 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDoS-UNet: Incorporating temporal information using Dynamic Dual-channel UNet for enhancing super-resolution of dynamic MRI
Feb 10, 2022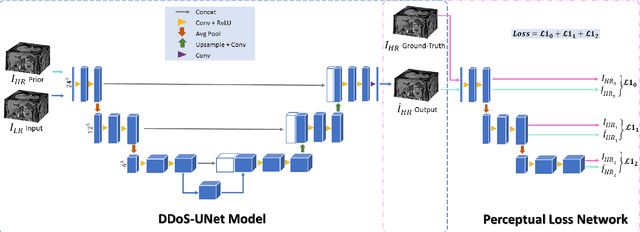
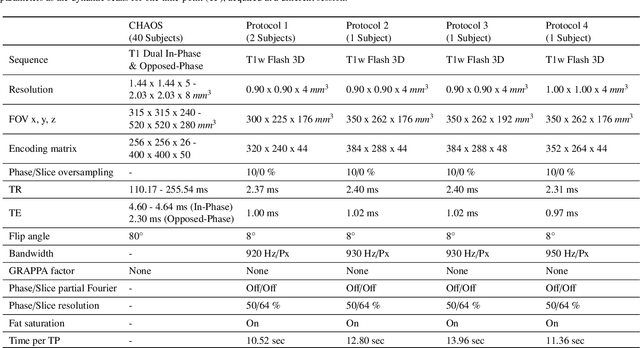

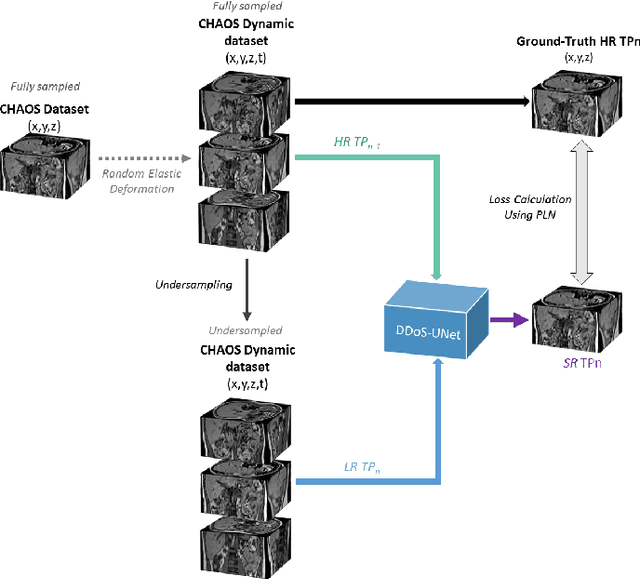
Magnetic resonance imaging (MRI) provides high spatial resolution and excellent soft-tissue contrast without using harmful ionising radiation. Dynamic MRI is an essential tool for interventions to visualise movements or changes of the target organ. However, such MRI acquisition with high temporal resolution suffers from limited spatial resolution - also known as the spatio-temporal trade-off of dynamic MRI. Several approaches, including deep learning based super-resolution approaches, have been proposed to mitigate this trade-off. Nevertheless, such an approach typically aims to super-resolve each time-point separately, treating them as individual volumes. This research addresses the problem by creating a deep learning model which attempts to learn both spatial and temporal relationships. A modified 3D UNet model, DDoS-UNet, is proposed - which takes the low-resolution volume of the current time-point along with a prior image volume. Initially, the network is supplied with a static high-resolution planning scan as the prior image along with the low-resolution input to super-resolve the first time-point. Then it continues step-wise by using the super-resolved time-points as the prior image while super-resolving the subsequent time-points. The model performance was tested with 3D dynamic data that was undersampled to different in-plane levels. The proposed network achieved an average SSIM value of 0.951$\pm$0.017 while reconstructing the lowest resolution data (i.e. only 4\% of the k-space acquired) - which could result in a theoretical acceleration factor of 25. The proposed approach can be used to reduce the required scan-time while achieving high spatial resolution.
TorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models
Oct 16, 2021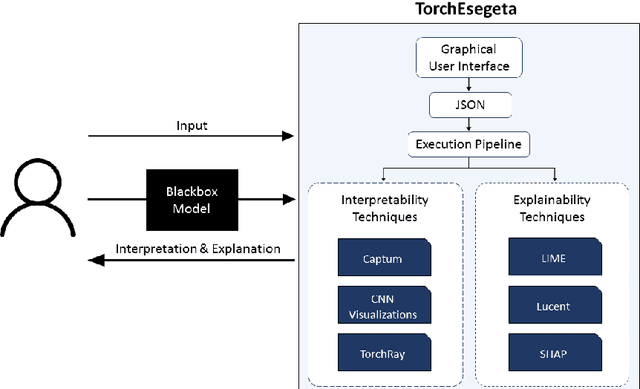
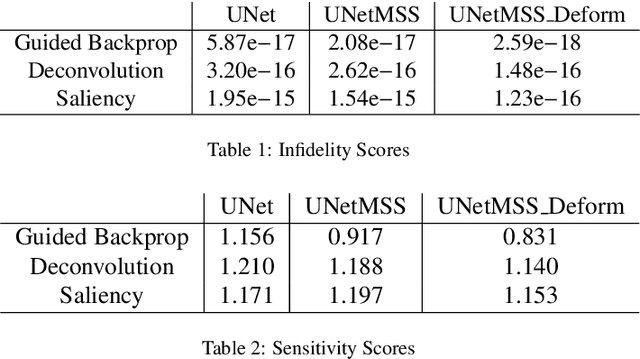
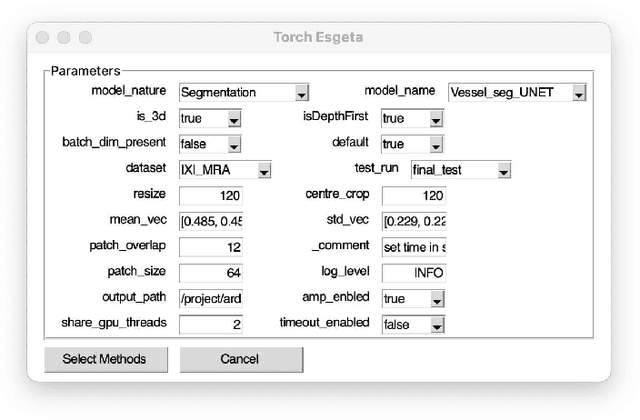
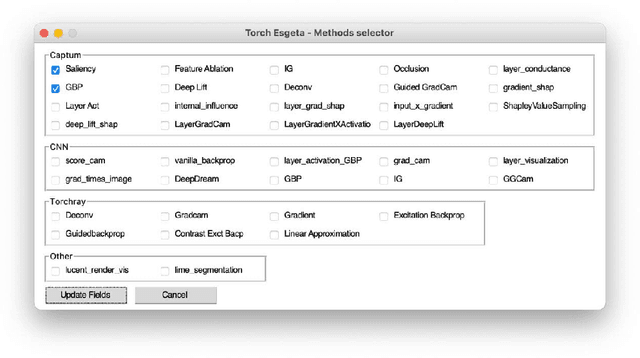
Clinicians are often very sceptical about applying automatic image processing approaches, especially deep learning based methods, in practice. One main reason for this is the black-box nature of these approaches and the inherent problem of missing insights of the automatically derived decisions. In order to increase trust in these methods, this paper presents approaches that help to interpret and explain the results of deep learning algorithms by depicting the anatomical areas which influence the decision of the algorithm most. Moreover, this research presents a unified framework, TorchEsegeta, for applying various interpretability and explainability techniques for deep learning models and generate visual interpretations and explanations for clinicians to corroborate their clinical findings. In addition, this will aid in gaining confidence in such methods. The framework builds on existing interpretability and explainability techniques that are currently focusing on classification models, extending them to segmentation tasks. In addition, these methods have been adapted to 3D models for volumetric analysis. The proposed framework provides methods to quantitatively compare visual explanations using infidelity and sensitivity metrics. This framework can be used by data scientists to perform post-hoc interpretations and explanations of their models, develop more explainable tools and present the findings to clinicians to increase their faith in such models. The proposed framework was evaluated based on a use case scenario of vessel segmentation models trained on Time-of-fight (TOF) Magnetic Resonance Angiogram (MRA) images of the human brain. Quantitative and qualitative results of a comparative study of different models and interpretability methods are presented. Furthermore, this paper provides an extensive overview of several existing interpretability and explainability methods.
