 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Double/Debiased Machine Learning
Apr 11, 2025This paper provides a practical introduction to Double/Debiased Machine Learning (DML). DML provides a general approach to performing inference about a target parameter in the presence of nuisance parameters. The aim of DML is to reduce the impact of nuisance parameter estimation on estimators of the parameter of interest. We describe DML and its two essential components: Neyman orthogonality and cross-fitting. We highlight that DML reduces functional form dependence and accommodates the use of complex data types, such as text data. We illustrate its application through three empirical examples that demonstrate DML's applicability in cross-sectional and panel settings.
Applied Causal Inference Powered by ML and AI
Mar 04, 2024



An introduction to the emerging fusion of machine learning and causal inference. The book presents ideas from classical structural equation models (SEMs) and their modern AI equivalent, directed acyclical graphs (DAGs) and structural causal models (SCMs), and covers Double/Debiased Machine Learning methods to do inference in such models using modern predictive tools.
Predicting 4D Liver MRI for MR-guided Interventions
Feb 25, 2022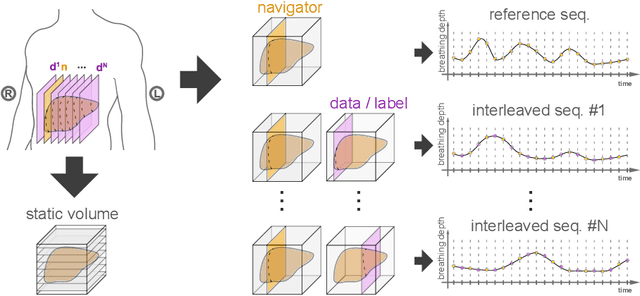


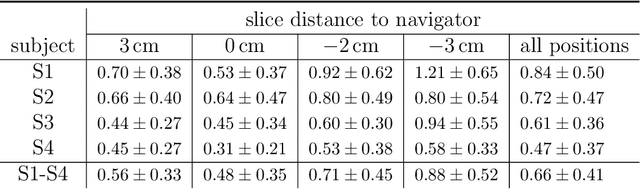
Organ motion poses an unresolved challenge in image-guided interventions. In the pursuit of solving this problem, the research field of time-resolved volumetric magnetic resonance imaging (4D MRI) has evolved. However, current techniques are unsuitable for most interventional settings because they lack sufficient temporal and/or spatial resolution or have long acquisition times. In this work, we propose a novel approach for real-time, high-resolution 4D MRI with large fields of view for MR-guided interventions. To this end, we trained a convolutional neural network (CNN) end-to-end to predict a 3D liver MRI that correctly predicts the liver's respiratory state from a live 2D navigator MRI of a subject. Our method can be used in two ways: First, it can reconstruct near real-time 4D MRI with high quality and high resolution (209x128x128 matrix size with isotropic 1.8mm voxel size and 0.6s/volume) given a dynamic interventional 2D navigator slice for guidance during an intervention. Second, it can be used for retrospective 4D reconstruction with a temporal resolution of below 0.2s/volume for motion analysis and use in radiation therapy. We report a mean target registration error (TRE) of 1.19 $\pm$0.74mm, which is below voxel size. We compare our results with a state-of-the-art retrospective 4D MRI reconstruction. Visual evaluation shows comparable quality. We show that small training sizes with short acquisition times down to 2min can already achieve promising results and 24min are sufficient for high quality results. Because our method can be readily combined with earlier methods, acquisition time can be further decreased while also limiting quality loss. We show that an end-to-end, deep learning formulation is highly promising for 4D MRI reconstruction.
