 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
Hyperbolic Residual Quantization: Discrete Representations for Data with Latent Hierarchies
May 18, 2025Hierarchical data arise in countless domains, from biological taxonomies and organizational charts to legal codes and knowledge graphs. Residual Quantization (RQ) is widely used to generate discrete, multitoken representations for such data by iteratively quantizing residuals in a multilevel codebook. However, its reliance on Euclidean geometry can introduce fundamental mismatches that hinder modeling of hierarchical branching, necessary for faithful representation of hierarchical data. In this work, we propose Hyperbolic Residual Quantization (HRQ), which embeds data natively in a hyperbolic manifold and performs residual quantization using hyperbolic operations and distance metrics. By adapting the embedding network, residual computation, and distance metric to hyperbolic geometry, HRQ imparts an inductive bias that aligns naturally with hierarchical branching. We claim that HRQ in comparison to RQ can generate more useful for downstream tasks discrete hierarchical representations for data with latent hierarchies. We evaluate HRQ on two tasks: supervised hierarchy modeling using WordNet hypernym trees, where the model is supervised to learn the latent hierarchy - and hierarchy discovery, where, while latent hierarchy exists in the data, the model is not directly trained or evaluated on a task related to the hierarchy. Across both scenarios, HRQ hierarchical tokens yield better performance on downstream tasks compared to Euclidean RQ with gains of up to $20\%$ for the hierarchy modeling task. Our results demonstrate that integrating hyperbolic geometry into discrete representation learning substantially enhances the ability to capture latent hierarchies.
Mixture of Sparse Attention: Content-Based Learnable Sparse Attention via Expert-Choice Routing
May 01, 2025Recent advances in large language models highlighted the excessive quadratic cost of self-attention. Despite the significant research efforts, subquadratic attention methods still suffer from inferior performance in practice. We hypothesize that dynamic, learned content-based sparsity can lead to more efficient attention mechanisms. We present Mixture of Sparse Attention (MoSA), a novel approach inspired by Mixture of Experts (MoE) with expert choice routing. MoSA dynamically selects tokens for each attention head, allowing arbitrary sparse attention patterns. By selecting $k$ tokens from a sequence of length $T$, MoSA reduces the computational complexity of each attention head from $O(T^2)$ to $O(k^2 + T)$. This enables using more heads within the same computational budget, allowing higher specialization. We show that among the tested sparse attention variants, MoSA is the only one that can outperform the dense baseline, sometimes with up to 27% better perplexity for an identical compute budget. MoSA can also reduce the resource usage compared to dense self-attention. Despite using torch implementation without an optimized kernel, perplexity-matched MoSA models are simultaneously faster in wall-clock time, require less memory for training, and drastically reduce the size of the KV-cache compared to the dense transformer baselines.
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
Dec 14, 2023



The costly self-attention layers in modern Transformers require memory and compute quadratic in sequence length. Existing approximation methods usually underperform and fail to obtain significant speedups in practice. Here we present SwitchHead - a novel method that reduces both compute and memory requirements and achieves wall-clock speedup, while matching the language modeling performance of baseline Transformers with the same parameter budget. SwitchHead uses Mixture-of-Experts (MoE) layers for the value and output projections and requires 4 to 8 times fewer attention matrices than standard Transformers. Our novel attention can also be combined with MoE MLP layers, resulting in an efficient fully-MoE "SwitchAll" Transformer model. Our code is public.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023



Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
Jun 01, 2022
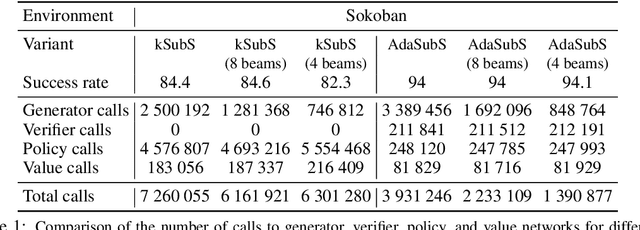
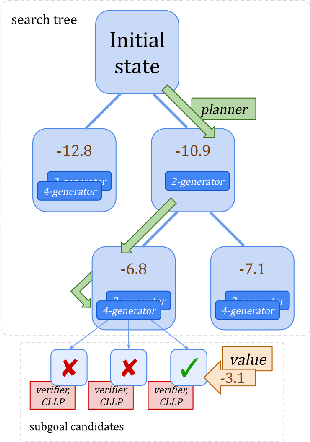
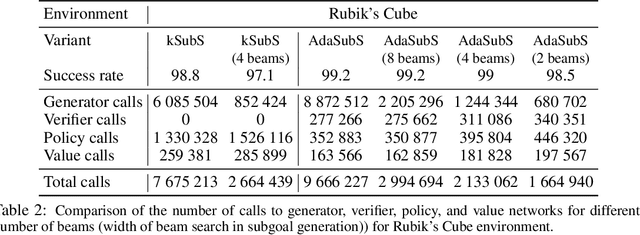
Complex reasoning problems contain states that vary in the computational cost required to determine a good action plan. Taking advantage of this property, we propose Adaptive Subgoal Search (AdaSubS), a search method that adaptively adjusts the planning horizon. To this end, AdaSubS generates diverse sets of subgoals at different distances. A verification mechanism is employed to filter out unreachable subgoals swiftly and thus allowing to focus on feasible further subgoals. In this way, AdaSubS benefits from the efficiency of planning with longer subgoals and the fine control with the shorter ones. We show that AdaSubS significantly surpasses hierarchical planning algorithms on three complex reasoning tasks: Sokoban, the Rubik's Cube, and inequality proving benchmark INT, setting new state-of-the-art on INT.
Measuring and Improving BERT's Mathematical Abilities by Predicting the Order of Reasoning
Jun 07, 2021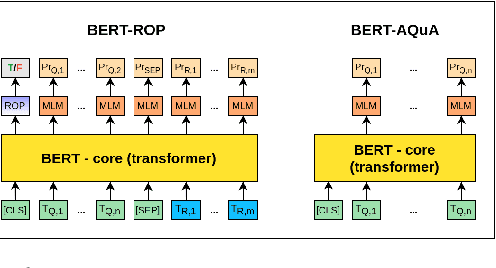
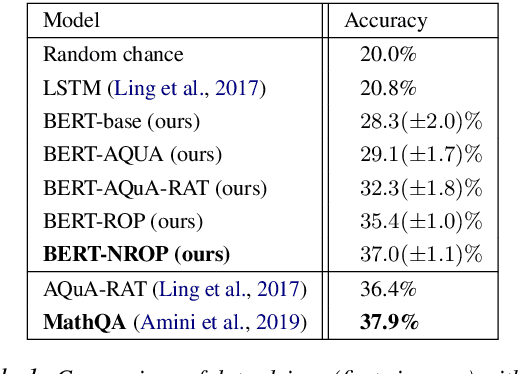


Imagine you are in a supermarket. You have two bananas in your basket and want to buy four apples. How many fruits do you have in total? This seemingly straightforward question can be challenging for data-driven language models, even if trained at scale. However, we would expect such generic language models to possess some mathematical abilities in addition to typical linguistic competence. Towards this goal, we investigate if a commonly used language model, BERT, possesses such mathematical abilities and, if so, to what degree. For that, we fine-tune BERT on a popular dataset for word math problems, AQuA-RAT, and conduct several tests to understand learned representations better. Since we teach models trained on natural language to do formal mathematics, we hypothesize that such models would benefit from training on semi-formal steps that explain how math results are derived. To better accommodate such training, we also propose new pretext tasks for learning mathematical rules. We call them (Neighbor) Reasoning Order Prediction (ROP or NROP). With this new model, we achieve significantly better outcomes than data-driven baselines and even on-par with more tailored models. We also show how to reduce positional bias in such models.