ReconResNet: Regularised Residual Learning for MR Image Reconstruction of Undersampled Cartesian and Radial Data
Mar 16, 2021
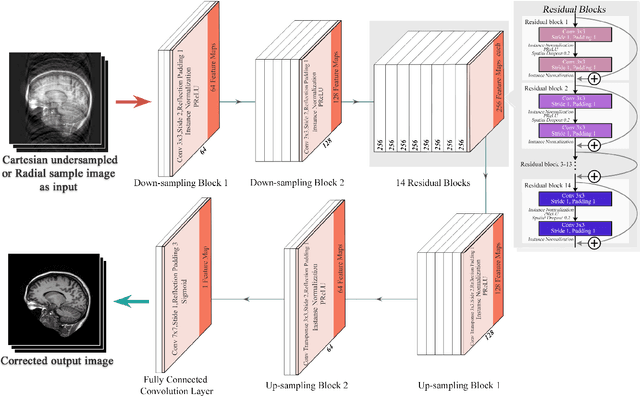
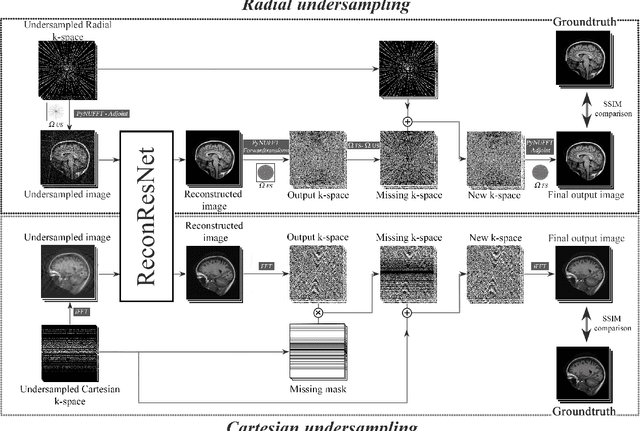
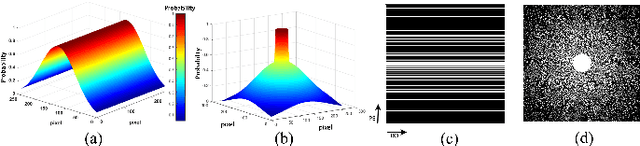
MRI is an inherently slow process, which leads to long scan time for high-resolution imaging. The speed of acquisition can be increased by ignoring parts of the data (undersampling). Consequently, this leads to the degradation of image quality, such as loss of resolution or introduction of image artefacts. This work aims to reconstruct highly undersampled Cartesian or radial MR acquisitions, with better resolution and with less to no artefact compared to conventional techniques like compressed sensing. In recent times, deep learning has emerged as a very important area of research and has shown immense potential in solving inverse problems, e.g. MR image reconstruction. In this paper, a deep learning based MR image reconstruction framework is proposed, which includes a modified regularised version of ResNet as the network backbone to remove artefacts from the undersampled image, followed by data consistency steps that fusions the network output with the data already available from undersampled k-space in order to further improve reconstruction quality. The performance of this framework for various undersampling patterns has also been tested, and it has been observed that the framework is robust to deal with various sampling patterns, even when mixed together while training, and results in very high quality reconstruction, in terms of high SSIM (highest being 0.990$\pm$0.006 for acceleration factor of 3.5), while being compared with the fully sampled reconstruction. It has been shown that the proposed framework can successfully reconstruct even for an acceleration factor of 20 for Cartesian (0.968$\pm$0.005) and 17 for radially (0.962$\pm$0.012) sampled data. Furthermore, it has been shown that the framework preserves brain pathology during reconstruction while being trained on healthy subjects.
