 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnonymising Elderly and Pathological Speech: Voice Conversion Using DDSP and Query-by-Example
Oct 20, 2024



Speech anonymisation aims to protect speaker identity by changing personal identifiers in speech while retaining linguistic content. Current methods fail to retain prosody and unique speech patterns found in elderly and pathological speech domains, which is essential for remote health monitoring. To address this gap, we propose a voice conversion-based method (DDSP-QbE) using differentiable digital signal processing and query-by-example. The proposed method, trained with novel losses, aids in disentangling linguistic, prosodic, and domain representations, enabling the model to adapt to uncommon speech patterns. Objective and subjective evaluations show that DDSP-QbE significantly outperforms the voice conversion state-of-the-art concerning intelligibility, prosody, and domain preservation across diverse datasets, pathologies, and speakers while maintaining quality and speaker anonymity. Experts validate domain preservation by analysing twelve clinically pertinent domain attributes.
Improving Voice Quality in Speech Anonymization With Just Perception-Informed Losses
Oct 20, 2024


The increasing use of cloud-based speech assistants has heightened the need for effective speech anonymization, which aims to obscure a speaker's identity while retaining critical information for subsequent tasks. One approach to achieving this is through voice conversion. While existing methods often emphasize complex architectures and training techniques, our research underscores the importance of loss functions inspired by the human auditory system. Our proposed loss functions are model-agnostic, incorporating handcrafted and deep learning-based features to effectively capture quality representations. Through objective and subjective evaluations, we demonstrate that a VQVAE-based model, enhanced with our perception-driven losses, surpasses the vanilla model in terms of naturalness, intelligibility, and prosody while maintaining speaker anonymity. These improvements are consistently observed across various datasets, languages, target speakers, and genders.
PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
Sep 22, 2023



The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.
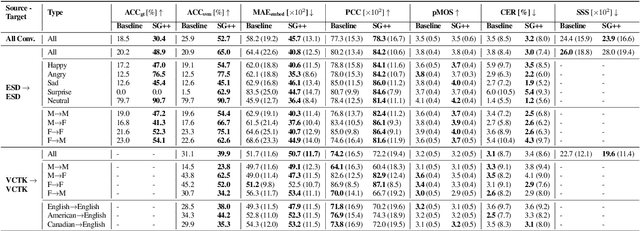
Improving Voice Conversion for Dissimilar Speakers Using Perceptual Losses
Sep 18, 2023The rising trend of using voice as a means of interacting with smart devices has sparked worries over the protection of users' privacy and data security. These concerns have become more pressing, especially after the European Union's adoption of the General Data Protection Regulation (GDPR). The information contained in an utterance encompasses critical personal details about the speaker, such as their age, gender, socio-cultural origins and more. If there is a security breach and the data is compromised, attackers may utilise the speech data to circumvent the speaker verification systems or imitate authorised users. Therefore, it is pertinent to anonymise the speech data before being shared across devices, such that the source speaker of the utterance cannot be traced. Voice conversion (VC) can be used to achieve speech anonymisation, which involves altering the speaker's characteristics while preserving the linguistic content.
