 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTimeAnomalyViz: A Tool for Visualizing and Post-processing Deep Learning Anomaly Detection Results for Industrial Time-Series
Sep 21, 2021
Industrial processes are monitored by a large number of various sensors that produce time-series data. Deep Learning offers a possibility to create anomaly detection methods that can aid in preventing malfunctions and increasing efficiency. But creating such a solution can be a complicated task, with factors such as inference speed, amount of available data, number of sensors, and many more, influencing the feasibility of such implementation. We introduce the DeTAVIZ interface, which is a web browser based visualization tool for quick exploration and assessment of feasibility of DL based anomaly detection in a given problem. Provided with a pool of pretrained models and simulation results, DeTAVIZ allows the user to easily and quickly iterate through multiple post processing options and compare different models, and allows for manual optimisation towards a chosen metric.
Representation Learning for Efficient and Effective Similarity Search and Recommendation
Sep 04, 2021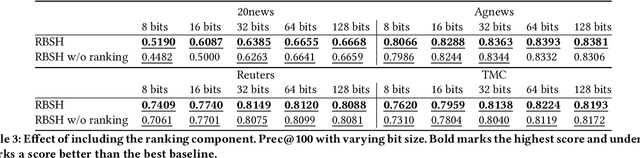
How data is represented and operationalized is critical for building computational solutions that are both effective and efficient. A common approach is to represent data objects as binary vectors, denoted \textit{hash codes}, which require little storage and enable efficient similarity search through direct indexing into a hash table or through similarity computations in an appropriate space. Due to the limited expressibility of hash codes, compared to real-valued representations, a core open challenge is how to generate hash codes that well capture semantic content or latent properties using a small number of bits, while ensuring that the hash codes are distributed in a way that does not reduce their search efficiency. State of the art methods use representation learning for generating such hash codes, focusing on neural autoencoder architectures where semantics are encoded into the hash codes by learning to reconstruct the original inputs of the hash codes. This thesis addresses the above challenge and makes a number of contributions to representation learning that (i) improve effectiveness of hash codes through more expressive representations and a more effective similarity measure than the current state of the art, namely the Hamming distance, and (ii) improve efficiency of hash codes by learning representations that are especially suited to the choice of search method. The contributions are empirically validated on several tasks related to similarity search and recommendation.
Detecting Faults during Automatic Screwdriving: A Dataset and Use Case of Anomaly Detection for Automatic Screwdriving
Jul 05, 2021
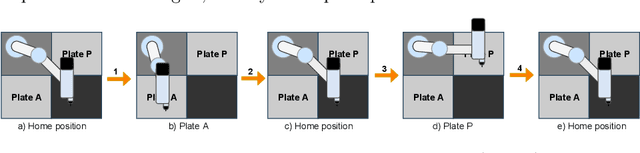
Detecting faults in manufacturing applications can be difficult, especially if each fault model is to be engineered by hand. Data-driven approaches, using Machine Learning (ML) for detecting faults have recently gained increasing interest, where a ML model can be trained on a set of data from a manufacturing process. In this paper, we present a use case of using ML models for detecting faults during automated screwdriving operations, and introduce a new dataset containing fully monitored and registered data from a Universal Robot and OnRobot screwdriver during both normal and anomalous operations. We illustrate, with the use of two time-series ML models, how to detect faults in an automated screwdriving application.
Automatic Fake News Detection: Are Models Learning to Reason?
