 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Denoising of User Profiles with LLMs in Collaborative Filtering Recommendation
Jan 25, 2026Implicit feedback -- the main data source for training Recommender Systems (RSs) -- is inherently noisy and has been shown to negatively affect recommendation effectiveness. Denoising has been proposed as a method for removing noisy implicit feedback and improving recommendations. Prior work has focused on in-training denoising, however this requires additional data, changes to the model architecture and training procedure or fine-tuning, all of which can be costly and data hungry. In this work, we focus on post-training denoising. Different from in-training denoising, post-training denoising does not involve changing the architecture of the model nor its training procedure, and does not require additional data. Specifically, we present a method for post-training denoising user profiles using Large Language Models (LLMs) for Collaborative Filtering (CF) recommendations. Our approach prompts LLMs with (i) a user profile (user interactions), (ii) a candidate item, and (iii) its rank as given by the CF recommender, and asks the LLM to remove items from the user profile to improve the rank of the candidate item. Experiments with a state-of-the-art CF recommender and 4 open and closed source LLMs in 3 datasets show that our denoising yields improvements up to 13% in effectiveness over the original user profiles. Our code is available at https://github.com/edervishaj/denoising-user-profiles-LLM.
Measuring Individual User Fairness with User Similarity and Effectiveness Disparity
Jan 23, 2026Individual user fairness is commonly understood as treating similar users similarly. In Recommender Systems (RSs), several evaluation measures exist for quantifying individual user fairness. These measures evaluate fairness via either: (i) the disparity in RS effectiveness scores regardless of user similarity, or (ii) the disparity in items recommended to similar users regardless of item relevance. Both disparity in recommendation effectiveness and user similarity are very important in fairness, yet no existing individual user fairness measure simultaneously accounts for both. In brief, current user fairness evaluation measures implement a largely incomplete definition of fairness. To fill this gap, we present Pairwise User unFairness (PUF), a novel evaluation measure of individual user fairness that considers both effectiveness disparity and user similarity. PUF is the only measure that can express this important distinction. We empirically validate that PUF does this consistently across 4 datasets and 7 rankers, and robustly when varying user similarity or effectiveness. In contrast, all other measures are either almost insensitive to effectiveness disparity or completely insensitive to user similarity. We contribute the first RS evaluation measure to reliably capture both user similarity and effectiveness in individual user fairness. Our code: https://github.com/theresiavr/PUF-individual-user-fairness-recsys.
How Context Shapes Truth: Geometric Transformations of Statement-level Truth Representations in LLMs
Jan 10, 2026Large Language Models (LLMs) often encode whether a statement is true as a vector in their residual stream activations. These vectors, also known as truth vectors, have been studied in prior work, however how they change when context is introduced remains unexplored. We study this question by measuring (1) the directional change ($θ$) between the truth vectors with and without context and (2) the relative magnitude of the truth vectors upon adding context. Across four LLMs and four datasets, we find that (1) truth vectors are roughly orthogonal in early layers, converge in middle layers, and may stabilize or continue increasing in later layers; (2) adding context generally increases the truth vector magnitude, i.e., the separation between true and false representations in the activation space is amplified; (3) larger models distinguish relevant from irrelevant context mainly through directional change ($θ$), while smaller models show this distinction through magnitude differences. We also find that context conflicting with parametric knowledge produces larger geometric changes than parametrically aligned context. To the best of our knowledge, this is the first work that provides a geometric characterization of how context transforms the truth vector in the activation space of LLMs.
The Quest for Reliable Metrics of Responsible AI
Oct 29, 2025The development of Artificial Intelligence (AI), including AI in Science (AIS), should be done following the principles of responsible AI. Progress in responsible AI is often quantified through evaluation metrics, yet there has been less work on assessing the robustness and reliability of the metrics themselves. We reflect on prior work that examines the robustness of fairness metrics for recommender systems as a type of AI application and summarise their key takeaways into a set of non-exhaustive guidelines for developing reliable metrics of responsible AI. Our guidelines apply to a broad spectrum of AI applications, including AIS.