Sequential Modelling with Applications to Music Recommendation, Fact-Checking, and Speed Reading
Sep 11, 2021
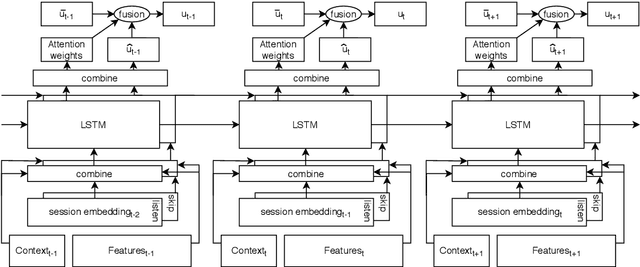
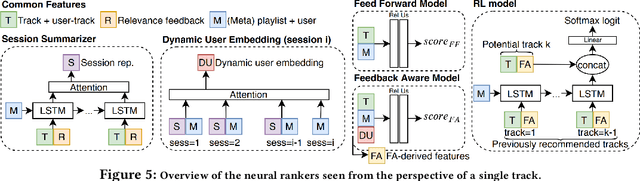
Sequential modelling entails making sense of sequential data, which naturally occurs in a wide array of domains. One example is systems that interact with users, log user actions and behaviour, and make recommendations of items of potential interest to users on the basis of their previous interactions. In such cases, the sequential order of user interactions is often indicative of what the user is interested in next. Similarly, for systems that automatically infer the semantics of text, capturing the sequential order of words in a sentence is essential, as even a slight re-ordering could significantly alter its original meaning. This thesis makes methodological contributions and new investigations of sequential modelling for the specific application areas of systems that recommend music tracks to listeners and systems that process text semantics in order to automatically fact-check claims, or "speed read" text for efficient further classification. (Rest of abstract omitted due to arXiv abstract limit)
2.5D Thermometry Maps for MRI-guided Tumor Ablation
Aug 12, 2021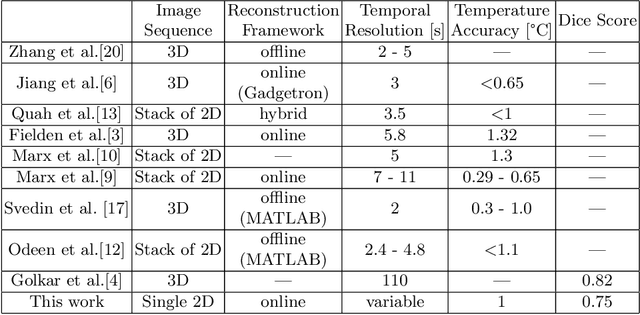
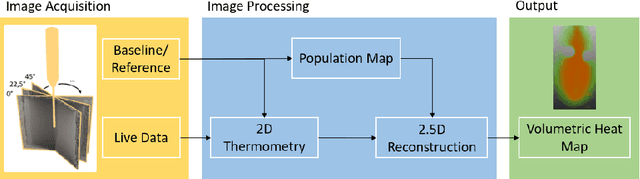
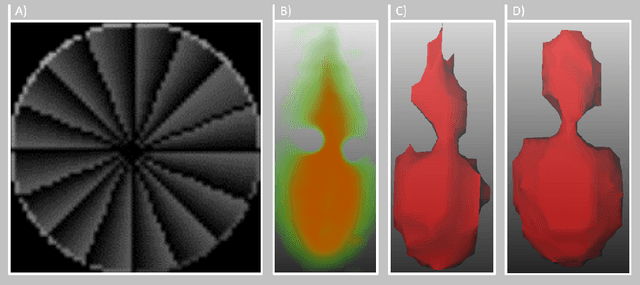
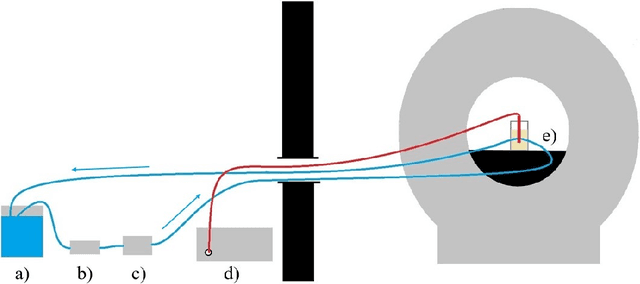
Fast and reliable monitoring of volumetric heat distribution during MRI-guided tumor ablation is an urgent clinical need. In this work, we introduce a method for generating 2.5D thermometry maps from uniformly distributed 2D MRI phase images rotated around the applicator's main axis. The images can be fetched directly from the MR device, reducing the delay between image acquisition and visualization. For reconstruction, we use a weighted interpolation on a cylindric coordinate representation to calculate the heat value of voxels in a region of interest. A pilot study on 13 ex vivo bio protein phantoms with flexible tubes to simulate a heat sink effect was conducted to evaluate our method. After thermal ablation, we compared the measured coagulation zone extracted from the post-treatment MR data set with the output of the 2.5D thermometry map. The results show a mean Dice score of 0.75+-0.07, a sensitivity of 0.77+-0.03, and a reconstruction time within 18.02ms+-5.91ms. Future steps should address improving temporal resolution and accuracy, e.g., incorporating advanced bioheat transfer simulations.