May 17, 2021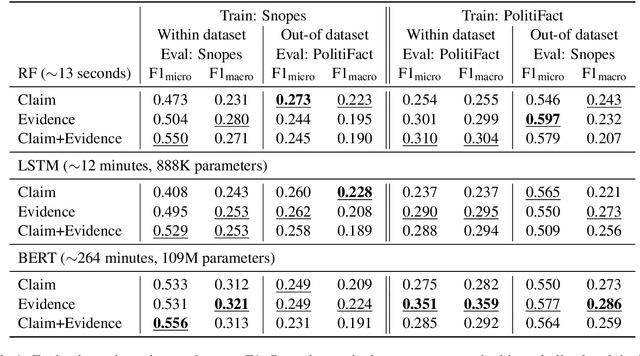
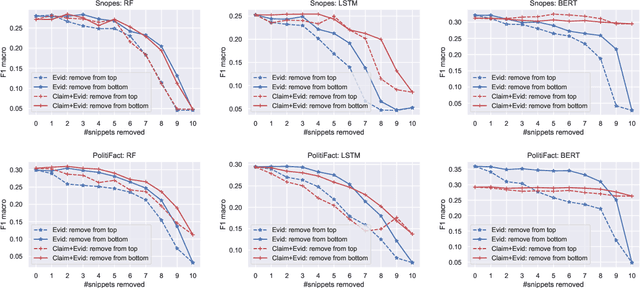
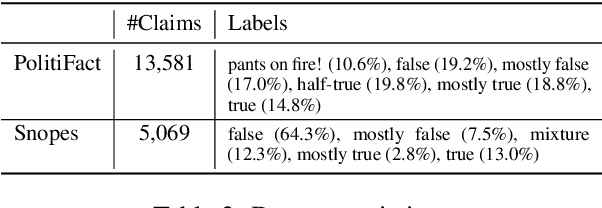
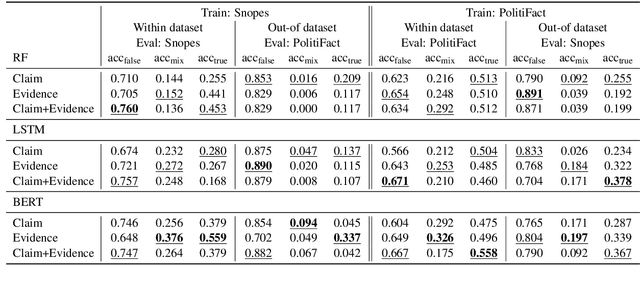
Most fact checking models for automatic fake news detection are based on reasoning: given a claim with associated evidence, the models aim to estimate the claim veracity based on the supporting or refuting content within the evidence. When these models perform well, it is generally assumed to be due to the models having learned to reason over the evidence with regards to the claim. In this paper, we investigate this assumption of reasoning, by exploring the relationship and importance of both claim and evidence. Surprisingly, we find on political fact checking datasets that most often the highest effectiveness is obtained by utilizing only the evidence, as the impact of including the claim is either negligible or harmful to the effectiveness. This highlights an important problem in what constitutes evidence in existing approaches for automatic fake news detection.
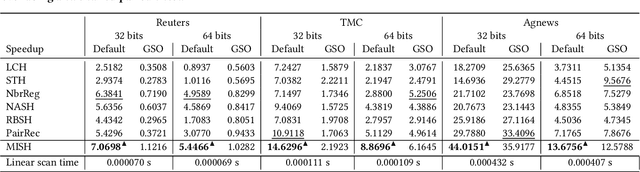
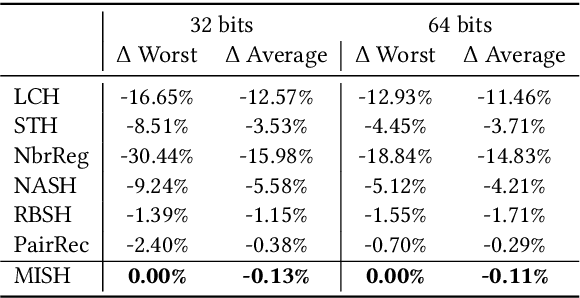
Unsupervised Multi-Index Semantic Hashing
Mar 26, 2021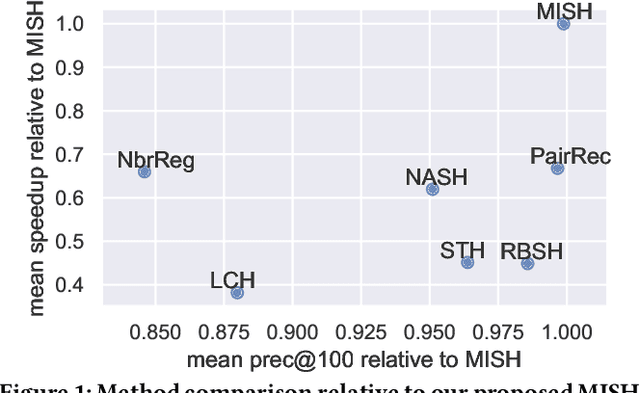

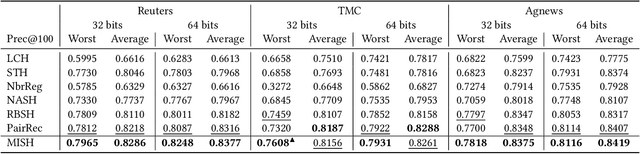
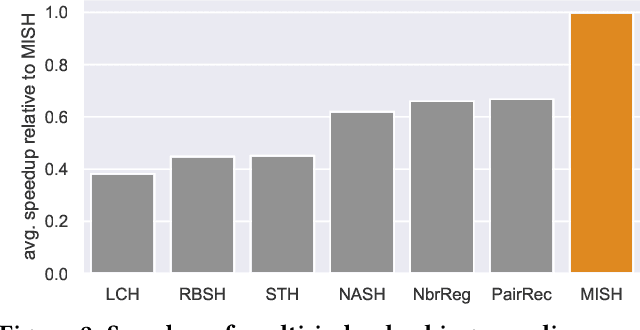
Semantic hashing represents documents as compact binary vectors (hash codes) and allows both efficient and effective similarity search in large-scale information retrieval. The state of the art has primarily focused on learning hash codes that improve similarity search effectiveness, while assuming a brute-force linear scan strategy for searching over all the hash codes, even though much faster alternatives exist. One such alternative is multi-index hashing, an approach that constructs a smaller