 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemOCR: Layout-Aware Visual Memory for Efficient Long-Horizon Reasoning
Jan 29, 2026Long-horizon agentic reasoning necessitates effectively compressing growing interaction histories into a limited context window. Most existing memory systems serialize history as text, where token-level cost is uniform and scales linearly with length, often spending scarce budget on low-value details. To this end, we introduce MemOCR, a multimodal memory agent that improves long-horizon reasoning under tight context budgets by allocating memory space with adaptive information density through visual layout. Concretely, MemOCR maintains a structured rich-text memory (e.g., headings, highlights) and renders it into an image that the agent consults for memory access, visually prioritizing crucial evidence while aggressively compressing auxiliary details. To ensure robustness across varying memory budgets, we train MemOCR with reinforcement learning under budget-aware objectives that expose the agent to diverse compression levels. Across long-context multi-hop and single-hop question-answering benchmarks, MemOCR outperforms strong text-based baselines and achieves more effective context utilization under extreme budgets.
Addressing Missing Data Issue for Diffusion-based Recommendation
May 18, 2025Diffusion models have shown significant potential in generating oracle items that best match user preference with guidance from user historical interaction sequences. However, the quality of guidance is often compromised by unpredictable missing data in observed sequence, leading to suboptimal item generation. Since missing data is uncertain in both occurrence and content, recovering it is impractical and may introduce additional errors. To tackle this challenge, we propose a novel dual-side Thompson sampling-based Diffusion Model (TDM), which simulates extra missing data in the guidance signals and allows diffusion models to handle existing missing data through extrapolation. To preserve user preference evolution in sequences despite extra missing data, we introduce Dual-side Thompson Sampling to implement simulation with two probability models, sampling by exploiting user preference from both item continuity and sequence stability. TDM strategically removes items from sequences based on dual-side Thompson sampling and treats these edited sequences as guidance for diffusion models, enhancing models' robustness to missing data through consistency regularization. Additionally, to enhance the generation efficiency, TDM is implemented under the denoising diffusion implicit models to accelerate the reverse process. Extensive experiments and theoretical analysis validate the effectiveness of TDM in addressing missing data in sequential recommendations.
Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation
Jan 29, 2025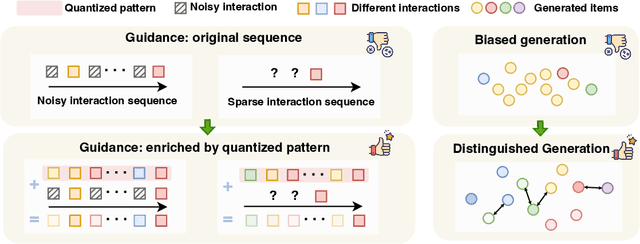
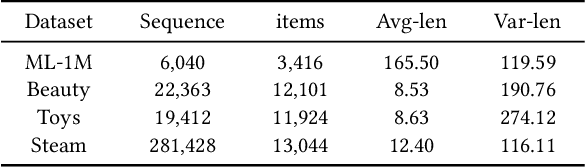
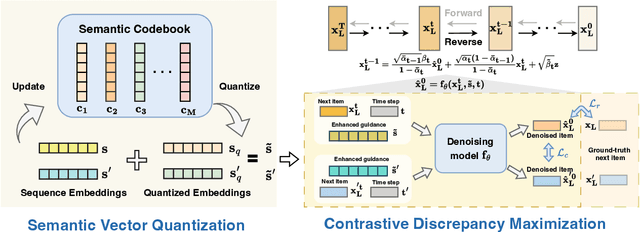
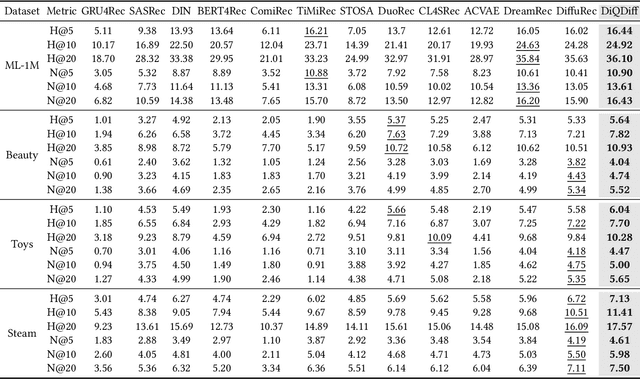