As easy as PIE: understanding when pruning causes language models to disagree
Mar 27, 2025
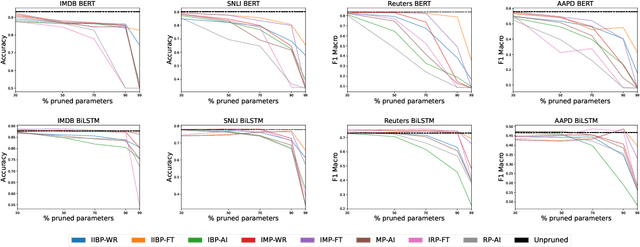

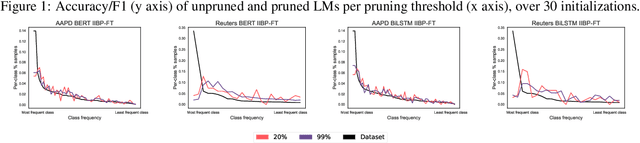
Language Model (LM) pruning compresses the model by removing weights, nodes, or other parts of its architecture. Typically, pruning focuses on the resulting efficiency gains at the cost of effectiveness. However, when looking at how individual data points are affected by pruning, it turns out that a particular subset of data points always bears most of the brunt (in terms of reduced accuracy) when pruning, but this effect goes unnoticed when reporting the mean accuracy of all data points. These data points are called PIEs and have been studied in image processing, but not in NLP. In a study of various NLP datasets, pruning methods, and levels of compression, we find that PIEs impact inference quality considerably, regardless of class frequency, and that BERT is more prone to this than BiLSTM. We also find that PIEs contain a high amount of data points that have the largest influence on how well the model generalises to unseen data. This means that when pruning, with seemingly moderate loss to accuracy across all data points, we in fact hurt tremendously those data points that matter the most. We trace what makes PIEs both hard and impactful to inference to their overall longer and more semantically complex text. These findings are novel and contribute to understanding how LMs are affected by pruning. The code is available at: https://github.com/pietrotrope/AsEasyAsPIE
Joint Evaluation of Fairness and Relevance in Recommender Systems with Pareto Frontier
Feb 17, 2025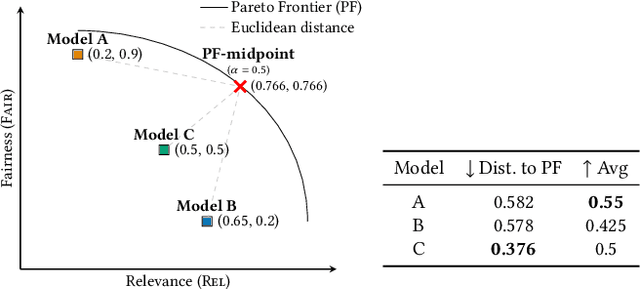
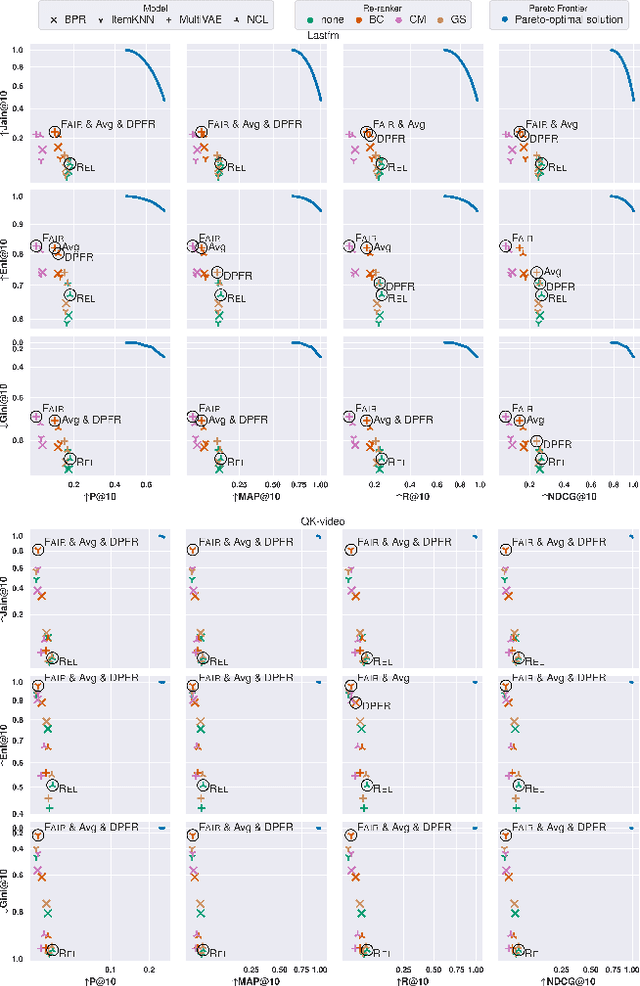
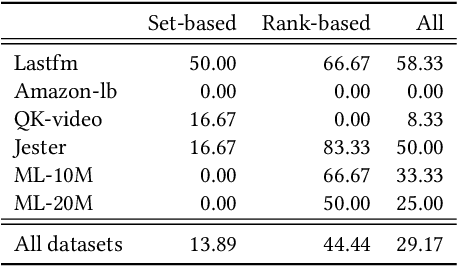
Fairness and relevance are two important aspects of recommender systems (RSs). Typically, they are evaluated either (i) separately by individual measures of fairness and relevance, or (ii) jointly using a single measure that accounts for fairness with respect to relevance. However, approach (i) often does not provide a reliable joint estimate of the goodness of the models, as it has two different best models: one for fairness and another for relevance. Approach (ii) is also problematic because these measures tend to be ad-hoc and do not relate well to traditional relevance measures, like NDCG. Motivated by this, we present a new approach for jointly evaluating fairness and relevance in RSs: Distance to Pareto Frontier (DPFR). Given some user-item interaction data, we compute their Pareto frontier for a pair of existing relevance and fairness measures, and then use the distance from the frontier as a measure of the jointly achievable fairness and relevance. Our approach is modular and intuitive as it can be computed with existing measures. Experiments with 4 RS models, 3 re-ranking strategies, and 6 datasets show that existing metrics have inconsistent associations with our Pareto-optimal solution, making DPFR a more robust and theoretically well-founded joint measure for assessing fairness and relevance. Our code: https://github.com/theresiavr/DPFR-recsys-evaluation
Are Representation Disentanglement and Interpretability Linked in Recommendation Models? A Critical Review and Reproducibility Study
Jan 30, 2025



