 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosets and Bounded Probabilities for Discovering Order-inducing Features in Event Knowledge Graphs
Oct 08, 2024



Event knowledge graphs (EKG) extend the classical notion of a trace to capture multiple, interacting views of a process execution. In this paper, we tackle the open problem of automating EKG discovery from uncurated data through a principled, probabilistic framing based on the outcome space resulting from featured-derived partial orders on events. From this, we derive an EKG discovery algorithm based upon statistical inference rather than an ad-hoc or heuristic-based strategy, or relying on manual analysis from domain experts. This approach comes at the computational cost of exploring a large, non-convex hypothesis space. In particular, solving the maximum likelihood term involves counting the number of linear extensions of posets, which in general is #P-complete. Fortunately, bound estimates suffice for model comparison, and admit incorporation into a bespoke branch-and-bound algorithm. We show that the posterior probability as defined is antitonic w.r.t. search depth for branching rules that are monotonic w.r.t. model inclusion. This allows pruning of large portions of the search space, which we show experimentally leads to rapid convergence toward optimal solutions that are consistent with manually built EKGs.
Mixture of Experts Using Tensor Products
May 26, 2024



In multi-task learning, the conventional approach involves training a model on multiple tasks simultaneously. However, the training signals from different tasks can interfere with one another, potentially leading to \textit{negative transfer}. To mitigate this, we investigate if modular language models can facilitate positive transfer and systematic generalization. Specifically, we propose a novel modular language model (\texttt{TensorPoly}), that balances parameter efficiency with nuanced routing methods. For \textit{modules}, we reparameterize Low-Rank Adaptation (\texttt{LoRA}) by employing an entangled tensor through the use of tensor product operations and name the resulting approach \texttt{TLoRA}. For \textit{routing function}, we tailor two innovative routing functions according to the granularity: \texttt{TensorPoly-I} which directs to each rank within the entangled tensor while \texttt{TensorPoly-II} offers a finer-grained routing approach targeting each order of the entangled tensor. The experimental results from the multi-task T0-benchmark demonstrate that: 1) all modular LMs surpass the corresponding dense approaches, highlighting the potential of modular language models to mitigate negative inference in multi-task learning and deliver superior outcomes. 2) \texttt{TensorPoly-I} achieves higher parameter efficiency in adaptation and outperforms other modular LMs, which shows the potential of our approach in multi-task transfer learning.
Language Modeling Using Tensor Trains
May 07, 2024

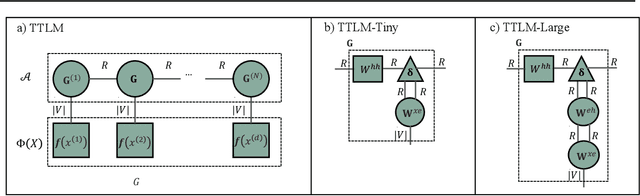

We propose a novel tensor network language model based on the simplest tensor network (i.e., tensor trains), called `Tensor Train Language Model' (TTLM). TTLM represents sentences in an exponential space constructed by the tensor product of words, but computing the probabilities of sentences in a low-dimensional fashion. We demonstrate that the architectures of Second-order RNNs, Recurrent Arithmetic Circuits (RACs), and Multiplicative Integration RNNs are, essentially, special cases of TTLM. Experimental evaluations on real language modeling tasks show that the proposed variants of TTLM (i.e., TTLM-Large and TTLM-Tiny) outperform the vanilla Recurrent Neural Networks (RNNs) with low-scale of hidden units. (The code is available at https://github.com/shuishen112/tensortrainlm.)
