 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring In-Context Computation Complexity via Hidden State Prediction
Paper and Code
Mar 17, 2025

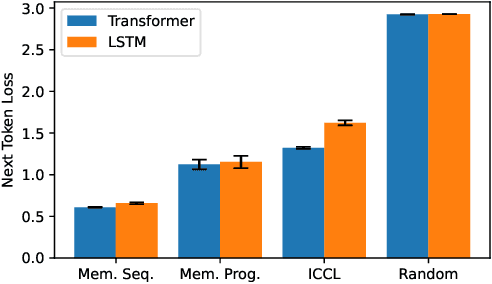

Detecting when a neural sequence model does "interesting" computation is an open problem. The next token prediction loss is a poor indicator: Low loss can stem from trivially predictable sequences that are uninteresting, while high loss may reflect unpredictable but also irrelevant information that can be ignored by the model. We propose a better metric: measuring the model's ability to predict its own future hidden states. We show empirically that this metric -- in contrast to the next token prediction loss -- correlates with the intuitive interestingness of the task. To measure predictability, we introduce the architecture-agnostic "prediction of hidden states" (PHi) layer that serves as an information bottleneck on the main pathway of the network (e.g., the residual stream in Transformers). We propose a novel learned predictive prior that enables us to measure the novel information gained in each computation step, which serves as our metric. We show empirically that our metric predicts the description length of formal languages learned in-context, the complexity of mathematical reasoning problems, and the correctness of self-generated reasoning chains.