Fine-tuning deep learning model parameters for improved super-resolution of dynamic MRI with prior-knowledge
Feb 04, 2021



Dynamic imaging is a beneficial tool for interventions to assess physiological changes. Nonetheless during dynamic MRI, while achieving a high temporal resolution, the spatial resolution is compromised. To overcome this spatio-temporal trade-off, this research presents a super-resolution (SR) MRI reconstruction with prior knowledge based fine-tuning to maximise spatial information while preserving high temporal resolution of dynamic MRI. An U-Net based network with perceptual loss is trained on a benchmark dataset and fine-tuned using one subject-specific static high resolution MRI as prior knowledge to obtain high resolution dynamic images during the inference stage. 3D dynamic data for three subjects were acquired with different parameters to test the generalisation capabilities of the network. The method was tested for different levels of in-plane undersampling for dynamic MRI. The reconstructed dynamic SR results showed higher similarity with the high resolution ground-truth after fine-tuning. The average SSIM of the lowest resolution experimented during this research (6.25~\% of the k-space) before and after fine-tuning were 0.939 $\pm$ 0.008 and 0.957 $\pm$ 0.006 respectively. This could theoretically result in an acceleration factor of 16, which can potentially be acquired in less than half a second. The proposed approach shows that the super-resolution MRI reconstruction with prior-information can alleviate the spatio-temporal trade-off in dynamic MRI, even for high acceleration factors.
Exploration of Interpretability Techniques for Deep COVID-19 Classification using Chest X-ray Images
Jun 10, 2020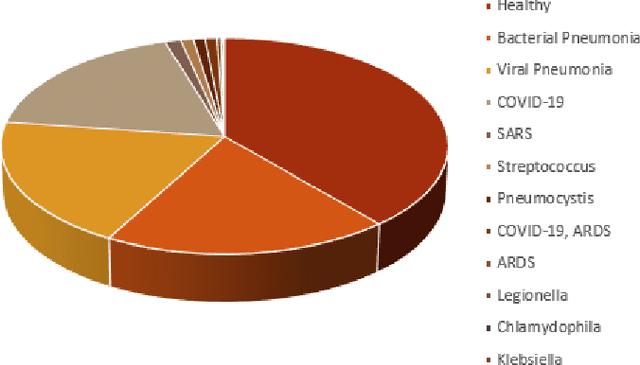
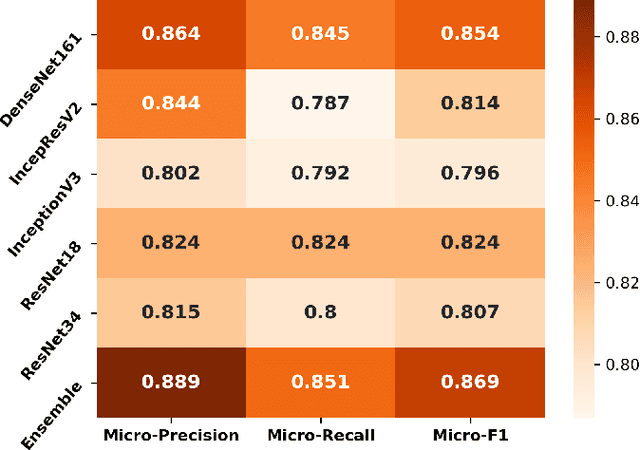
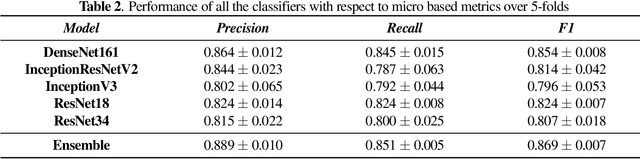
The outbreak of COVID-19 has shocked the entire world with its fairly rapid spread and has challenged different sectors. One of the most effective ways to limit its spread is the early and accurate diagnosis of infected patients. Medical imaging such as X-ray and Computed Tomography (CT) combined with the potential of Artificial Intelligence (AI) plays an essential role in supporting the medical staff in the diagnosis process. Thereby, the use of five different deep learning models (ResNet18, ResNet34, InceptionV3, InceptionResNetV2, and DenseNet161) and their Ensemble have been used in this paper, to classify COVID-19, pneumoni{\ae} and healthy subjects using Chest X-Ray. Multi-label classification was performed to predict multiple pathologies for each patient, if present. Foremost, the interpretability of each of the networks was thoroughly studied using techniques like occlusion, saliency, input X gradient, guided backpropagation, integrated gradients, and DeepLIFT. The mean Micro-F1 score of the models for COVID-19 classifications ranges from 0.66 to 0.875, and is 0.89 for the Ensemble of the network models. The qualitative results depicted the ResNets to be the most interpretable model.
