 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Fairness Be Prompted? Prompt-Based Debiasing Strategies in High-Stakes Recommendations
Mar 13, 2026Large Language Models (LLMs) can infer sensitive attributes such as gender or age from indirect cues like names and pronouns, potentially biasing recommendations. While several debiasing methods exist, they require access to the LLMs' weights, are computationally costly, and cannot be used by lay users. To address this gap, we investigate implicit biases in LLM Recommenders (LLMRecs) and explore whether prompt-based strategies can serve as a lightweight and easy-to-use debiasing approach. We contribute three bias-aware prompting strategies for LLMRecs. To our knowledge, this is the first study on prompt-based debiasing approaches in LLMRecs that focuses on group fairness for users. Our experiments with 3 LLMs, 4 prompt templates, 9 sensitive attribute values, and 2 datasets show that our proposed debiasing approach, which instructs an LLM to be fair, can improve fairness by up to 74% while retaining comparable effectiveness, but might overpromote specific demographic groups in some cases.
Measuring Individual User Fairness with User Similarity and Effectiveness Disparity
Jan 23, 2026Individual user fairness is commonly understood as treating similar users similarly. In Recommender Systems (RSs), several evaluation measures exist for quantifying individual user fairness. These measures evaluate fairness via either: (i) the disparity in RS effectiveness scores regardless of user similarity, or (ii) the disparity in items recommended to similar users regardless of item relevance. Both disparity in recommendation effectiveness and user similarity are very important in fairness, yet no existing individual user fairness measure simultaneously accounts for both. In brief, current user fairness evaluation measures implement a largely incomplete definition of fairness. To fill this gap, we present Pairwise User unFairness (PUF), a novel evaluation measure of individual user fairness that considers both effectiveness disparity and user similarity. PUF is the only measure that can express this important distinction. We empirically validate that PUF does this consistently across 4 datasets and 7 rankers, and robustly when varying user similarity or effectiveness. In contrast, all other measures are either almost insensitive to effectiveness disparity or completely insensitive to user similarity. We contribute the first RS evaluation measure to reliably capture both user similarity and effectiveness in individual user fairness. Our code: https://github.com/theresiavr/PUF-individual-user-fairness-recsys.
The Quest for Reliable Metrics of Responsible AI