Faithfulness Tests for Natural Language Explanations
May 29, 2023
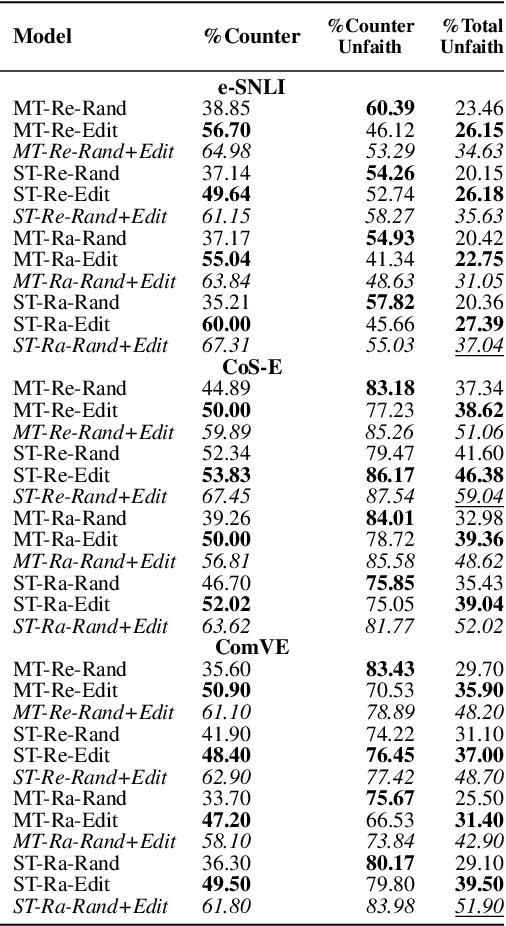
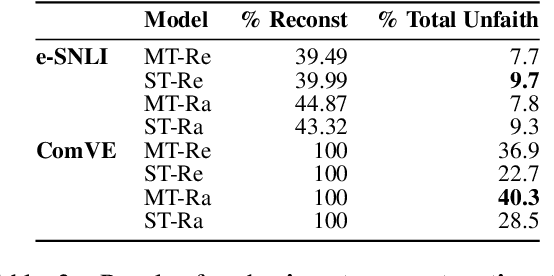

Explanations of neural models aim to reveal a model's decision-making process for its predictions. However, recent work shows that current methods giving explanations such as saliency maps or counterfactuals can be misleading, as they are prone to present reasons that are unfaithful to the model's inner workings. This work explores the challenging question of evaluating the faithfulness of natural language explanations (NLEs). To this end, we present two tests. First, we propose a counterfactual input editor for inserting reasons that lead to counterfactual predictions but are not reflected by the NLEs. Second, we reconstruct inputs from the reasons stated in the generated NLEs and check how often they lead to the same predictions. Our tests can evaluate emerging NLE models, proving a fundamental tool in the development of faithful NLEs.
Principled Multi-Aspect Evaluation Measures of Rankings
Dec 01, 2022



Information Retrieval evaluation has traditionally focused on defining principled ways of assessing the relevance of a ranked list of documents with respect to a query. Several methods extend this type of evaluation beyond relevance, making it possible to evaluate different aspects of a document ranking (e.g., relevance, usefulness, or credibility) using a single measure (multi-aspect evaluation). However, these methods either are (i) tailor-made for specific aspects and do not extend to other types or numbers of aspects, or (ii) have theoretical anomalies, e.g. assign maximum score to a ranking where all documents are labelled with the lowest grade with respect to all aspects (e.g., not relevant, not credible, etc.). We present a theoretically principled multi-aspect evaluation method that can be used for any number, and any type, of aspects. A thorough empirical evaluation using up to 5 aspects and a total of 425 runs officially submitted to 10 TREC tracks shows that our method is more discriminative than the state-of-the-art and overcomes theoretical limitations of the state-of-the-art.
