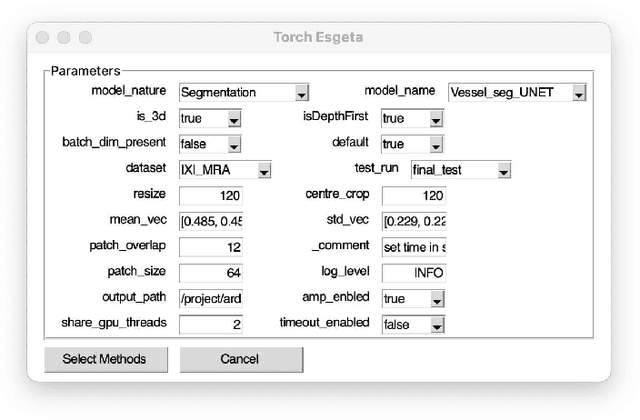
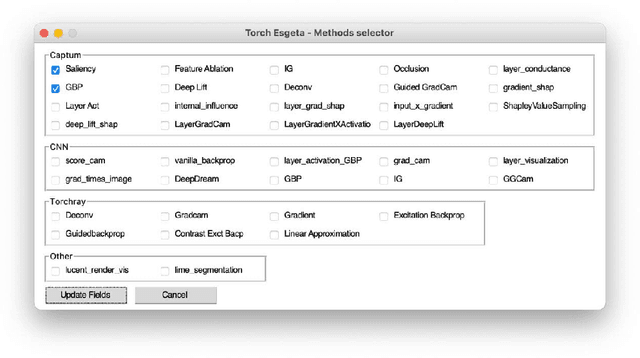
Clinicians are often very sceptical about applying automatic image processing approaches, especially deep learning based methods, in practice. One main reason for this is the black-box nature of these approaches and the inherent problem of missing insights of the automatically derived decisions. In order to increase trust in these methods, this paper presents approaches that help to interpret and explain the results of deep learning algorithms by depicting the anatomical areas which influence the decision of the algorithm most. Moreover, this research presents a unified framework, TorchEsegeta, for applying various interpretability and explainability techniques for deep learning models and generate visual interpretations and explanations for clinicians to corroborate their clinical findings. In addition, this will aid in gaining confidence in such methods. The framework builds on existing interpretability and explainability techniques that are currently focusing on classification models, extending them to segmentation tasks. In addition, these methods have been adapted to 3D models for volumetric analysis. The proposed framework provides methods to quantitatively compare visual explanations using infidelity and sensitivity metrics. This framework can be used by data scientists to perform post-hoc interpretations and explanations of their models, develop more explainable tools and present the findings to clinicians to increase their faith in such models. The proposed framework was evaluated based on a use case scenario of vessel segmentation models trained on Time-of-fight (TOF) Magnetic Resonance Angiogram (MRA) images of the human brain. Quantitative and qualitative results of a comparative study of different models and interpretability methods are presented. Furthermore, this paper provides an extensive overview of several existing interpretability and explainability methods.
ShuffleUNet: Super resolution of diffusion-weighted MRIs using deep learning
Feb 25, 2021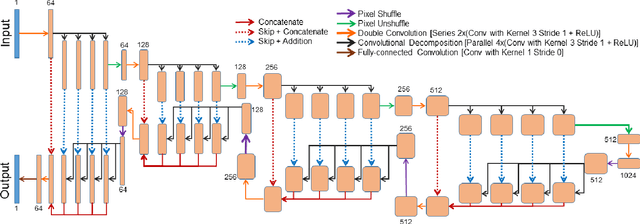
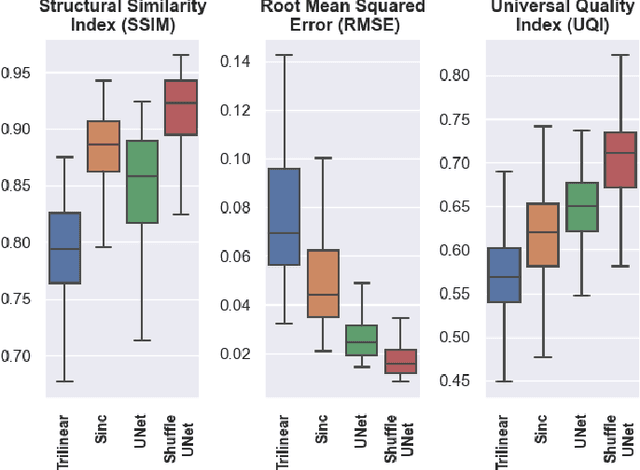
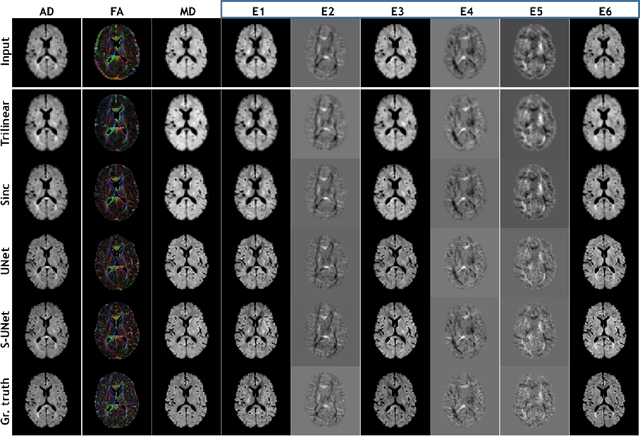
Diffusion-weighted magnetic resonance imaging (DW-MRI) can be used to characterise the microstructure of the nervous tissue, e.g. to delineate brain white matter connections in a non-invasive manner via fibre tracking. Magnetic Resonance Imaging (MRI) in high spatial resolution would play an important role in visualising such fibre tracts in a superior manner. However, obtaining an image of such resolution comes at the expense of longer scan time. Longer scan time can be associated with the increase of motion artefacts, due to the patient's psychological and physical conditions. Single Image Super-Resolution (SISR), a technique aimed to obtain high-resolution (HR) details from one single low-resolution (LR) input image, achieved with Deep Learning, is the focus of this study. Compared to interpolation techniques or sparse-coding algorithms, deep learning extracts prior knowledge from big datasets and produces superior MRI images from the low-resolution counterparts. In this research, a deep learning based super-resolution technique is proposed and has been applied for DW-MRI. Images from the IXI dataset have been used as the ground-truth and were artificially downsampled to simulate the low-resolution images. The proposed method has shown statistically significant improvement over the baselines and achieved an SSIM of $0.913\pm0.045$.