Breathing deformation model -- application to multi-resolution abdominal MRI
Oct 10, 2019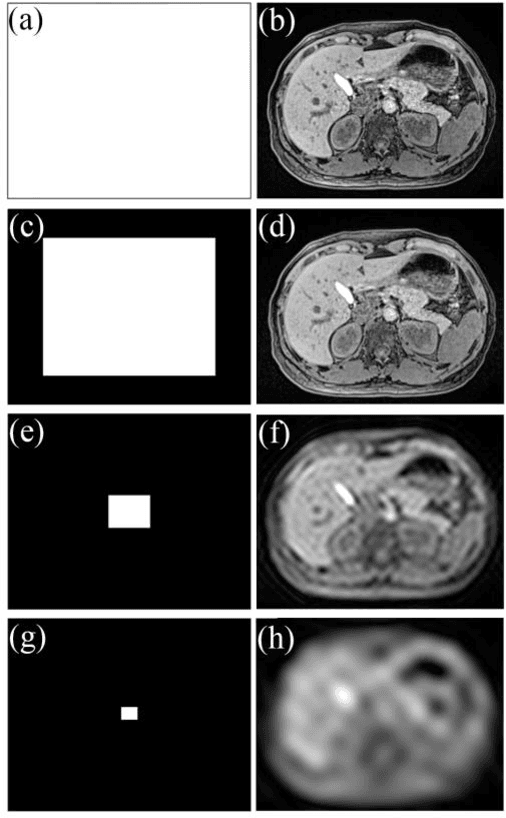

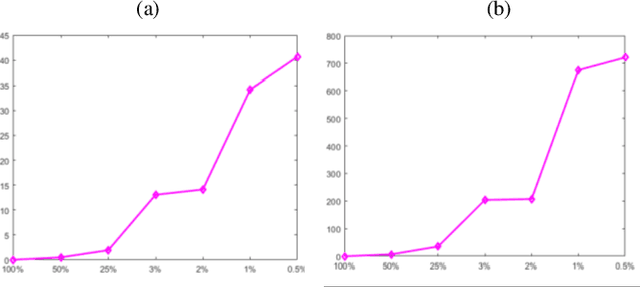
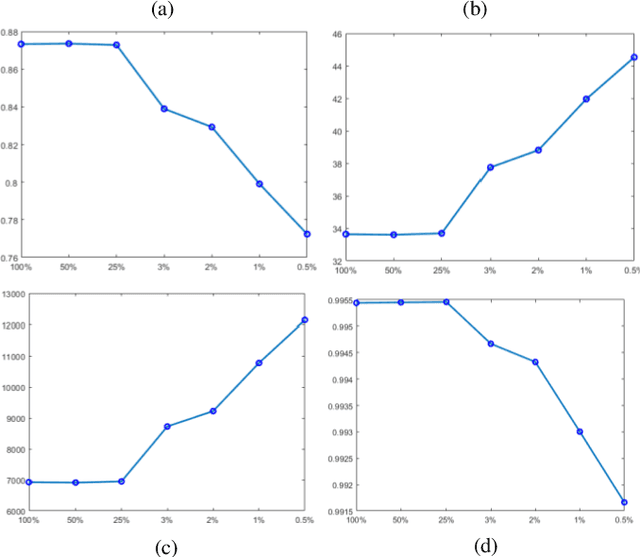
Dynamic MRI is a technique of acquiring a series of images continuously to follow the physiological changes over time. However, such fast imaging results in low resolution images. In this work, abdominal deformation model computed from dynamic low resolution images have been applied to high resolution image, acquired previously, to generate dynamic high resolution MRI. Dynamic low resolution images were simulated into different breathing phases (inhale and exhale). Then, the image registration between breathing time points was performed using the B-spline SyN deformable model and using cross-correlation as a similarity metric. The deformation model between different breathing phases were estimated from highly undersampled data. This deformation model was then applied to the high resolution images to obtain high resolution images of different breathing phases. The results indicated that the deformation model could be computed from relatively very low resolution images.