 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIM: Improved Interpretability for Large Language Models
May 23, 2025Ensuring faithful interpretability in large language models is imperative for trustworthy and reliable AI. A key obstacle is self-repair, a phenomenon where networks compensate for reduced signal in one component by amplifying others, masking the true importance of the ablated component. While prior work attributes self-repair to layer normalization and back-up components that compensate for ablated components, we identify a novel form occurring within the attention mechanism, where softmax redistribution conceals the influence of important attention scores. This leads traditional ablation and gradient-based methods to underestimate the significance of all components contributing to these attention scores. We introduce Gradient Interaction Modifications (GIM), a technique that accounts for self-repair during backpropagation. Extensive experiments across multiple large language models (Gemma 2B/9B, LLAMA 1B/3B/8B, Qwen 1.5B/3B) and diverse tasks demonstrate that GIM significantly improves faithfulness over existing circuit identification and feature attribution methods. Our work is a significant step toward better understanding the inner mechanisms of LLMs, which is crucial for improving them and ensuring their safety. Our code is available at https://github.com/JoakimEdin/gim.
Do Language Models Use Their Depth Efficiently?
May 20, 2025



Modern LLMs are increasingly deep, and depth correlates with performance, albeit with diminishing returns. However, do these models use their depth efficiently? Do they compose more features to create higher-order computations that are impossible in shallow models, or do they merely spread the same kinds of computation out over more layers? To address these questions, we analyze the residual stream of the Llama 3.1 and Qwen 3 family of models. We find: First, comparing the output of the sublayers to the residual stream reveals that layers in the second half contribute much less than those in the first half, with a clear phase transition between the two halves. Second, skipping layers in the second half has a much smaller effect on future computations and output predictions. Third, for multihop tasks, we are unable to find evidence that models are using increased depth to compose subresults in examples involving many hops. Fourth, we seek to directly address whether deeper models are using their additional layers to perform new kinds of computation. To do this, we train linear maps from the residual stream of a shallow model to a deeper one. We find that layers with the same relative depth map best to each other, suggesting that the larger model simply spreads the same computations out over its many layers. All this evidence suggests that deeper models are not using their depth to learn new kinds of computation, but only using the greater depth to perform more fine-grained adjustments to the residual. This may help explain why increasing scale leads to diminishing returns for stacked Transformer architectures.
Mixture of Sparse Attention: Content-Based Learnable Sparse Attention via Expert-Choice Routing
May 01, 2025Recent advances in large language models highlighted the excessive quadratic cost of self-attention. Despite the significant research efforts, subquadratic attention methods still suffer from inferior performance in practice. We hypothesize that dynamic, learned content-based sparsity can lead to more efficient attention mechanisms. We present Mixture of Sparse Attention (MoSA), a novel approach inspired by Mixture of Experts (MoE) with expert choice routing. MoSA dynamically selects tokens for each attention head, allowing arbitrary sparse attention patterns. By selecting $k$ tokens from a sequence of length $T$, MoSA reduces the computational complexity of each attention head from $O(T^2)$ to $O(k^2 + T)$. This enables using more heads within the same computational budget, allowing higher specialization. We show that among the tested sparse attention variants, MoSA is the only one that can outperform the dense baseline, sometimes with up to 27% better perplexity for an identical compute budget. MoSA can also reduce the resource usage compared to dense self-attention. Despite using torch implementation without an optimized kernel, perplexity-matched MoSA models are simultaneously faster in wall-clock time, require less memory for training, and drastically reduce the size of the KV-cache compared to the dense transformer baselines.
Measuring In-Context Computation Complexity via Hidden State Prediction
Mar 17, 2025