Emo-StarGAN: A Semi-Supervised Any-to-Many Non-Parallel Emotion-Preserving Voice Conversion
Sep 14, 2023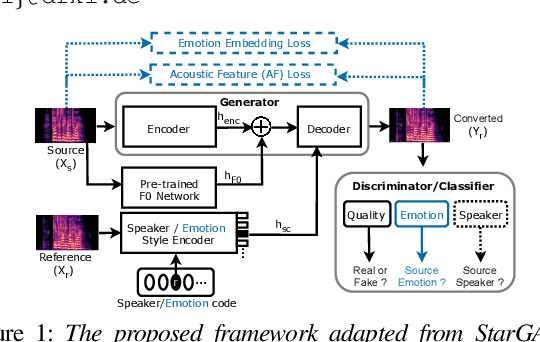
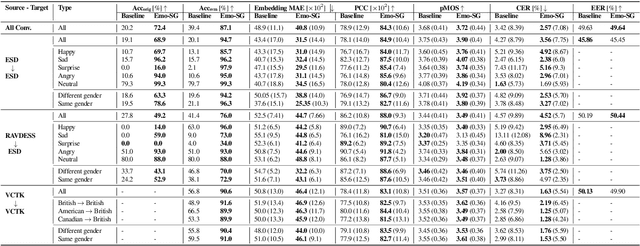
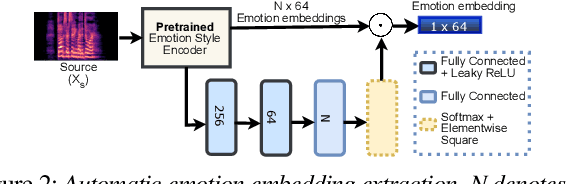
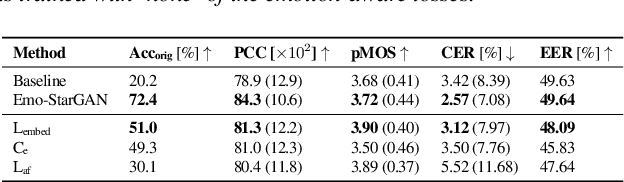
Speech anonymisation prevents misuse of spoken data by removing any personal identifier while preserving at least linguistic content. However, emotion preservation is crucial for natural human-computer interaction. The well-known voice conversion technique StarGANv2-VC achieves anonymisation but fails to preserve emotion. This work presents an any-to-many semi-supervised StarGANv2-VC variant trained on partially emotion-labelled non-parallel data. We propose emotion-aware losses computed on the emotion embeddings and acoustic features correlated to emotion. Additionally, we use an emotion classifier to provide direct emotion supervision. Objective and subjective evaluations show that the proposed approach significantly improves emotion preservation over the vanilla StarGANv2-VC. This considerable improvement is seen over diverse datasets, emotions, target speakers, and inter-group conversions without compromising intelligibility and anonymisation.
StarGAN-VC++: Towards Emotion Preserving Voice Conversion Using Deep Embeddings
Sep 14, 2023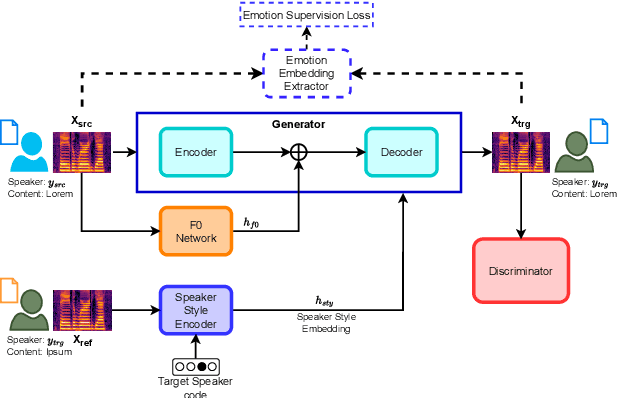

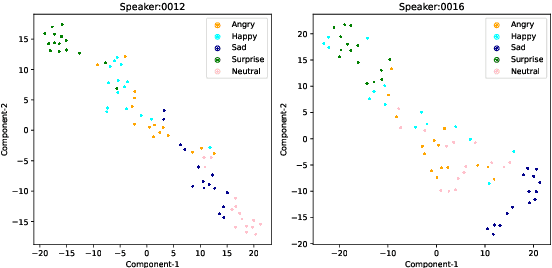
Voice conversion (VC) transforms an utterance to sound like another person without changing the linguistic content. A recently proposed generative adversarial network-based VC method, StarGANv2-VC is very successful in generating natural-sounding conversions. However, the method fails to preserve the emotion of the source speaker in the converted samples. Emotion preservation is necessary for natural human-computer interaction. In this paper, we show that StarGANv2-VC fails to disentangle the speaker and emotion representations, pertinent to preserve emotion. Specifically, there is an emotion leakage from the reference audio used to capture the speaker embeddings while training. To counter the problem, we propose novel emotion-aware losses and an unsupervised method which exploits emotion supervision through latent emotion representations. The objective and subjective evaluations prove the efficacy of the proposed strategy over diverse datasets, emotions, gender, etc.