candidate set to search over, which depending on the distribution of the hash codes can lead to sub-linear search time. In this work, we propose Multi-Index Semantic Hashing (MISH), an unsupervised hashing model that learns hash codes that are both effective and highly efficient by being optimized for multi-index hashing. We derive novel training objectives, which enable to learn hash codes that reduce the candidate sets produced by multi-index hashing, while being end-to-end trainable. In fact, our proposed training objectives are model agnostic, i.e., not tied to how the hash codes are generated specifically in MISH, and are straight-forward to include in existing and future semantic hashing models. We experimentally compare MISH to state-of-the-art semantic hashing baselines in the task of document similarity search. We find that even though multi-index hashing also improves the efficiency of the baselines compared to a linear scan, they are still upwards of 33% slower than MISH, while MISH is still able to obtain state-of-the-art effectiveness.
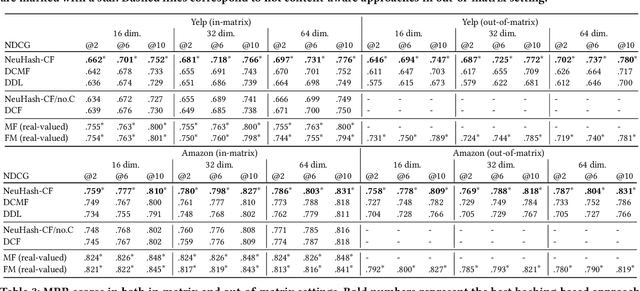
Projected Hamming Dissimilarity for Bit-Level Importance Coding in Collaborative Filtering
Mar 26, 2021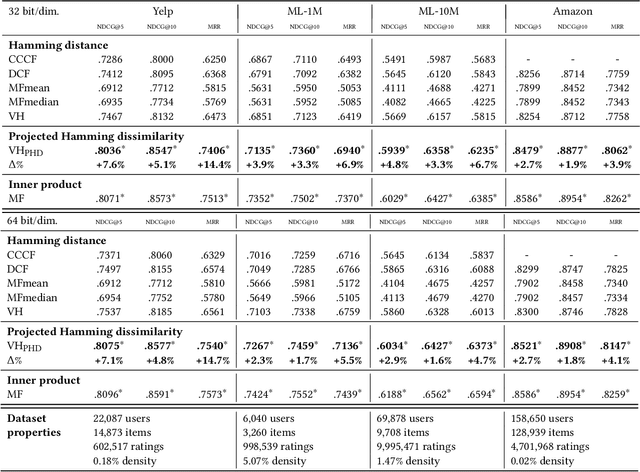
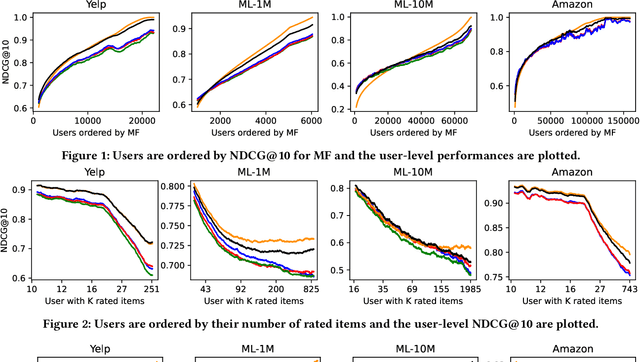
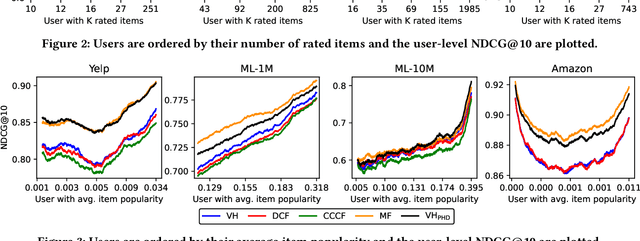
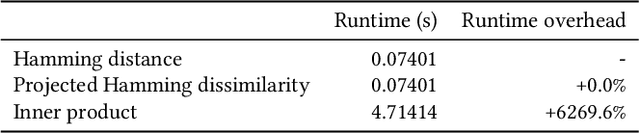
When reasoning about tasks that involve large amounts of data, a common approach is to represent data items as objects in the Hamming space where operations can be done efficiently and effectively. Object similarity can then be computed by learning binary representations (hash codes) of the objects and computing their Hamming distance. While this is highly efficient, each bit dimension is equally weighted, which means that potentially