Oct 29, 2025The development of Artificial Intelligence (AI), including AI in Science (AIS), should be done following the principles of responsible AI. Progress in responsible AI is often quantified through evaluation metrics, yet there has been less work on assessing the robustness and reliability of the metrics themselves. We reflect on prior work that examines the robustness of fairness metrics for recommender systems as a type of AI application and summarise their key takeaways into a set of non-exhaustive guidelines for developing reliable metrics of responsible AI. Our guidelines apply to a broad spectrum of AI applications, including AIS.
Joint Evaluation of Fairness and Relevance in Recommender Systems with Pareto Frontier
Feb 17, 2025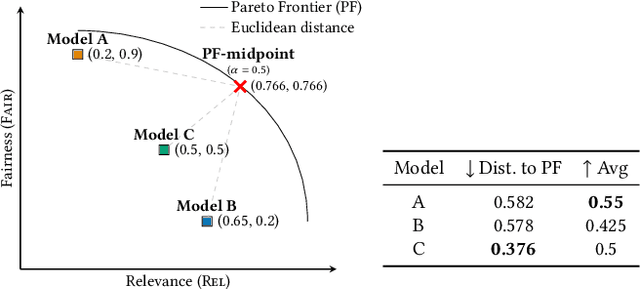
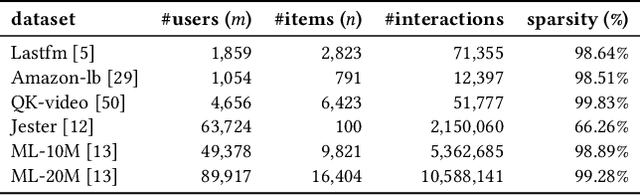
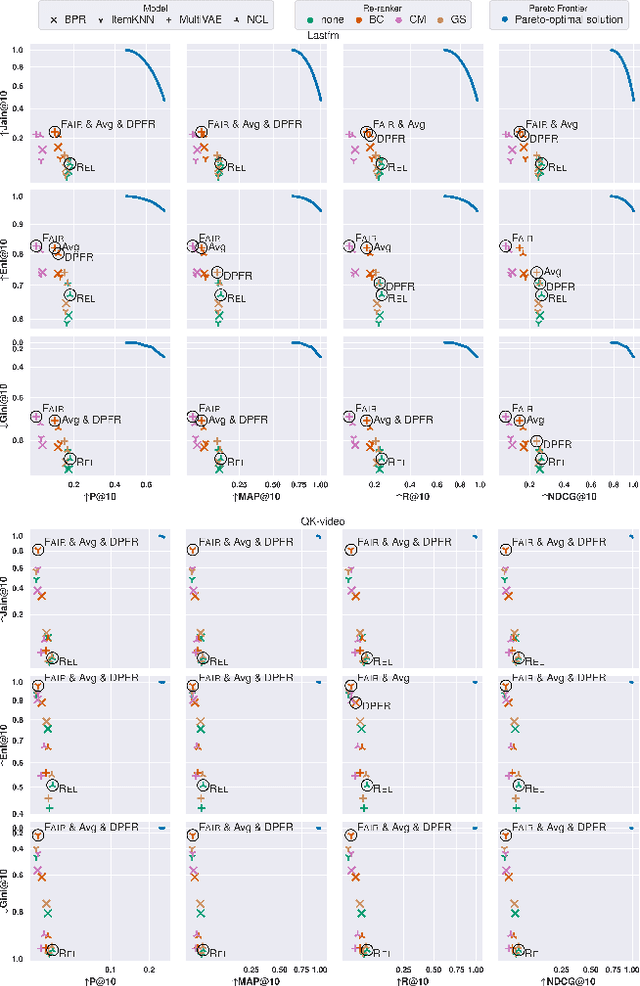
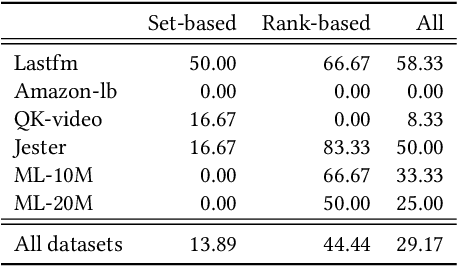
Fairness and relevance are two important aspects of recommender systems (RSs). Typically, they are evaluated either (i) separately by individual measures of fairness and relevance, or (ii) jointly using a single measure that accounts for fairness with respect to relevance. However, approach (i) often does not provide a reliable joint estimate of the goodness of the models, as it has two different best models: one for fairness and another for relevance. Approach (ii) is also problematic because these measures tend to be ad-hoc and do not relate well to traditional relevance measures, like NDCG. Motivated by this, we present a new approach for jointly evaluating fairness and relevance in RSs: Distance to Pareto Frontier (DPFR). Given some user-item interaction data, we compute their Pareto frontier for a pair of existing relevance and fairness measures, and then use the distance from the frontier as a measure of the jointly achievable fairness and relevance. Our approach is modular and intuitive as it can be computed with existing measures. Experiments with 4 RS models, 3 re-ranking strategies, and 6 datasets show that existing metrics have inconsistent associations with our Pareto-optimal solution, making DPFR a more robust and theoretically well-founded joint measure for assessing fairness and relevance. Our code: https://github.com/theresiavr/DPFR-recsys-evaluation
Can We Trust Recommender System Fairness Evaluation? The Role of Fairness and Relevance
May 28, 2024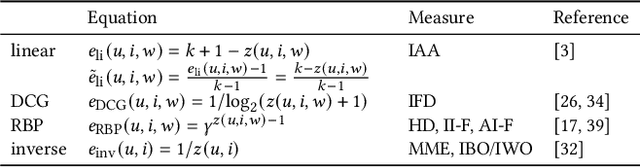
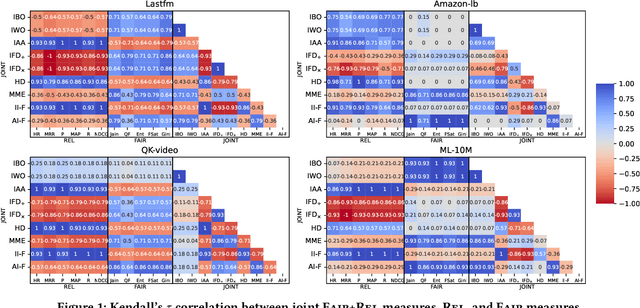
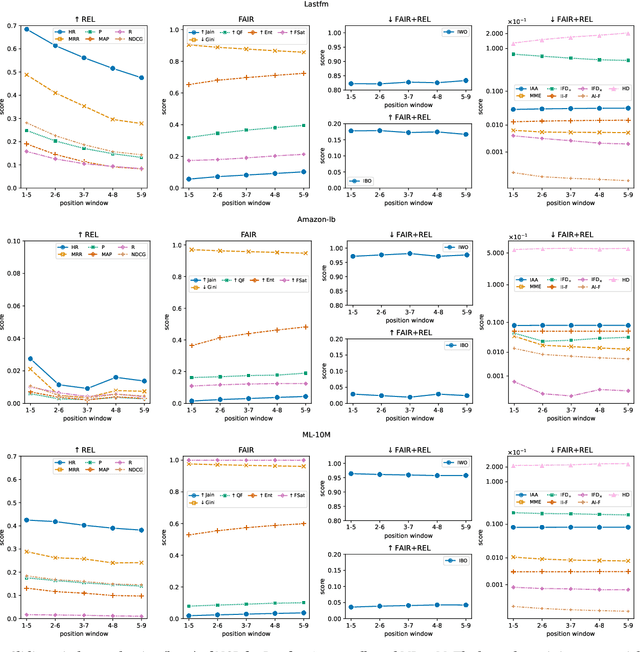
