 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Denoising of User Profiles with LLMs in Collaborative Filtering Recommendation
Jan 25, 2026Implicit feedback -- the main data source for training Recommender Systems (RSs) -- is inherently noisy and has been shown to negatively affect recommendation effectiveness. Denoising has been proposed as a method for removing noisy implicit feedback and improving recommendations. Prior work has focused on in-training denoising, however this requires additional data, changes to the model architecture and training procedure or fine-tuning, all of which can be costly and data hungry. In this work, we focus on post-training denoising. Different from in-training denoising, post-training denoising does not involve changing the architecture of the model nor its training procedure, and does not require additional data. Specifically, we present a method for post-training denoising user profiles using Large Language Models (LLMs) for Collaborative Filtering (CF) recommendations. Our approach prompts LLMs with (i) a user profile (user interactions), (ii) a candidate item, and (iii) its rank as given by the CF recommender, and asks the LLM to remove items from the user profile to improve the rank of the candidate item. Experiments with a state-of-the-art CF recommender and 4 open and closed source LLMs in 3 datasets show that our denoising yields improvements up to 13% in effectiveness over the original user profiles. Our code is available at https://github.com/edervishaj/denoising-user-profiles-LLM.
Measuring Individual User Fairness with User Similarity and Effectiveness Disparity
Jan 23, 2026Individual user fairness is commonly understood as treating similar users similarly. In Recommender Systems (RSs), several evaluation measures exist for quantifying individual user fairness. These measures evaluate fairness via either: (i) the disparity in RS effectiveness scores regardless of user similarity, or (ii) the disparity in items recommended to similar users regardless of item relevance. Both disparity in recommendation effectiveness and user similarity are very important in fairness, yet no existing individual user fairness measure simultaneously accounts for both. In brief, current user fairness evaluation measures implement a largely incomplete definition of fairness. To fill this gap, we present Pairwise User unFairness (PUF), a novel evaluation measure of individual user fairness that considers both effectiveness disparity and user similarity. PUF is the only measure that can express this important distinction. We empirically validate that PUF does this consistently across 4 datasets and 7 rankers, and robustly when varying user similarity or effectiveness. In contrast, all other measures are either almost insensitive to effectiveness disparity or completely insensitive to user similarity. We contribute the first RS evaluation measure to reliably capture both user similarity and effectiveness in individual user fairness. Our code: https://github.com/theresiavr/PUF-individual-user-fairness-recsys.
The Quest for Reliable Metrics of Responsible AI
Oct 29, 2025The development of Artificial Intelligence (AI), including AI in Science (AIS), should be done following the principles of responsible AI. Progress in responsible AI is often quantified through evaluation metrics, yet there has been less work on assessing the robustness and reliability of the metrics themselves. We reflect on prior work that examines the robustness of fairness metrics for recommender systems as a type of AI application and summarise their key takeaways into a set of non-exhaustive guidelines for developing reliable metrics of responsible AI. Our guidelines apply to a broad spectrum of AI applications, including AIS.
Self-Calibrating BCIs: Ranking and Recovery of Mental Targets Without Labels
Jun 11, 2025We consider the problem of recovering a mental target (e.g., an image of a face) that a participant has in mind from paired EEG (i.e., brain responses) and image (i.e., perceived faces) data collected during interactive sessions without access to labeled information. The problem has been previously explored with labeled data but not via self-calibration, where labeled data is unavailable. Here, we present the first framework and an algorithm, CURSOR, that learns to recover unknown mental targets without access to labeled data or pre-trained decoders. Our experiments on naturalistic images of faces demonstrate that CURSOR can (1) predict image similarity scores that correlate with human perceptual judgments without any label information, (2) use these scores to rank stimuli against an unknown mental target, and (3) generate new stimuli indistinguishable from the unknown mental target (validated via a user study, N=53).
GIM: Improved Interpretability for Large Language Models
May 23, 2025Ensuring faithful interpretability in large language models is imperative for trustworthy and reliable AI. A key obstacle is self-repair, a phenomenon where networks compensate for reduced signal in one component by amplifying others, masking the true importance of the ablated component. While prior work attributes self-repair to layer normalization and back-up components that compensate for ablated components, we identify a novel form occurring within the attention mechanism, where softmax redistribution conceals the influence of important attention scores. This leads traditional ablation and gradient-based methods to underestimate the significance of all components contributing to these attention scores. We introduce Gradient Interaction Modifications (GIM), a technique that accounts for self-repair during backpropagation. Extensive experiments across multiple large language models (Gemma 2B/9B, LLAMA 1B/3B/8B, Qwen 1.5B/3B) and diverse tasks demonstrate that GIM significantly improves faithfulness over existing circuit identification and feature attribution methods. Our work is a significant step toward better understanding the inner mechanisms of LLMs, which is crucial for improving them and ensuring their safety. Our code is available at https://github.com/JoakimEdin/gim.
