 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
May 14, 2026We introduce SANA-WM, an efficient 2.6B-parameter open-source world model natively trained for one-minute generation, synthesizing high-fidelity, 720p, minute-scale videos with precise camera control. SANA-WM achieves visual quality comparable to large-scale industrial baselines such as LingBot-World and HY-WorldPlay, while significantly improving efficiency. Four core designs drive our architecture: (1) Hybrid Linear Attention combines frame-wise Gated DeltaNet (GDN) with softmax attention for memory-efficient long-context modeling. (2) Dual-Branch Camera Control ensures precise 6-DoF trajectory adherence. (3) Two-Stage Generation Pipeline applies a long-video refiner to stage-1 outputs, improving quality and consistency across sequences. (4) Robust Annotation Pipeline extracts accurate metric-scale 6-DoF camera poses from public videos to yield high-quality, spatiotemporally consistent action labels. Driven by these designs, SANA-WMdemonstrates remarkable efficiency across data, training compute, and inference hardware: it uses only $\sim$213K public video clips with metric-scale pose supervision, completes training in 15 days on 64 H100s, and generates each 60s clip on a single GPU; its distilled variant can be deployed on a single RTX 5090 with NVFP4 quantization to denoise a 60s 720p clip in 34s. On our one-minute world-model benchmark, SANA-WM demonstrates stronger action-following accuracy than prior open-source baselines and achieves comparable visual quality at $36\times$ higher throughput for scalable world modeling.
Nucleus-Image: Sparse MoE for Image Generation
Apr 14, 2026We present Nucleus-Image, a text-to-image generation model that establishes a new Pareto frontier in quality-versus-efficiency by matching or exceeding leading models on GenEval, DPG-Bench, and OneIG-Bench while activating only approximately 2B parameters per forward pass. Nucleus-Image employs a sparse mixture-of-experts (MoE) diffusion transformer architecture with Expert-Choice Routing that scales total model capacity to 17B parameters across 64 routed experts per layer. We adopt a streamlined architecture optimized for inference efficiency by excluding text tokens from the transformer backbone entirely and using joint attention that enables text KV sharing across timesteps. To improve routing stability when using timestep modulation, we introduce a decoupled routing design that separates timestep-aware expert assignment from timestep-conditioned expert computation. We construct a large-scale training corpus of 1.5B high-quality training pairs spanning 700M unique images through multi-stage filtering, deduplication, aesthetic tiering, and caption curation. Training follows a progressive resolution curriculum (256 to 512 to 1024) with multi-aspect-ratio bucketing at every stage, coupled with progressive sparsification of the expert capacity factor. We adopt the Muon optimizer and share our parameter grouping recipe tailored for diffusion models with timestep modulation. Nucleus-Image demonstrates that sparse MoE scaling is a highly effective path to high-quality image generation, reaching the performance of models with significantly larger active parameter budgets at a fraction of the inference cost. These results are achieved without post-training optimization of any kind: no reinforcement learning, no direct preference optimization, and no human preference tuning. We release the training recipe, making Nucleus-Image the first fully open-source MoE diffusion model at this quality.
Neural Computers
Apr 07, 2026We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
Can Video Diffusion Model Reconstruct 4D Geometry?
Mar 27, 2025Reconstructing dynamic 3D scenes (i.e., 4D geometry) from monocular video is an important yet challenging problem. Conventional multiview geometry-based approaches often struggle with dynamic motion, whereas recent learning-based methods either require specialized 4D representation or sophisticated optimization. In this paper, we present Sora3R, a novel framework that taps into the rich spatiotemporal priors of large-scale video diffusion models to directly infer 4D pointmaps from casual videos. Sora3R follows a two-stage pipeline: (1) we adapt a pointmap VAE from a pretrained video VAE, ensuring compatibility between the geometry and video latent spaces; (2) we finetune a diffusion backbone in combined video and pointmap latent space to generate coherent 4D pointmaps for every frame. Sora3R operates in a fully feedforward manner, requiring no external modules (e.g., depth, optical flow, or segmentation) or iterative global alignment. Extensive experiments demonstrate that Sora3R reliably recovers both camera poses and detailed scene geometry, achieving performance on par with state-of-the-art methods for dynamic 4D reconstruction across diverse scenarios.
Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation
Jan 29, 2025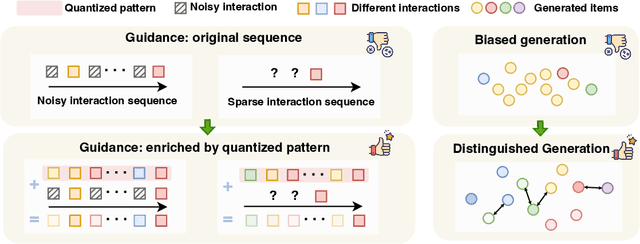
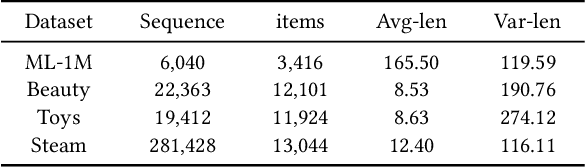
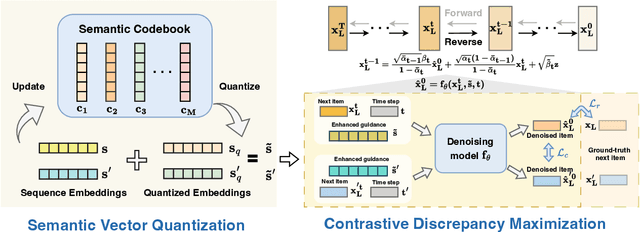
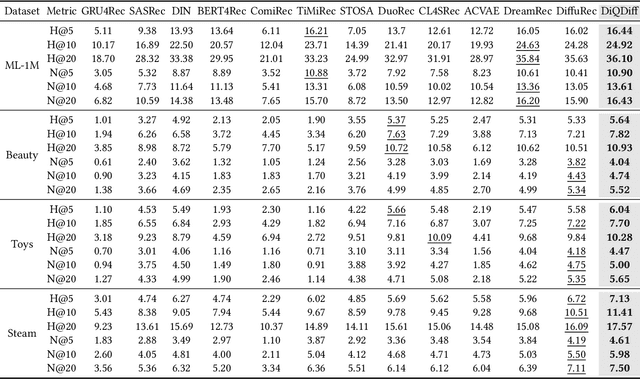
Diffusion models (DMs) have emerged as promising approaches for sequential recommendation due to their strong ability to model data distributions and generate high-quality items. Existing work typically adds noise to the next item and progressively denoises it guided by the user's interaction sequence, generating items that closely align with user interests. However, we identify two key issues in this paradigm. First, the sequences are often heterogeneous in length and content, exhibiting noise due to stochastic user behaviors. Using such sequences as guidance may hinder DMs from accurately understanding user interests. Second, DMs are prone to data bias and tend to generate only the popular items that dominate the training dataset, thus failing to meet the personalized needs of different users. To address these issues, we propose Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation (DiQDiff), which aims to extract robust guidance to understand user interests and generate distinguished items for personalized user interests within DMs. To extract robust guidance, DiQDiff introduces Semantic Vector Quantization (SVQ) to quantize sequences into semantic vectors (e.g., collaborative signals and category interests) using a codebook, which can enrich the guidance to better understand user interests. To generate distinguished items, DiQDiff personalizes the generation through Contrastive Discrepancy Maximization (CDM), which maximizes the distance between denoising trajectories using contrastive loss to prevent biased generation for different users. Extensive experiments are conducted to compare DiQDiff with multiple baseline models across four widely-used datasets. The superior recommendation performance of DiQDiff against leading approaches demonstrates its effectiveness in sequential recommendation tasks.