Automatic Fake News Detection: Are Models Learning to Reason?
May 17, 2021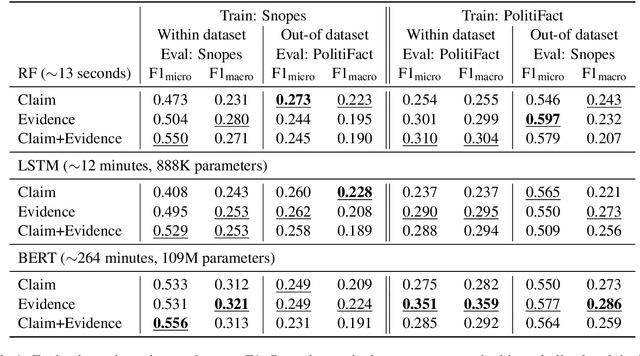
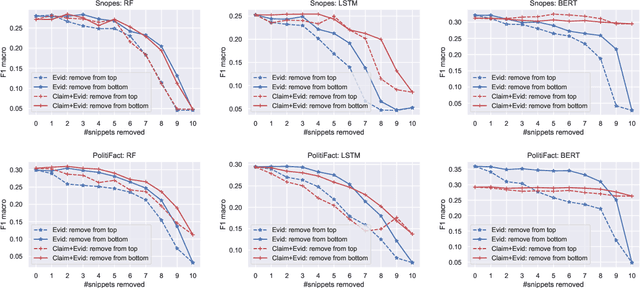
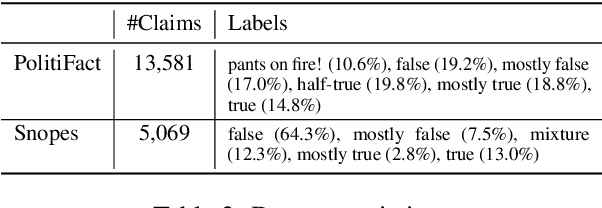
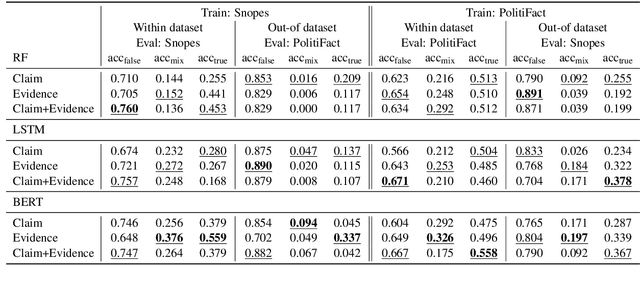
Most fact checking models for automatic fake news detection are based on reasoning: given a claim with associated evidence, the models aim to estimate the claim veracity based on the supporting or refuting content within the evidence. When these models perform well, it is generally assumed to be due to the models having learned to reason over the evidence with regards to the claim. In this paper, we investigate this assumption of reasoning, by exploring the relationship and importance of both claim and evidence. Surprisingly, we find on political fact checking datasets that most often the highest effectiveness is obtained by utilizing only the evidence, as the impact of including the claim is either negligible or harmful to the effectiveness. This highlights an important problem in what constitutes evidence in existing approaches for automatic fake news detection.