Diffusion models (DMs) have emerged as promising approaches for sequential recommendation due to their strong ability to model data distributions and generate high-quality items. Existing work typically adds noise to the next item and progressively denoises it guided by the user's interaction sequence, generating items that closely align with user interests. However, we identify two key issues in this paradigm. First, the sequences are often heterogeneous in length and content, exhibiting noise due to stochastic user behaviors. Using such sequences as guidance may hinder DMs from accurately understanding user interests. Second, DMs are prone to data bias and tend to generate only the popular items that dominate the training dataset, thus failing to meet the personalized needs of different users. To address these issues, we propose Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation (DiQDiff), which aims to extract robust guidance to understand user interests and generate distinguished items for personalized user interests within DMs. To extract robust guidance, DiQDiff introduces Semantic Vector Quantization (SVQ) to quantize sequences into semantic vectors (e.g., collaborative signals and category interests) using a codebook, which can enrich the guidance to better understand user interests. To generate distinguished items, DiQDiff personalizes the generation through Contrastive Discrepancy Maximization (CDM), which maximizes the distance between denoising trajectories using contrastive loss to prevent biased generation for different users. Extensive experiments are conducted to compare DiQDiff with multiple baseline models across four widely-used datasets. The superior recommendation performance of DiQDiff against leading approaches demonstrates its effectiveness in sequential recommendation tasks.
Invariant Graph Learning Meets Information Bottleneck for Out-of-Distribution Generalization
Aug 03, 2024Graph out-of-distribution (OOD) generalization remains a major challenge in graph learning since graph neural networks (GNNs) often suffer from severe performance degradation under distribution shifts. Invariant learning, aiming to extract invariant features across varied distributions, has recently emerged as a promising approach for OOD generation. Despite the great success of invariant learning in OOD problems for Euclidean data (i.e., images), the exploration within graph data remains constrained by the complex nature of graphs. Existing studies, such as data augmentation or causal intervention, either suffer from disruptions to invariance during the graph manipulation process or face reliability issues due to a lack of supervised signals for causal parts. In this work, we propose a novel framework, called Invariant Graph Learning based on Information bottleneck theory (InfoIGL), to extract the invariant features of graphs and enhance models' generalization ability to unseen distributions. Specifically, InfoIGL introduces a redundancy filter to compress task-irrelevant information related to environmental factors. Cooperating with our designed multi-level contrastive learning, we maximize the mutual information among graphs of the same class in the downstream classification tasks, preserving invariant features for prediction to a great extent. An appealing feature of InfoIGL is its strong generalization ability without depending on supervised signal of invariance. Experiments on both synthetic and real-world datasets demonstrate that our method achieves state-of-the-art performance under OOD generalization for graph classification tasks. The source code is available at https://github.com/maowenyu-11/InfoIGL.