Dual Branch Prior-SegNet: CNN for Interventional CBCT using Planning Scan and Auxiliary Segmentation Loss
May 11, 2022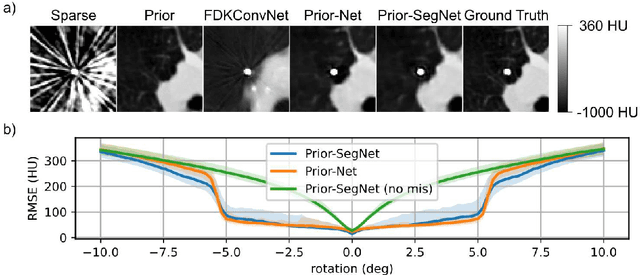
This paper proposes an extension to the Dual Branch Prior-Net for sparse view interventional CBCT reconstruction incorporating a high quality planning scan. An additional head learns to segment interventional instruments and thus guides the reconstruction task. The prior scans are misaligned by up to +-5deg in-plane during training. Experiments show that the proposed model, Dual Branch Prior-SegNet, significantly outperforms any other evaluated model by >2.8dB PSNR. It also stays robust wrt. rotations of up to +-5.5deg.
Predictive coding, precision and natural gradients
Nov 12, 2021There is an increasing convergence between biologically plausible computational models of inference and learning with local update rules and the global gradient-based optimization of neural network models employed in machine learning. One particularly exciting connection is the correspondence between the locally informed optimization in predictive coding networks and the error backpropagation algorithm that is used to train state-of-the-art deep artificial neural networks. Here we focus on the related, but still largely under-explored connection between precision weighting in predictive coding networks and the Natural Gradient Descent algorithm for deep neural networks. Precision-weighted predictive coding is an interesting candidate for scaling up uncertainty-aware optimization -- particularly for models with large parameter spaces -- due to its distributed nature of the optimization process and the underlying local approximation of the Fisher information metric, the adaptive learning rate that is central to Natural Gradient Descent. Here, we show that hierarchical predictive coding networks with learnable precision indeed are able to solve various supervised and unsupervised learning tasks with performance comparable to global backpropagation with natural gradients and outperform their classical gradient descent counterpart on tasks where high amounts of noise are embedded in data or label inputs. When applied to unsupervised auto-encoding of image inputs, the deterministic network produces hierarchically organized and disentangled embeddings, hinting at the close connections between predictive coding and hierarchical variational inference.
Uncertainty-Aware Temporal Self-Learning (UATS): Semi-Supervised Learning for Segmentation of Prostate Zones and Beyond
Apr 08, 2021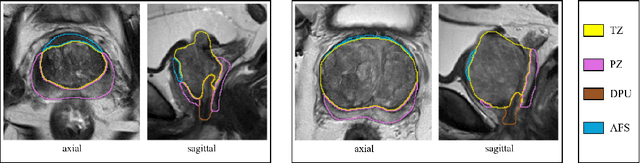
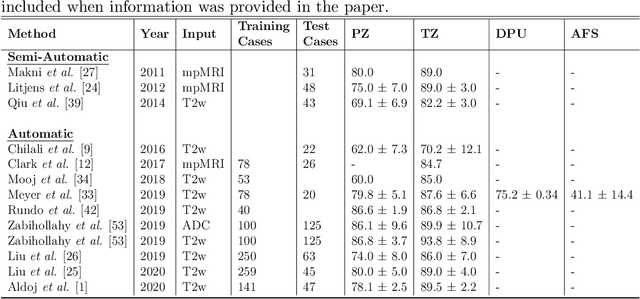
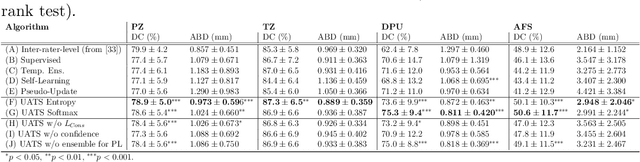
Various convolutional neural network (CNN) based concepts have been introduced for the prostate's automatic segmentation and its coarse subdivision into transition zone (TZ) and peripheral zone (PZ). However, when targeting a fine-grained segmentation of TZ, PZ, distal prostatic urethra (DPU) and the anterior fibromuscular stroma (AFS), the task becomes more challenging and has not yet been solved at the level of human performance. One reason might be the insufficient amount of labeled data for supervised training. Therefore, we propose to apply a semi-supervised learning (SSL) technique named uncertainty-aware temporal self-learning (UATS) to overcome the expensive and time-consuming manual ground truth labeling. We combine the SSL techniques temporal ensembling and uncertainty-guided self-learning to benefit from unlabeled images, which are often readily available. Our method significantly outperforms the supervised baseline and obtained a Dice coefficient (DC) of up to 78.9% , 87.3%, 75.3%, 50.6% for TZ, PZ, DPU and AFS, respectively. The obtained results are in the range of human inter-rater performance for all structures. Moreover, we investigate the method's robustness against noise and demonstrate the generalization capability for varying ratios of labeled data and on other challenging tasks, namely the hippocampus and skin lesion segmentation. UATS achieved superiority segmentation quality compared to the supervised baseline, particularly for minimal amounts of labeled data.