Fact Checking with Insufficient Evidence
Apr 05, 2022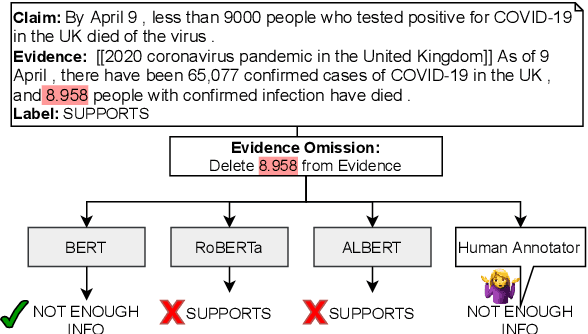



Automating the fact checking (FC) process relies on information obtained from external sources. In this work, we posit that it is crucial for FC models to make veracity predictions only when there is sufficient evidence and otherwise indicate when it is not enough. To this end, we are the first to study what information FC models consider sufficient by introducing a novel task and advancing it with three main contributions. First, we conduct an in-depth empirical analysis of the task with a new fluency-preserving method for omitting information from the evidence at the constituent and sentence level. We identify when models consider the remaining evidence (in)sufficient for FC, based on three trained models with different Transformer architectures and three FC datasets. Second, we ask annotators whether the omitted evidence was important for FC, resulting in a novel diagnostic dataset, SufficientFacts, for FC with omitted evidence. We find that models are least successful in detecting missing evidence when adverbial modifiers are omitted (21% accuracy), whereas it is easiest for omitted date modifiers (63% accuracy). Finally, we propose a novel data augmentation strategy for contrastive self-learning of missing evidence by employing the proposed omission method combined with tri-training. It improves performance for Evidence Sufficiency Prediction by up to 17.8 F1 score, which in turn improves FC performance by up to 2.6 F1 score.
Diagnostics-Guided Explanation Generation
Sep 08, 2021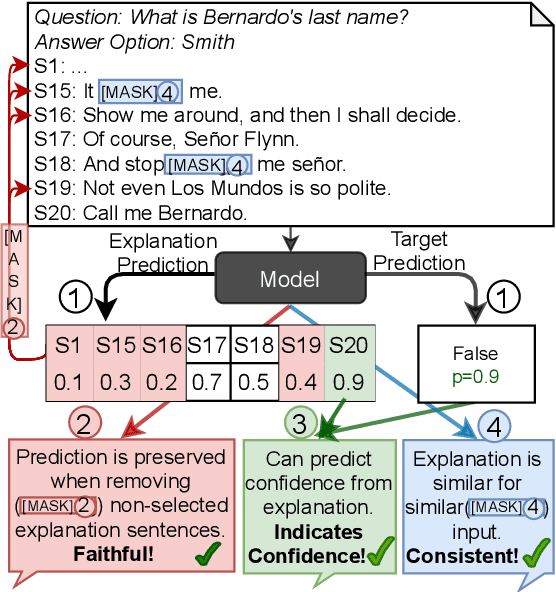
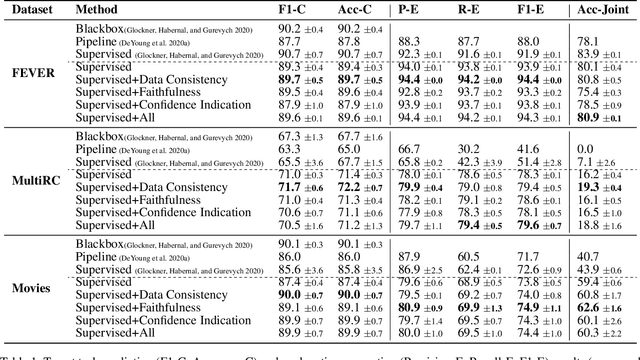
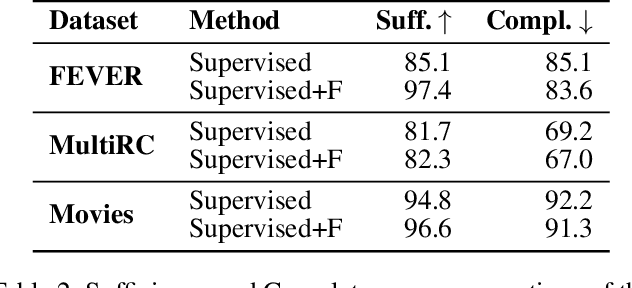
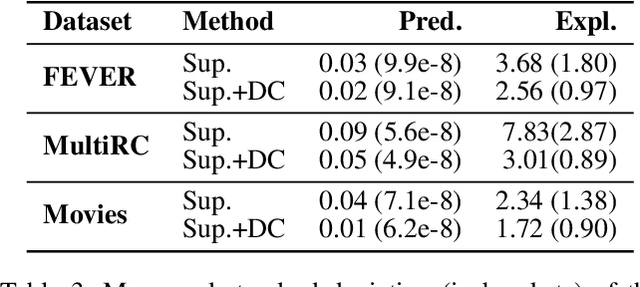
Explanations shed light on a machine learning model's rationales and can aid in identifying deficiencies in its reasoning process. Explanation generation models are typically trained in a supervised way given human explanations. When such annotations are not available, explanations are often selected as those portions of the input that maximise a downstream task's performance, which corresponds to optimising an explanation's Faithfulness to a given model. Faithfulness is one of several so-called diagnostic properties, which prior work has identified as