discriminative information of the data is lost. A more expressive alternative is to use real-valued vector representations and compute their inner product; this allows varying the weight of each dimension but is many magnitudes slower. To fix this, we derive a new way of measuring the dissimilarity between two objects in the Hamming space with binary weighting of each dimension (i.e., disabling bits): we consider a field-agnostic dissimilarity that projects the vector of one object onto the vector of the other. When working in the Hamming space, this results in a novel projected Hamming dissimilarity, which by choice of projection, effectively allows a binary importance weighting of the hash code of one object through the hash code of the other. We propose a variational hashing model for learning hash codes optimized for this projected Hamming dissimilarity, and experimentally evaluate it in collaborative filtering experiments. The resultant hash codes lead to effectiveness gains of up to +7% in NDCG and +14% in MRR compared to state-of-the-art hashing-based collaborative filtering baselines, while requiring no additional storage and no computational overhead compared to using the Hamming distance.
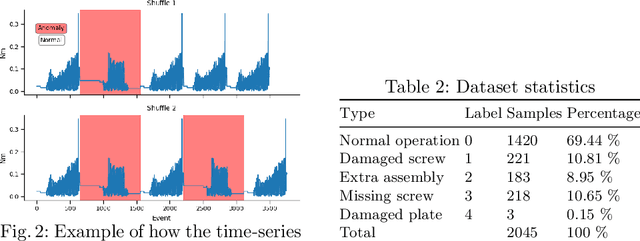
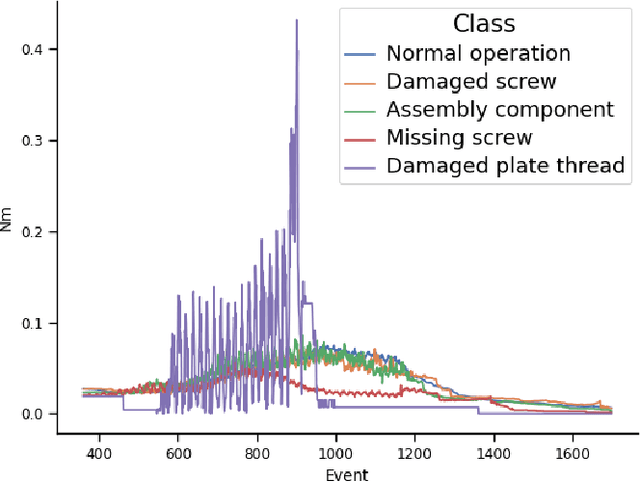
AURSAD: Universal Robot Screwdriving Anomaly Detection Dataset
Feb 06, 2021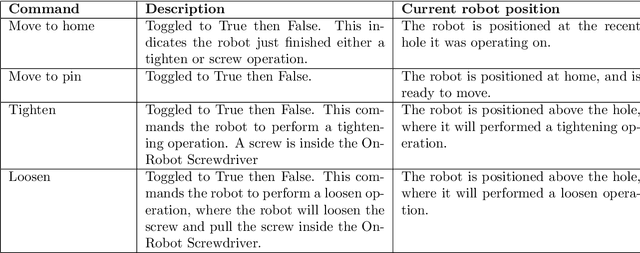


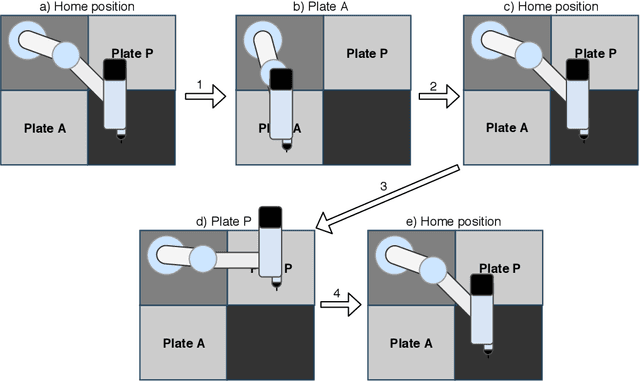
Screwdriving is one of the most popular industrial processes. As such, it is increasingly common to automate that procedure by using various robots. Even though the automation increases the efficiency of the screwdriving process, if the process is not monitored correctly, faults may occur during operation, which can impact the effectiveness and