As easy as PIE: understanding when pruning causes language models to disagree
Mar 27, 2025
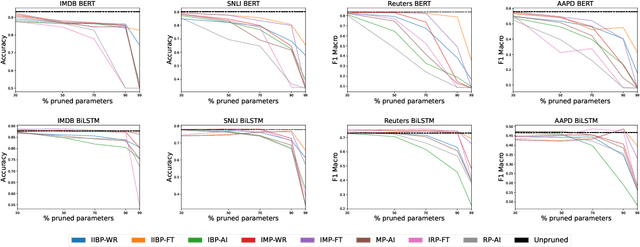

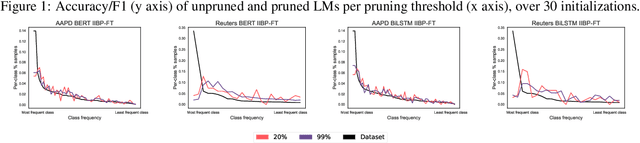
Language Model (LM) pruning compresses the model by removing weights, nodes, or other parts of its architecture. Typically, pruning focuses on the resulting efficiency gains at the cost of effectiveness. However, when looking at how individual data points are affected by pruning, it turns out that a particular subset of data points always bears most of the brunt (in terms of reduced accuracy) when pruning, but this effect goes unnoticed when reporting the mean accuracy of all data points. These data points are called PIEs and have been studied in image processing, but not in NLP. In a study of various NLP datasets, pruning methods, and levels of compression, we find that PIEs impact inference quality considerably, regardless of class frequency, and that BERT is more prone to this than BiLSTM. We also find that PIEs contain a high amount of data points that have the largest influence on how well the model generalises to unseen data. This means that when pruning, with seemingly moderate loss to accuracy across all data points, we in fact hurt tremendously those data points that matter the most. We trace what makes PIEs both hard and impactful to inference to their overall longer and more semantically complex text. These findings are novel and contribute to understanding how LMs are affected by pruning. The code is available at: https://github.com/pietrotrope/AsEasyAsPIE
Joint Evaluation of Fairness and Relevance in Recommender Systems with Pareto Frontier
Feb 17, 2025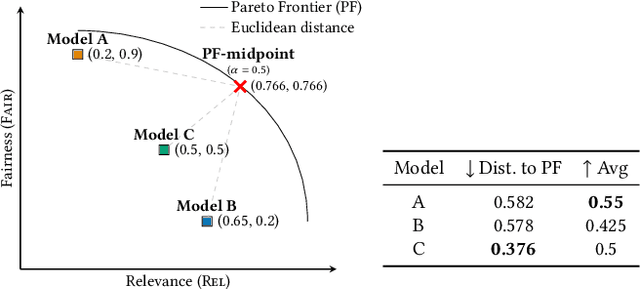
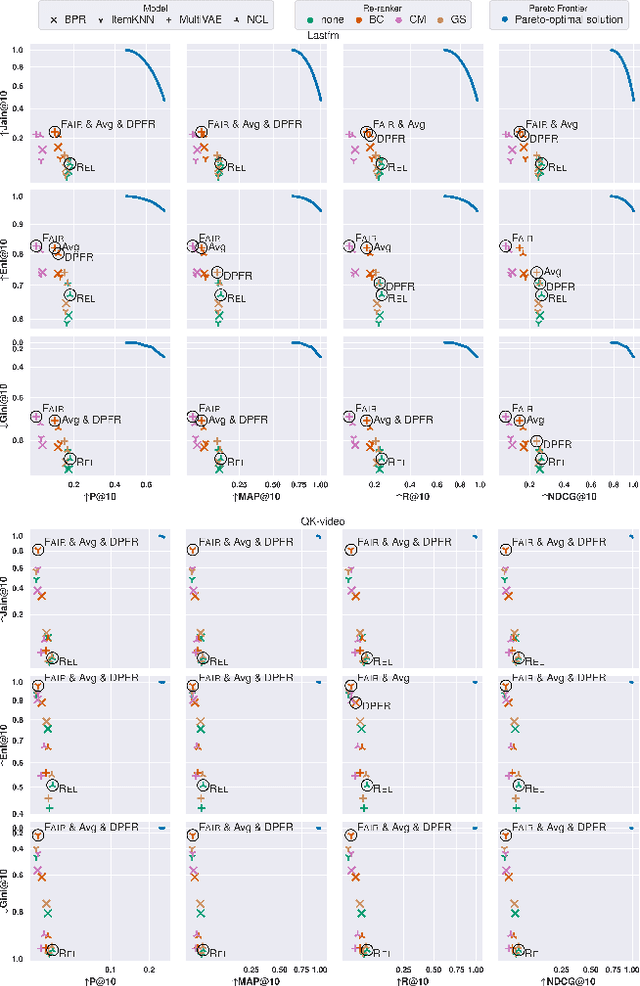
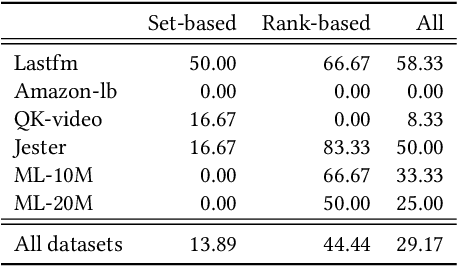
Fairness and relevance are two important aspects of recommender systems (RSs). Typically, they are evaluated either (i) separately by individual measures of fairness and relevance, or (ii) jointly using a single measure that accounts for fairness with respect to relevance. However, approach (i) often does not provide a reliable joint estimate of the goodness of the models, as it has two different best models: one for fairness and another for relevance. Approach (ii) is also problematic because these measures tend to be ad-hoc and do not relate well to traditional relevance measures, like NDCG. Motivated by this, we present a new approach for jointly evaluating fairness and relevance in RSs: Distance to Pareto Frontier (DPFR). Given some user-item interaction data, we compute their Pareto frontier for a pair of existing relevance and fairness measures, and then use the distance from the frontier as a measure of the jointly achievable fairness and relevance. Our approach is modular and intuitive as it can be computed with existing measures. Experiments with 4 RS models, 3 re-ranking strategies, and 6 datasets show that existing metrics have inconsistent associations with our Pareto-optimal solution, making DPFR a more robust and theoretically well-founded joint measure for assessing fairness and relevance. Our code: https://github.com/theresiavr/DPFR-recsys-evaluation
Are Representation Disentanglement and Interpretability Linked in Recommendation Models? A Critical Review and Reproducibility Study
Jan 30, 2025