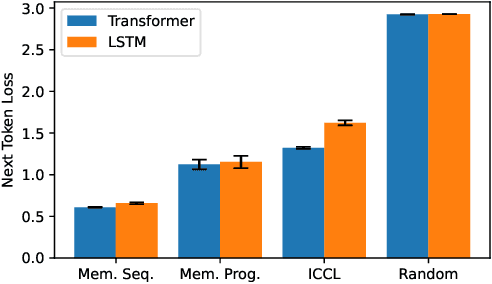

Detecting when a neural sequence model does "interesting" computation is an open problem. The next token prediction loss is a poor indicator: Low loss can stem from trivially predictable sequences that are uninteresting, while high loss may reflect unpredictable but also irrelevant information that can be ignored by the model. We propose a better metric: measuring the model's ability to predict its own future hidden states. We show empirically that this metric -- in contrast to the next token prediction loss -- correlates with the intuitive interestingness of the task. To measure predictability, we introduce the architecture-agnostic "prediction of hidden states" (PHi) layer that serves as an information bottleneck on the main pathway of the network (e.g., the residual stream in Transformers). We propose a novel learned predictive prior that enables us to measure the novel information gained in each computation step, which serves as our metric. We show empirically that our metric predicts the description length of formal languages learned in-context, the complexity of mathematical reasoning problems, and the correctness of self-generated reasoning chains.
MrT5: Dynamic Token Merging for Efficient Byte-level Language Models
Oct 28, 2024Models that rely on subword tokenization have significant drawbacks, such as sensitivity to character-level noise like spelling errors and inconsistent compression rates across different languages and scripts. While character- or byte-level models like ByT5 attempt to address these concerns, they have not gained widespread adoption -- processing raw byte streams without tokenization results in significantly longer sequence lengths, making training and inference inefficient. This work introduces MrT5 (MergeT5), a more efficient variant of ByT5 that integrates a token deletion mechanism in its encoder to dynamically shorten the input sequence length. After processing through a fixed number of encoder layers, a learnt delete gate determines which tokens are to be removed and which are to be retained for subsequent layers. MrT5 effectively ``merges'' critical information from deleted tokens into a more compact sequence, leveraging contextual information from the remaining tokens. In continued pre-training experiments, we find that MrT5 can achieve significant gains in inference runtime with minimal effect on performance. When trained on English text, MrT5 demonstrates the capability to transfer its deletion feature zero-shot across several languages, with significant additional improvements following multilingual training. Furthermore, MrT5 shows comparable accuracy to ByT5 on downstream evaluations such as XNLI and character-level tasks while reducing sequence lengths by up to 80%. Our approach presents a solution to the practical limitations of existing byte-level models.
Recurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations
Aug 20, 2024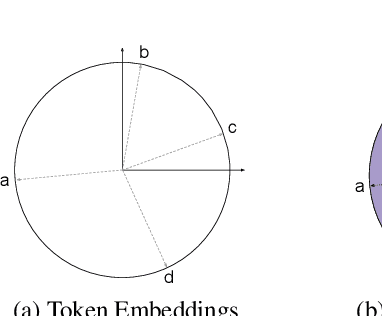