Exploration of Interpretability Techniques for Deep COVID-19 Classification using Chest X-ray Images
Jun 10, 2020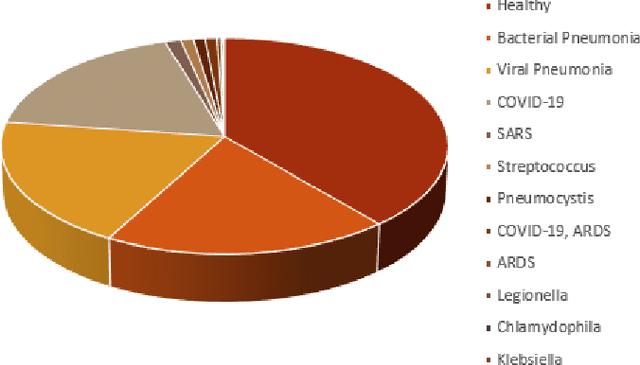
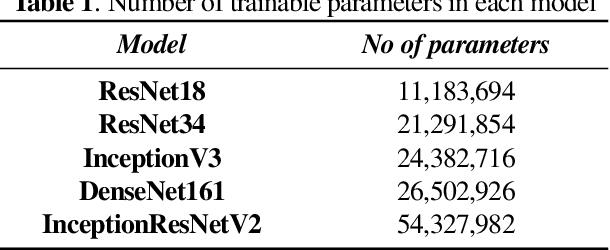
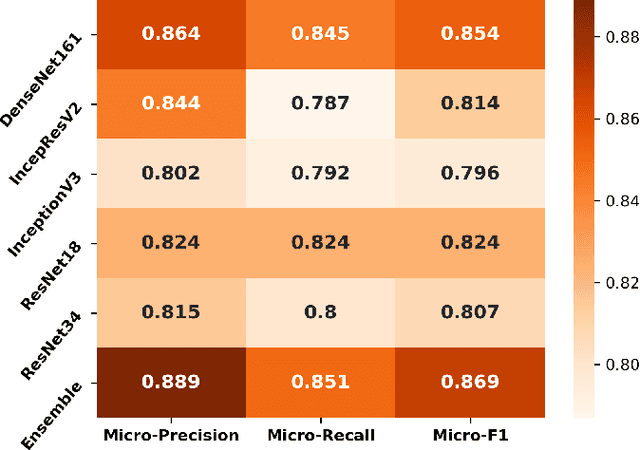
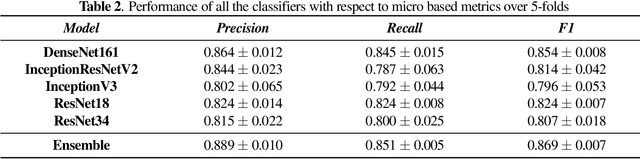
The outbreak of COVID-19 has shocked the entire world with its fairly rapid spread and has challenged different sectors. One of the most effective ways to limit its spread is the early and accurate diagnosis of infected patients. Medical imaging such as X-ray and Computed Tomography (CT) combined with the potential of Artificial Intelligence (AI) plays an essential role in supporting the medical staff in the diagnosis process. Thereby, the use of five different deep learning models (ResNet18, ResNet34, InceptionV3, InceptionResNetV2, and DenseNet161) and their Ensemble have been used in this paper, to classify COVID-19, pneumoni{\ae} and healthy subjects using Chest X-Ray. Multi-label classification was performed to predict multiple pathologies for each patient, if present. Foremost, the interpretability of each of the networks was thoroughly studied using techniques like occlusion, saliency, input X gradient, guided backpropagation, integrated gradients, and DeepLIFT. The mean Micro-F1 score of the models for COVID-19 classifications ranges from 0.66 to 0.875, and is 0.89 for the Ensemble of the network models. The qualitative results depicted the ResNets to be the most interpretable model.