useful for gauging the quality of an explanation without requiring annotations. Other diagnostic properties are Data Consistency, which measures how similar explanations are for similar input instances, and Confidence Indication, which shows whether the explanation reflects the confidence of the model. In this work, we show how to directly optimise for these diagnostic properties when training a model to generate sentence-level explanations, which markedly improves explanation quality, agreement with human rationales, and downstream task performance on three complex reasoning tasks.
Unsupervised Multi-Index Semantic Hashing
Mar 26, 2021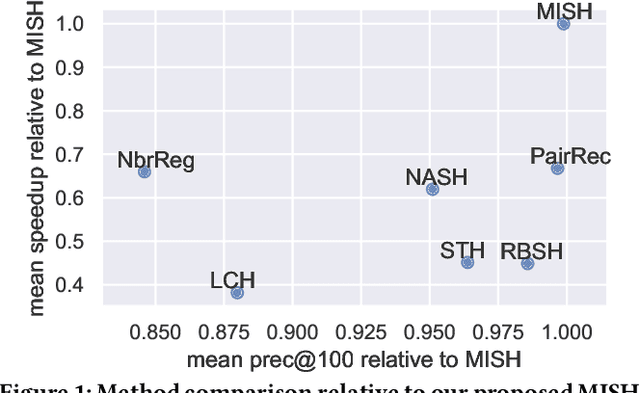

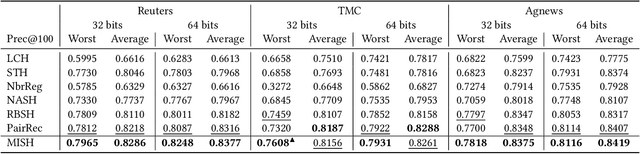
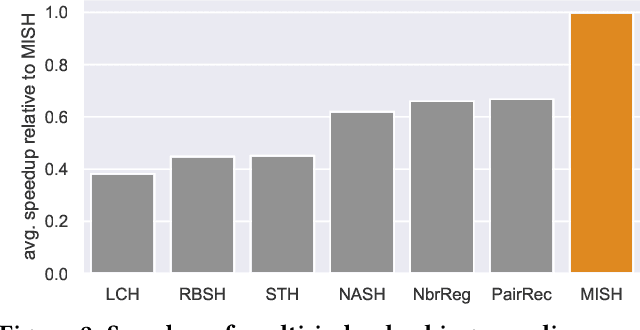
Semantic hashing represents documents as compact binary vectors (hash codes) and allows both efficient and effective similarity search in large-scale information retrieval. The state of the art has primarily focused on learning hash codes that improve similarity search effectiveness, while assuming a brute-force linear scan strategy for searching over all the hash codes, even though much faster alternatives exist. One such alternative is multi-index hashing, an approach that constructs a smaller candidate set to search over, which depending on the distribution of the hash codes can lead to sub-linear search time. In this work, we propose Multi-Index Semantic Hashing (MISH), an unsupervised hashing model that learns hash codes that are both effective and highly efficient by being optimized for multi-index hashing. We derive novel training objectives, which enable to learn hash codes that reduce the candidate sets produced by multi-index hashing, while being end-to-end trainable. In fact, our proposed training objectives are model agnostic, i.e., not tied to how the hash codes are generated specifically in MISH, and are straight-forward to include in existing and future semantic hashing models. We experimentally compare MISH to state-of-the-art semantic hashing baselines in the task of document similarity search. We find that even though multi-index hashing also improves the efficiency of the baselines compared to a linear scan, they are still upwards of 33% slower than MISH, while MISH is still able to obtain state-of-the-art effectiveness.