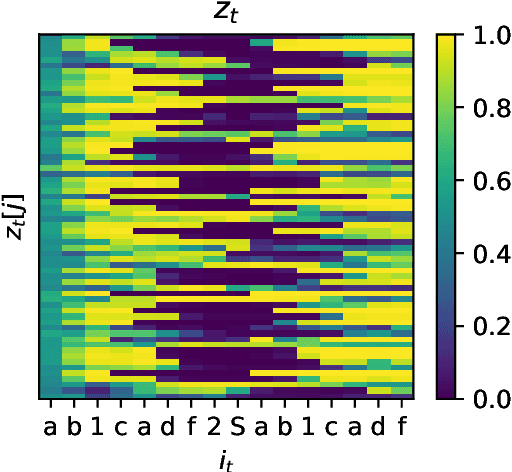
The Linear Representation Hypothesis (LRH) states that neural networks learn to encode concepts as directions in activation space, and a strong version of the LRH states that models learn only such encodings. In this paper, we present a counterexample to this strong LRH: when trained to repeat an input token sequence, gated recurrent neural networks (RNNs) learn to represent the token at each position with a particular order of magnitude, rather than a direction. These representations have layered features that are impossible to locate in distinct linear subspaces. To show this, we train interventions to predict and manipulate tokens by learning the scaling factor corresponding to each sequence position. These interventions indicate that the smallest RNNs find only this magnitude-based solution, while larger RNNs have linear representations. These findings strongly indicate that interpretability research should not be confined by the LRH.
MoEUT: Mixture-of-Experts Universal Transformers
May 25, 2024Previous work on Universal Transformers (UTs) has demonstrated the importance of parameter sharing across layers. By allowing recurrence in depth, UTs have advantages over standard Transformers in learning compositional generalizations, but layer-sharing comes with a practical limitation of parameter-compute ratio: it drastically reduces the parameter count compared to the non-shared model with the same dimensionality. Naively scaling up the layer size to compensate for the loss of parameters makes its computational resource requirements prohibitive. In practice, no previous work has succeeded in proposing a shared-layer Transformer design that is competitive in parameter count-dominated tasks such as language modeling. Here we propose MoEUT (pronounced "moot"), an effective mixture-of-experts (MoE)-based shared-layer Transformer architecture, which combines several recent advances in MoEs for both feedforward and attention layers of standard Transformers together with novel layer-normalization and grouping schemes that are specific and crucial to UTs. The resulting UT model, for the first time, slightly outperforms standard Transformers on language modeling tasks such as BLiMP and PIQA, while using significantly less compute and memory.
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
Dec 14, 2023



The costly self-attention layers in modern Transformers require memory and compute quadratic in sequence length. Existing approximation methods usually underperform and fail to obtain significant speedups in practice. Here we present SwitchHead - a novel method that reduces both compute and memory requirements and achieves wall-clock speedup, while matching the language modeling performance of baseline Transformers with the same parameter budget. SwitchHead uses Mixture-of-Experts (MoE) layers for the value and output projections and requires 4 to 8 times fewer attention matrices than standard Transformers. Our novel attention can also be combined with MoE MLP layers, resulting in an efficient fully-MoE "SwitchAll" Transformer model. Our code is public.
Automating Continual Learning
Dec 01, 2023General-purpose learning systems should improve themselves in open-ended fashion in ever-changing environments. Conventional learning algorithms for neural networks, however, suffer from catastrophic forgetting (CF) -- previously acquired skills are forgotten when a new task is learned. Instead of hand-crafting new algorithms for avoiding CF, we propose Automated Continual Learning (ACL) to train self-referential neural networks to meta-learn their own in-context continual (meta-)learning algorithms. ACL encodes all desiderata -- good performance on both old and new tasks -- into its meta-learning objectives. Our experiments demonstrate that ACL effectively solves "in-context catastrophic forgetting"; our ACL-learned algorithms outperform hand-crafted ones, e.g., on the Split-MNIST benchmark in the replay-free setting, and enables continual learning of diverse tasks consisting of multiple few-shot and standard image classification datasets.
Practical Computational Power of Linear Transformers and Their Recurrent and Self-Referential Extensions
Oct 24, 2023Recent studies of the computational power of recurrent neural networks (RNNs) reveal a hierarchy of RNN architectures, given real-time and finite-precision assumptions. Here we study auto-regressive Transformers with linearised attention, a.k.a. linear Transformers (LTs) or Fast Weight Programmers (FWPs). LTs are special in the sense that they are equivalent to RNN-like sequence processors with a fixed-size state, while they can also be expressed as the now-popular self-attention networks. We show that many well-known results for the standard Transformer directly transfer to LTs/FWPs. Our formal language recognition experiments demonstrate how recently proposed FWP extensions such as recurrent FWPs and self-referential weight matrices successfully overcome certain limitations of the LT, e.g., allowing for generalisation on the parity problem. Our code is public.