Unsupervised learning of disentangled representations has been closely tied to enhancing the representation intepretability of Recommender Systems (RSs). This has been achieved by making the representation of individual features more distinctly separated, so that it is easier to attribute the contribution of features to the model's predictions. However, such advantages in interpretability and feature attribution have mainly been explored qualitatively. Moreover, the effect of disentanglement on the model's recommendation performance has been largely overlooked. In this work, we reproduce the recommendation performance, representation disentanglement and representation interpretability of five well-known recommendation models on four RS datasets. We quantify disentanglement and investigate the link of disentanglement with recommendation effectiveness and representation interpretability. While several existing work in RSs have proposed disentangled representations as a gateway to improved effectiveness and interpretability, our findings show that disentanglement is not necessarily related to effectiveness but is closely related to representation interpretability. Our code and results are publicly available at https://github.com/edervishaj/disentanglement-interpretability-recsys.
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Dec 22, 2024



Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information of varying complexity in real-world scenarios have been limited to synthetic contexts. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complex and diverse real-world context settings. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
Joint Extraction and Classification of Danish Competences for Job Matching
Oct 29, 2024The matching of competences, such as skills, occupations or knowledges, is a key desiderata for candidates to be fit for jobs. Automatic extraction of competences from CVs and Jobs can greatly promote recruiters' productivity in locating relevant candidates for job vacancies. This work presents the first model that jointly extracts and classifies competence from Danish job postings. Different from existing works on skill extraction and skill classification, our model is trained on a large volume of annotated Danish corpora and is capable of extracting a wide range of Danish competences, including skills, occupations and knowledges of different categories. More importantly, as a single BERT-like architecture for joint extraction and classification, our model is lightweight and efficient at inference. On a real-scenario job matching dataset, our model beats the state-of-the-art models in the overall performance of Danish competence extraction and classification, and saves over 50% time at inference.
From Internal Conflict to Contextual Adaptation of Language Models
Jul 24, 2024



Knowledge-intensive language understanding tasks require Language Models (LMs) to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. Nevertheless, studies indicate that LMs often ignore the provided context as it can conflict with the pre-existing LM's memory learned during pre-training. Moreover, conflicting knowledge can already be present in the LM's parameters, termed intra-memory conflict. Existing works have studied the two types of knowledge conflicts only in isolation. We conjecture that the (degree of) intra-memory conflicts can in turn affect LM's handling of context-memory conflicts. To study this, we introduce the DYNAMICQA dataset, which includes facts with a temporal dynamic nature where a fact can change with a varying time frequency and disputable dynamic facts, which can change depending on the viewpoint. DYNAMICQA is the first to include real-world knowledge conflicts and provide context to study the link between the different types of knowledge conflicts. With the proposed dataset, we assess the use of uncertainty for measuring the intra-memory conflict and introduce a novel Coherent Persuasion (CP) score to evaluate the context's ability to sway LM's semantic output. Our extensive experiments reveal that static facts, which are unlikely to change, are more easily updated with additional context, relative to temporal and disputable facts.