Uncertainty-Aware Temporal Self-Learning (UATS): Semi-Supervised Learning for Segmentation of Prostate Zones and Beyond
Apr 08, 2021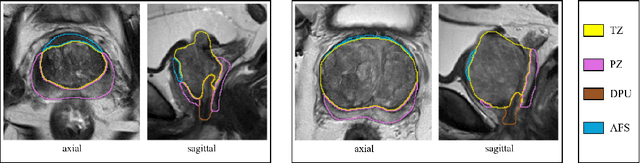
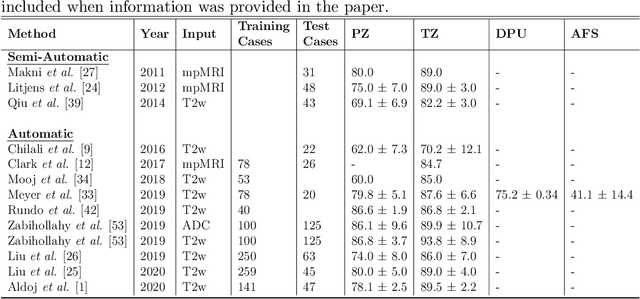
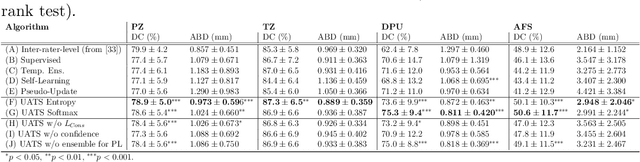
Various convolutional neural network (CNN) based concepts have been introduced for the prostate's automatic segmentation and its coarse subdivision into transition zone (TZ) and peripheral zone (PZ). However, when targeting a fine-grained segmentation of TZ, PZ, distal prostatic urethra (DPU) and the anterior fibromuscular stroma (AFS), the task becomes more challenging and has not yet been solved at the level of human performance. One reason might be the insufficient amount of labeled data for supervised training. Therefore, we propose to apply a semi-supervised learning (SSL) technique named uncertainty-aware temporal self-learning (UATS) to overcome the expensive and time-consuming manual ground truth labeling. We combine the SSL techniques temporal ensembling and uncertainty-guided self-learning to benefit from unlabeled images, which are often readily available. Our method significantly outperforms the supervised baseline and obtained a Dice coefficient (DC) of up to 78.9% , 87.3%, 75.3%, 50.6% for TZ, PZ, DPU and AFS, respectively. The obtained results are in the range of human inter-rater performance for all structures. Moreover, we investigate the method's robustness against noise and demonstrate the generalization capability for varying ratios of labeled data and on other challenging tasks, namely the hippocampus and skin lesion segmentation. UATS achieved superiority segmentation quality compared to the supervised baseline, particularly for minimal amounts of labeled data.
Unsupervised Multi-Index Semantic Hashing
Mar 26, 2021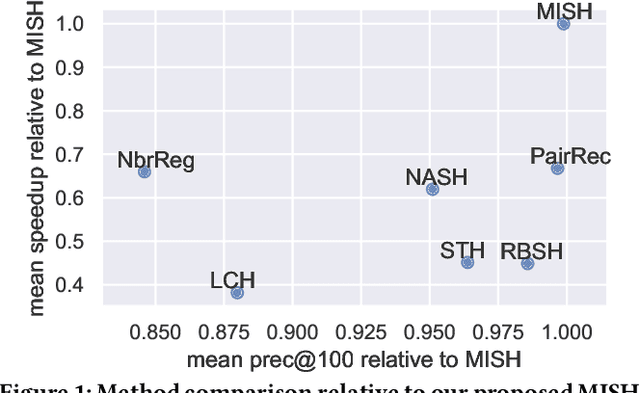

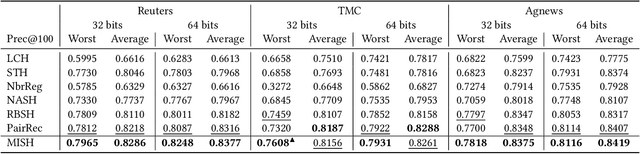
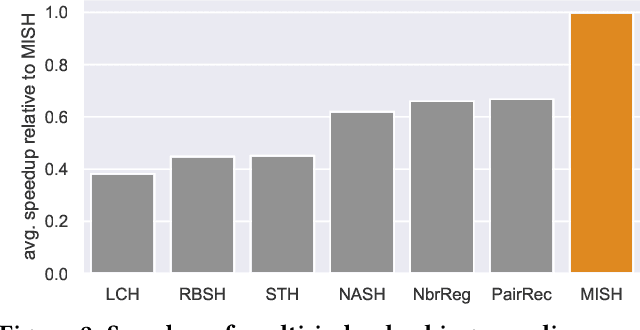
Semantic hashing represents documents as compact binary vectors (hash codes) and allows both efficient and effective similarity search in large-scale information retrieval. The state of the art has primarily focused on learning hash codes that improve similarity search effectiveness, while assuming a brute-force linear scan strategy for searching over all the hash codes, even though much faster alternatives exist. One such alternative is multi-index hashing, an approach that constructs a smaller candidate set to search over, which depending on the distribution of the hash codes can lead to sub-linear search time. In this work, we propose Multi-Index Semantic Hashing (MISH), an unsupervised hashing model that learns hash codes that are both effective and highly efficient by being optimized for multi-index hashing. We derive novel training objectives, which enable to learn hash codes that reduce the candidate sets produced by multi-index hashing, while being end-to-end trainable. In fact, our proposed training objectives are model agnostic, i.e., not tied to how the hash codes are generated specifically in MISH, and are straight-forward to include in existing and future semantic hashing models. We experimentally compare MISH to state-of-the-art semantic hashing baselines in the task of document similarity search. We find that even though multi-index hashing also improves the efficiency of the baselines compared to a linear scan, they are still upwards of 33% slower than MISH, while MISH is still able to obtain state-of-the-art effectiveness.
