 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized AOPC: Fixing Misleading Faithfulness Metrics for Feature Attribution Explainability
Aug 15, 2024



Deep neural network predictions are notoriously difficult to interpret. Feature attribution methods aim to explain these predictions by identifying the contribution of each input feature. Faithfulness, often evaluated using the area over the perturbation curve (AOPC), reflects feature attributions' accuracy in describing the internal mechanisms of deep neural networks. However, many studies rely on AOPC to compare faithfulness across different models, which we show can lead to false conclusions about models' faithfulness. Specifically, we find that AOPC is sensitive to variations in the model, resulting in unreliable cross-model comparisons. Moreover, AOPC scores are difficult to interpret in isolation without knowing the model-specific lower and upper limits. To address these issues, we propose a normalization approach, Normalized AOPC (NAOPC), enabling consistent cross-model evaluations and more meaningful interpretation of individual scores. Our experiments demonstrate that this normalization can radically change AOPC results, questioning the conclusions of earlier studies and offering a more robust framework for assessing feature attribution faithfulness.
Variational Open-Domain Question Answering
Sep 23, 2022
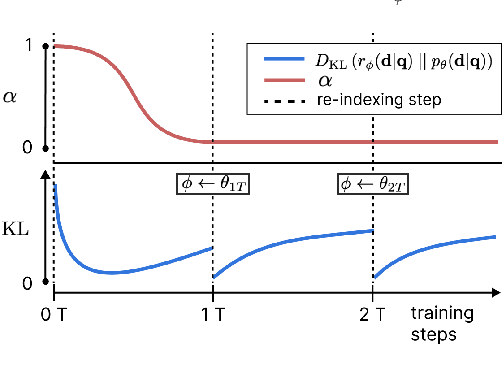
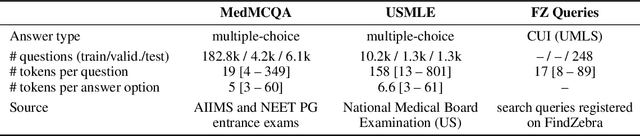
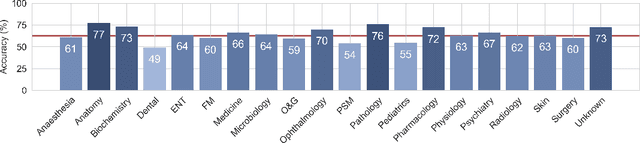
We introduce the Variational Open-Domain (VOD) framework for end-to-end training and evaluation of retrieval-augmented models (open-domain question answering and language modelling). We show that the R\'enyi variational bound, a lower bound to the task marginal likelihood, can be exploited to aid optimization and use importance sampling to estimate the task log-likelihood lower bound and its gradients using samples drawn from an auxiliary retriever (approximate posterior). The framework can be used to train modern retrieval-augmented systems end-to-end using tractable and consistent estimates of the R\'enyi variational bound and its gradients. We demonstrate the framework's versatility by training reader-retriever BERT-based models on multiple-choice medical exam questions (MedMCQA and USMLE). We registered a new state-of-the-art for both datasets (MedMCQA: $62.9$\%, USMLE: $55.0$\%). Last, we show that the retriever part of the learned reader-retriever model trained on the medical board exam questions can be used in search engines for a medical knowledge base.