quality of assembly. Machine Learning (ML) has the potential to detect those undesirable events and limit their impact. In order to do so, first a dataset that fully describes the operation of an industrial robot performing automated screwdriving must be available. This report describes a dataset created using a UR3e series robot and OnRobot Screwdriver. We create different scenarios and introduce 4 types of anomalies to the process while all available robot and screwdriver sensors are continuously recorded. The resulting data contains 2042 samples of normal and anomalous robot operation. Brief ML benchmarks using this data are also provided, showcasing the data's suitability and potential for further analysis and experimentation.
Multi-Head Self-Attention with Role-Guided Masks
Dec 22, 2020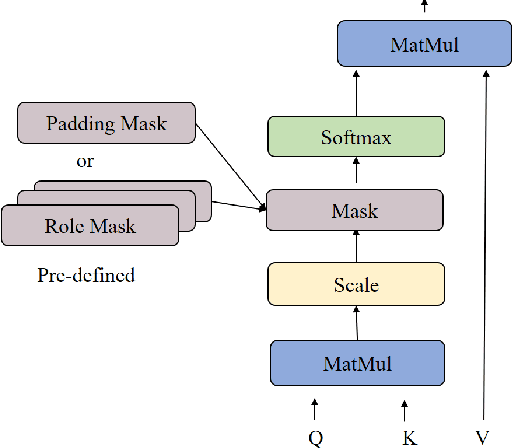
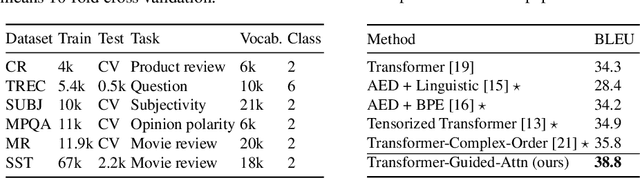
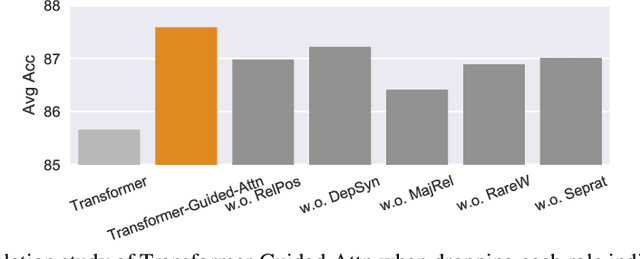
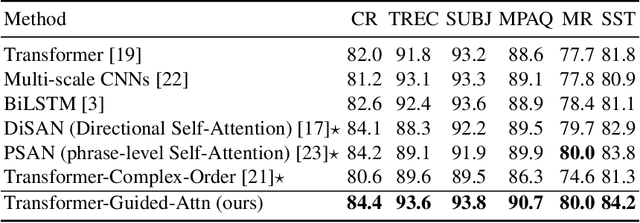
The state of the art in learning meaningful semantic representations of words is the Transformer model and its attention mechanisms. Simply put, the attention mechanisms learn to attend to specific parts of the input dispensing recurrence and convolutions. While some of the learned attention heads have been found to play linguistically interpretable roles, they can be redundant or prone to errors. We propose a method to guide the attention heads towards roles identified in prior work as important. We do this by defining role-specific masks to constrain the heads to attend to specific parts of the input, such that different heads are designed to play different roles. Experiments on text classification and machine translation using 7 different datasets show that our method outperforms competitive attention-based, CNN, and RNN baselines.
Denmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Nov 26, 2020
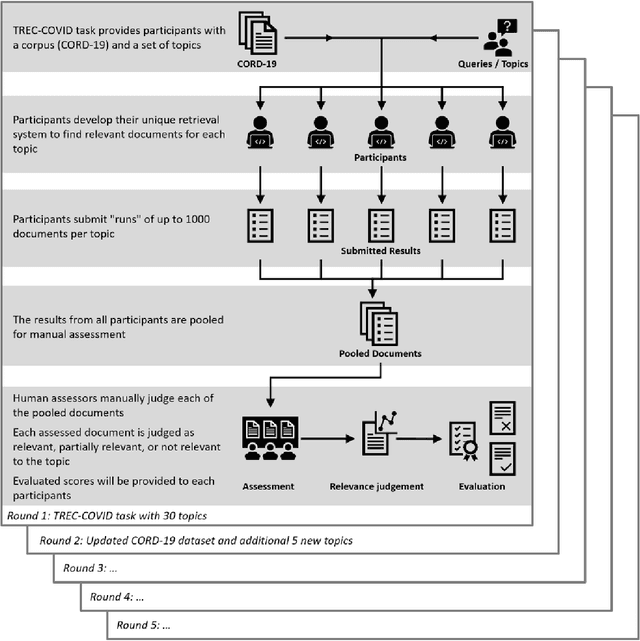
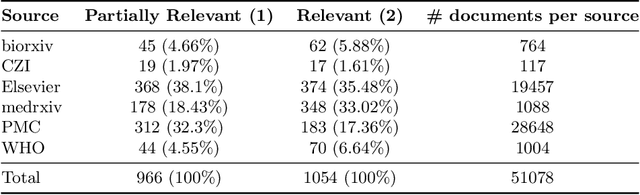
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.
Unsupervised Semantic Hashing with Pairwise Reconstruction
Jul 01, 2020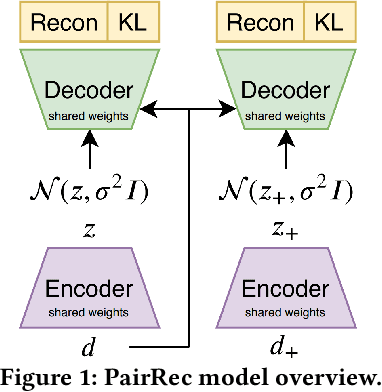
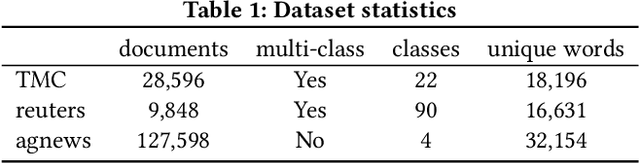
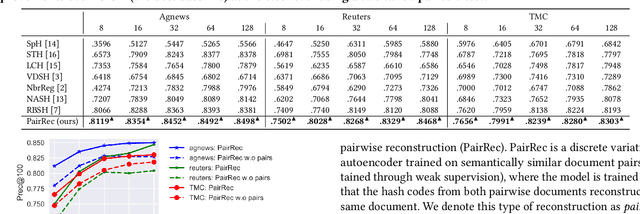
Semantic Hashing is a popular family of methods for efficient similarity search in large-scale datasets. In Semantic Hashing, documents are encoded as short binary vectors (i.e., hash codes), such that semantic similarity can be efficiently computed using the Hamming distance. Recent state-of-the-art approaches have utilized weak supervision to train better performing hashing models. Inspired by this, we present Semantic Hashing with Pairwise Reconstruction (PairRec), which is a discrete variational autoencoder based hashing model. PairRec first encodes weakly supervised training pairs (a query document and a semantically similar document) into two hash codes, and then learns to reconstruct the same query document from both of these hash codes (i.e., pairwise reconstruction). This pairwise reconstruction enables our model to encode local neighbourhood structures within the hash code directly through the decoder. We experimentally compare PairRec to traditional and state-of-the-art approaches, and obtain significant performance improvements in the task of document similarity search.