Projected Hamming Dissimilarity for Bit-Level Importance Coding in Collaborative Filtering
Mar 26, 2021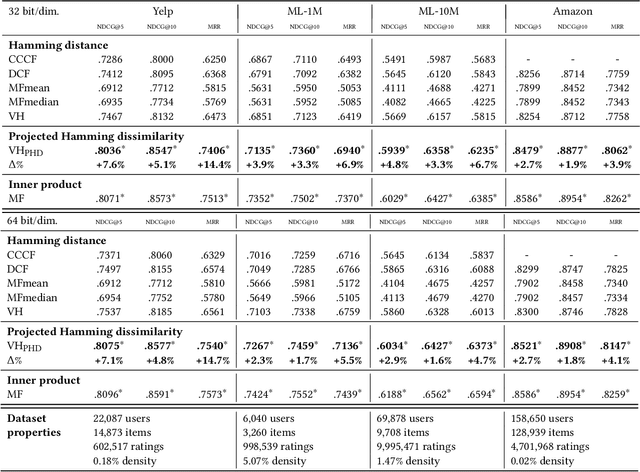
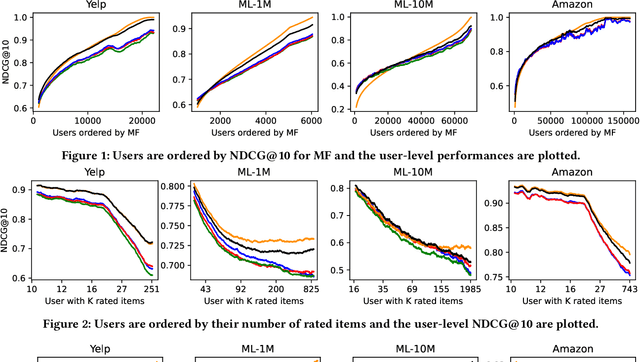
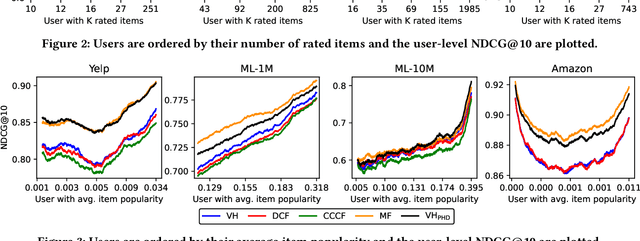
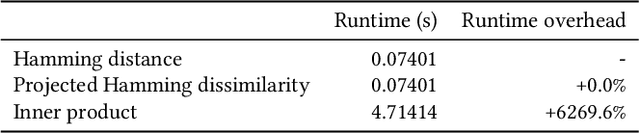
When reasoning about tasks that involve large amounts of data, a common approach is to represent data items as objects in the Hamming space where operations can be done efficiently and effectively. Object similarity can then be computed by learning binary representations (hash codes) of the objects and computing their Hamming distance. While this is highly efficient, each bit dimension is equally weighted, which means that potentially discriminative information of the data is lost. A more expressive alternative is to use real-valued vector representations and compute their inner product; this allows varying the weight of each dimension but is many magnitudes slower. To fix this, we derive a new way of measuring the dissimilarity between two objects in the Hamming space with binary weighting of each dimension (i.e., disabling bits): we consider a field-agnostic dissimilarity that projects the vector of one object onto the vector of the other. When working in the Hamming space, this results in a novel projected Hamming dissimilarity, which by choice of projection, effectively allows a binary importance weighting of the hash code of one object through the hash code of the other. We propose a variational hashing model for learning hash codes optimized for this projected Hamming dissimilarity, and experimentally evaluate it in collaborative filtering experiments. The resultant hash codes lead to effectiveness gains of up to +7% in NDCG and +14% in MRR compared to state-of-the-art hashing-based collaborative filtering baselines, while requiring no additional storage and no computational overhead compared to using the Hamming distance.