Learning Flow Fields in Attention for Controllable Person Image Generation
Dec 12, 2024
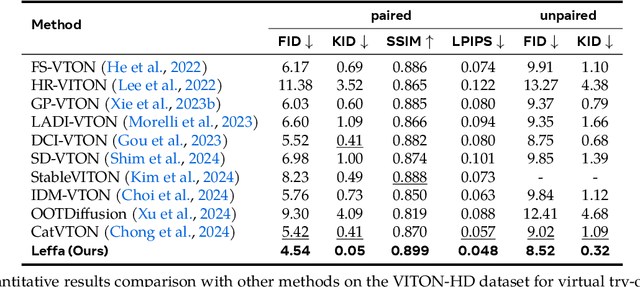
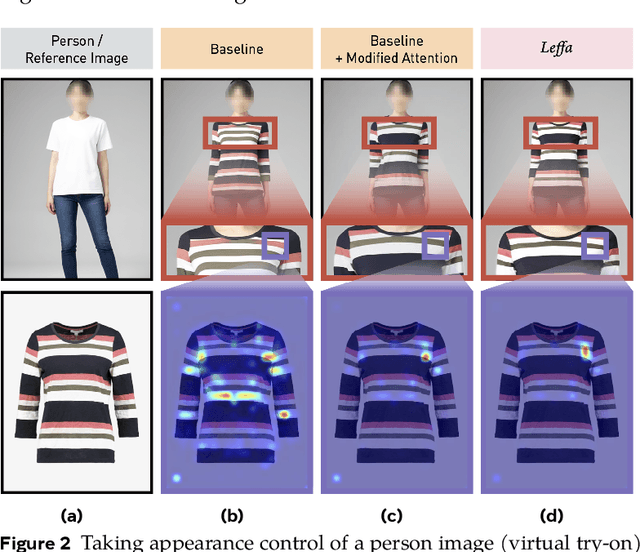
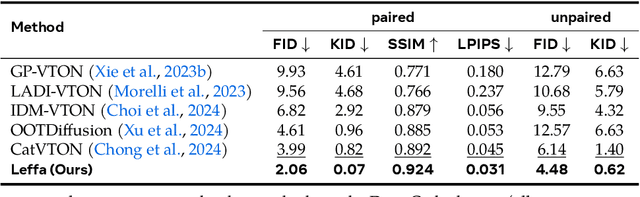
Controllable person image generation aims to generate a person image conditioned on reference images, allowing precise control over the person's appearance or pose. However, prior methods often distort fine-grained textural details from the reference image, despite achieving high overall image quality. We attribute these distortions to inadequate attention to corresponding regions in the reference image. To address this, we thereby propose learning flow fields in attention (Leffa), which explicitly guides the target query to attend to the correct reference key in the attention layer during training. Specifically, it is realized via a regularization loss on top of the attention map within a diffusion-based baseline. Our extensive experiments show that Leffa achieves state-of-the-art performance in controlling appearance (virtual try-on) and pose (pose transfer), significantly reducing fine-grained detail distortion while maintaining high image quality. Additionally, we show that our loss is model-agnostic and can be used to improve the performance of other diffusion models.
Adaptive Caching for Faster Video Generation with Diffusion Transformers
Nov 04, 2024



Generating temporally-consistent high-fidelity videos can be computationally expensive, especially over longer temporal spans. More-recent Diffusion Transformers (DiTs) -- despite making significant headway in this context -- have only heightened such challenges as they rely on larger models and heavier attention mechanisms, resulting in slower inference speeds. In this paper, we introduce a training-free method to accelerate video DiTs, termed Adaptive Caching (AdaCache), which is motivated by the fact that "not all videos are created equal": meaning, some videos require fewer denoising steps to attain a reasonable quality than others. Building on this, we not only cache computations through the diffusion process, but also devise a caching schedule tailored to each video generation, maximizing the quality-latency trade-off. We further introduce a Motion Regularization (MoReg) scheme to utilize video information within AdaCache, essentially controlling the compute allocation based on motion content. Altogether, our plug-and-play contributions grant significant inference speedups (e.g. up to 4.7x on Open-Sora 720p - 2s video generation) without sacrificing the generation quality, across multiple video DiT baselines.