Projected Hamming Dissimilarity for Bit-Level Importance Coding in Collaborative Filtering
Mar 26, 2021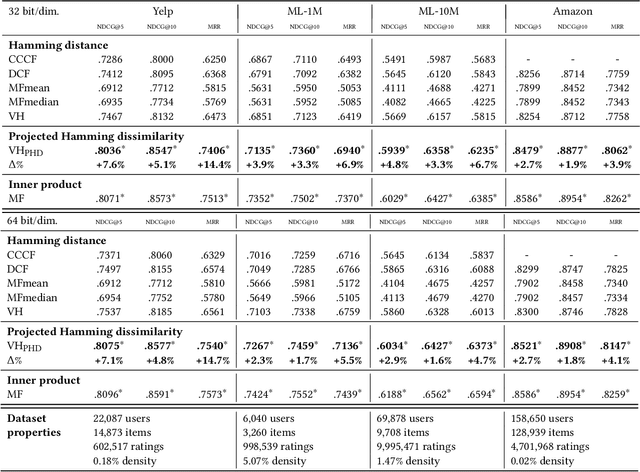
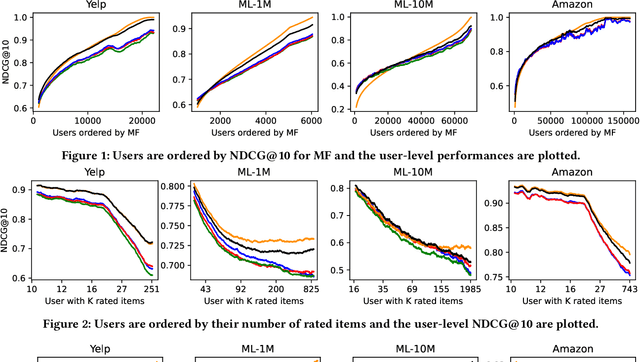
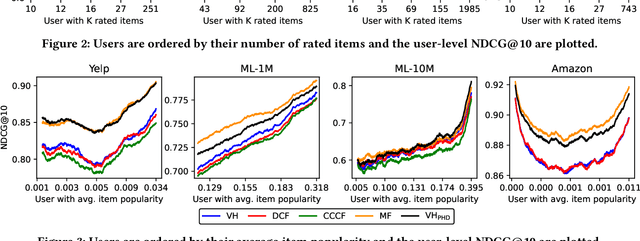
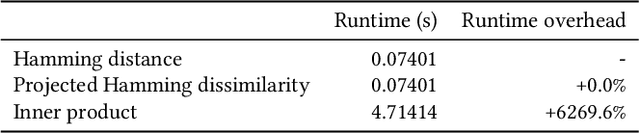
When reasoning about tasks that involve large amounts of data, a common approach is to represent data items as objects in the Hamming space where operations can be done efficiently and effectively. Object similarity can then be computed by learning binary representations (hash codes) of the objects and computing their Hamming distance. While this is highly efficient, each bit dimension is equally weighted, which means that potentially discriminative information of the data is lost. A more expressive alternative is to use real-valued vector representations and compute their inner product; this allows varying the weight of each dimension but is many magnitudes slower. To fix this, we derive a new way of measuring the dissimilarity between two objects in the Hamming space with binary weighting of each dimension (i.e., disabling bits): we consider a field-agnostic dissimilarity that projects the vector of one object onto the vector of the other. When working in the Hamming space, this results in a novel projected Hamming dissimilarity, which by choice of projection, effectively allows a binary importance weighting of the hash code of one object through the hash code of the other. We propose a variational hashing model for learning hash codes optimized for this projected Hamming dissimilarity, and experimentally evaluate it in collaborative filtering experiments. The resultant hash codes lead to effectiveness gains of up to +7% in NDCG and +14% in MRR compared to state-of-the-art hashing-based collaborative filtering baselines, while requiring no additional storage and no computational overhead compared to using the Hamming distance.