Unsupervised learning of disentangled representations has been closely tied to enhancing the representation intepretability of Recommender Systems (RSs). This has been achieved by making the representation of individual features more distinctly separated, so that it is easier to attribute the contribution of features to the model's predictions. However, such advantages in interpretability and feature attribution have mainly been explored qualitatively. Moreover, the effect of disentanglement on the model's recommendation performance has been largely overlooked. In this work, we reproduce the recommendation performance, representation disentanglement and representation interpretability of five well-known recommendation models on four RS datasets. We quantify disentanglement and investigate the link of disentanglement with recommendation effectiveness and representation interpretability. While several existing work in RSs have proposed disentangled representations as a gateway to improved effectiveness and interpretability, our findings show that disentanglement is not necessarily related to effectiveness but is closely related to representation interpretability. Our code and results are publicly available at https://github.com/edervishaj/disentanglement-interpretability-recsys.
Normalized AOPC: Fixing Misleading Faithfulness Metrics for Feature Attribution Explainability
Aug 15, 2024



Deep neural network predictions are notoriously difficult to interpret. Feature attribution methods aim to explain these predictions by identifying the contribution of each input feature. Faithfulness, often evaluated using the area over the perturbation curve (AOPC), reflects feature attributions' accuracy in describing the internal mechanisms of deep neural networks. However, many studies rely on AOPC to compare faithfulness across different models, which we show can lead to false conclusions about models' faithfulness. Specifically, we find that AOPC is sensitive to variations in the model, resulting in unreliable cross-model comparisons. Moreover, AOPC scores are difficult to interpret in isolation without knowing the model-specific lower and upper limits. To address these issues, we propose a normalization approach, Normalized AOPC (NAOPC), enabling consistent cross-model evaluations and more meaningful interpretation of individual scores. Our experiments demonstrate that this normalization can radically change AOPC results, questioning the conclusions of earlier studies and offering a more robust framework for assessing feature attribution faithfulness.
An Unsupervised Approach to Achieve Supervised-Level Explainability in Healthcare Records
Jun 13, 2024Electronic healthcare records are vital for patient safety as they document conditions, plans, and procedures in both free text and medical codes. Language models have significantly enhanced the processing of such records, streamlining workflows and reducing manual data entry, thereby saving healthcare providers significant resources. However, the black-box nature of these models often leaves healthcare professionals hesitant to trust them. State-of-the-art explainability methods increase model transparency but rely on human-annotated evidence spans, which are costly. In this study, we propose an approach to produce plausible and faithful explanations without needing such annotations. We demonstrate on the automated medical coding task that adversarial robustness training improves explanation plausibility and introduce AttInGrad, a new explanation method superior to previous ones. By combining both contributions in a fully unsupervised setup, we produce explanations of comparable quality, or better, to that of a supervised approach. We release our code and model weights.