Relevance and fairness are two major objectives of recommender systems (RSs). Recent work proposes measures of RS fairness that are either independent from relevance (fairness-only) or conditioned on relevance (joint measures). While fairness-only measures have been studied extensively, we look into whether joint measures can be trusted. We collect all joint evaluation measures of RS relevance and fairness, and ask: How much do they agree with each other? To what extent do they agree with relevance/fairness measures? How sensitive are they to changes in rank position, or to increasingly fair and relevant recommendations? We empirically study for the first time the behaviour of these measures across 4 real-world datasets and 4 recommenders. We find that most of these measures: i) correlate weakly with one another and even contradict each other at times; ii) are less sensitive to rank position changes than relevance- and fairness-only measures, meaning that they are less granular than traditional RS measures; and iii) tend to compress scores at the low end of their range, meaning that they are not very expressive. We counter the above limitations with a set of guidelines on the appropriate usage of such measures, i.e., they should be used with caution due to their tendency to contradict each other and of having a very small empirical range.
Evaluation Measures of Individual Item Fairness for Recommender Systems: A Critical Study
Nov 02, 2023



Fairness is an emerging and challenging topic in recommender systems. In recent years, various ways of evaluating and therefore improving fairness have emerged. In this study, we examine existing evaluation measures of fairness in recommender systems. Specifically, we focus solely on exposure-based fairness measures of individual items that aim to quantify the disparity in how individual items are recommended to users, separate from item relevance to users. We gather all such measures and we critically analyse their theoretical properties. We identify a series of limitations in each of them, which collectively may render the affected measures hard or impossible to interpret, to compute, or to use for comparing recommendations. We resolve these limitations by redefining or correcting the affected measures, or we argue why certain limitations cannot be resolved. We further perform a comprehensive empirical analysis of both the original and our corrected versions of these fairness measures, using real-world and synthetic datasets. Our analysis provides novel insights into the relationship between measures based on different fairness concepts, and different levels of measure sensitivity and strictness. We conclude with practical suggestions of which fairness measures should be used and when. Our code is publicly available. To our knowledge, this is the first critical comparison of individual item fairness measures in recommender systems.