 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Networks Learn to Store and Generate Sequences using Non-Linear Representations
Paper and Code
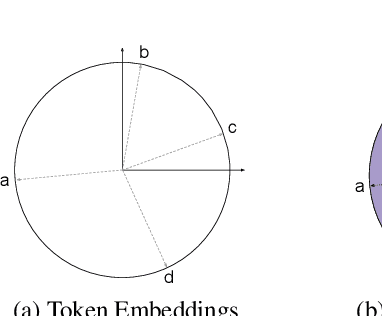
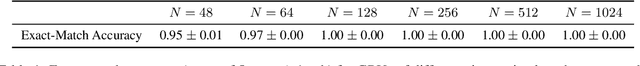

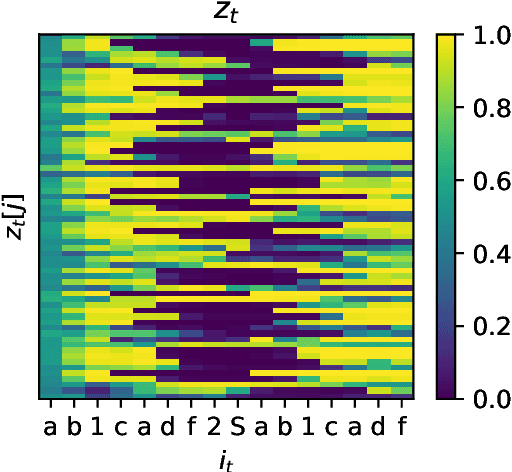
The Linear Representation Hypothesis (LRH) states that neural networks learn to encode concepts as directions in activation space, and a strong version of the LRH states that models learn only such encodings. In this paper, we present a counterexample to this strong LRH: when trained to repeat an input token sequence, gated recurrent neural networks (RNNs) learn to represent the token at each position with a particular order of magnitude, rather than a direction. These representations have layered features that are impossible to locate in distinct linear subspaces. To show this, we train interventions to predict and manipulate tokens by learning the scaling factor corresponding to each sequence position. These interventions indicate that the smallest RNNs find only this magnitude-based solution, while larger RNNs have linear representations. These findings strongly indicate that interpretability research should not be confined by the LRH.