Multi-Head Self-Attention with Role-Guided Masks
Dec 22, 2020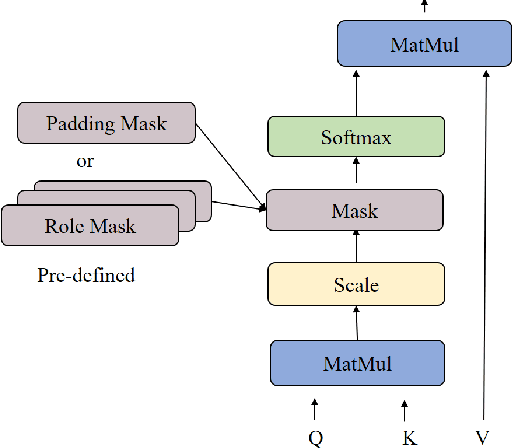
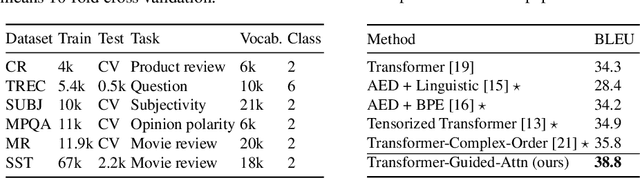
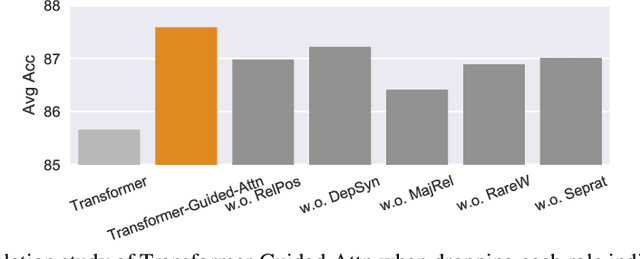
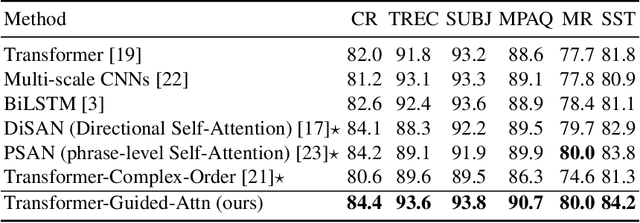
The state of the art in learning meaningful semantic representations of words is the Transformer model and its attention mechanisms. Simply put, the attention mechanisms learn to attend to specific parts of the input dispensing recurrence and convolutions. While some of the learned attention heads have been found to play linguistically interpretable roles, they can be redundant or prone to errors. We propose a method to guide the attention heads towards roles identified in prior work as important. We do this by defining role-specific masks to constrain the heads to attend to specific parts of the input, such that different heads are designed to play different roles. Experiments on text classification and machine translation using 7 different datasets show that our method outperforms competitive attention-based, CNN, and RNN baselines.