Learning Multi-Modal Volumetric Prostate Registration with Weak Inter-Subject Spatial Correspondence
Feb 09, 2021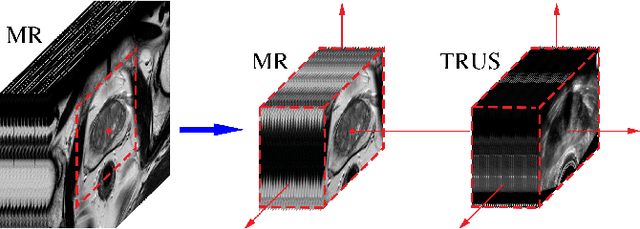
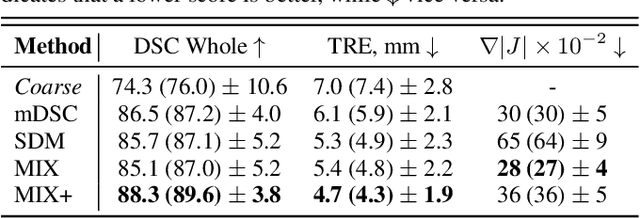
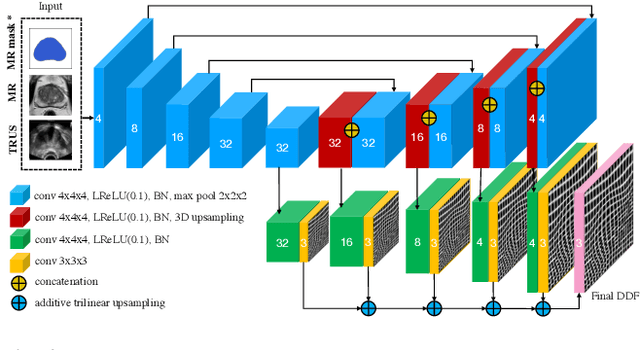
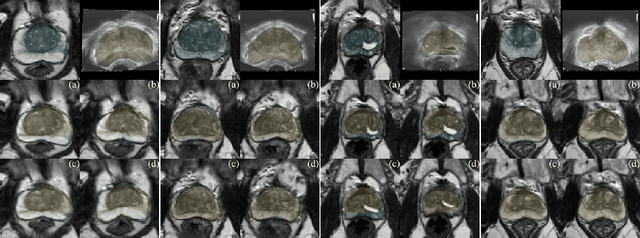
Recent studies demonstrated the eligibility of convolutional neural networks (CNNs) for solving the image registration problem. CNNs enable faster transformation estimation and greater generalization capability needed for better support during medical interventions. Conventional fully-supervised training requires a lot of high-quality ground truth data such as voxel-to-voxel transformations, which typically are attained in a too tedious and error-prone manner. In our work, we use weakly-supervised learning, which optimizes the model indirectly only via segmentation masks that are a more accessible ground truth than the deformation fields. Concerning the weak supervision, we investigate two segmentation similarity measures: multiscale Dice similarity coefficient (mDSC) and the similarity between segmentation-derived signed distance maps (SDMs). We show that the combination of mDSC and SDM similarity measures results in a more accurate and natural transformation pattern together with a stronger gradient coverage. Furthermore, we introduce an auxiliary input to the neural network for the prior information about the prostate location in the MR sequence, which mostly is available preoperatively. This approach significantly outperforms the standard two-input models. With weakly labelled MR-TRUS prostate data, we showed registration quality comparable to the state-of-the-art deep learning-based method.