Reinforced Prompt Personalization for Recommendation with Large Language Models
Jul 24, 2024Designing effective prompts can empower LLMs to understand user preferences and provide recommendations by leveraging LLMs' intent comprehension and knowledge utilization capabilities. However, existing research predominantly concentrates on task-wise prompting, developing fixed prompt templates composed of four patterns (i.e., role-playing, history records, reasoning guidance, and output format) and applying them to all users for a given task. Although convenient, task-wise prompting overlooks individual user differences, leading to potential mismatches in capturing user preferences. To address it, we introduce the concept of instance-wise prompting to personalize discrete prompts for individual users and propose Reinforced Prompt Personalization (RPP) to optimize the four patterns in prompts using multi-agent reinforcement learning (MARL). To boost efficiency, RPP formulates prompt personalization as selecting optimal sentences holistically across the four patterns, rather than optimizing word-by-word. To ensure the quality of prompts, RPP meticulously crafts diverse expressions for each of the four patterns, considering multiple analytical perspectives for specific recommendation tasks. In addition to RPP, our proposal of RPP+ aims to enhance the scalability of action space by dynamically refining actions with LLMs throughout the iterative process. We evaluate the effectiveness of RPP/RPP+ in ranking tasks over various datasets. Experimental results demonstrate the superiority of RPP/RPP+ over traditional recommender models, few-shot methods, and other prompt-based methods, underscoring the significance of instance-wise prompting for LLMs in recommendation tasks and validating the effectiveness of RPP/RPP+. Our code is available at https://github.com/maowenyu-11/RPP.
CheapNET: Improving Light-weight speech enhancement network by projected loss function
Nov 27, 2023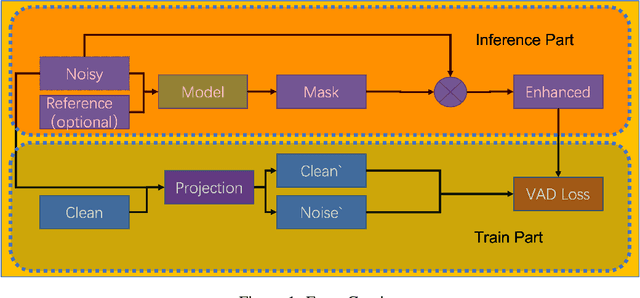
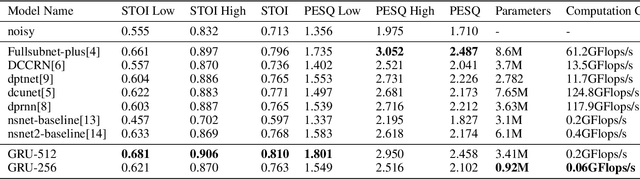
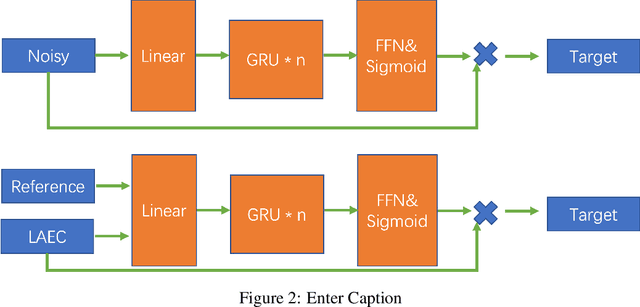
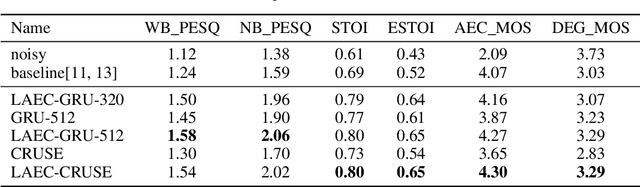
Noise suppression and echo cancellation are critical in speech enhancement and essential for smart devices and real-time communication. Deployed in voice processing front-ends and edge devices, these algorithms must ensure efficient real-time inference with low computational demands. Traditional edge-based noise suppression often uses MSE-based amplitude spectrum mask training, but this approach has limitations. We introduce a novel projection loss function, diverging from MSE, to enhance noise suppression. This method uses projection techniques to isolate key audio components from noise, significantly improving model performance. For echo cancellation, the function enables direct predictions on LAEC pre-processed outputs, substantially enhancing performance. Our noise suppression model achieves near state-of-the-art results with only 3.1M parameters and 0.4GFlops/s computational load. Moreover, our echo cancellation model outperforms replicated industry-leading models, introducing a new perspective in speech enhancement.
ACQ: Improving Generative Data-free Quantization Via Attention Correction
Jan 18, 2023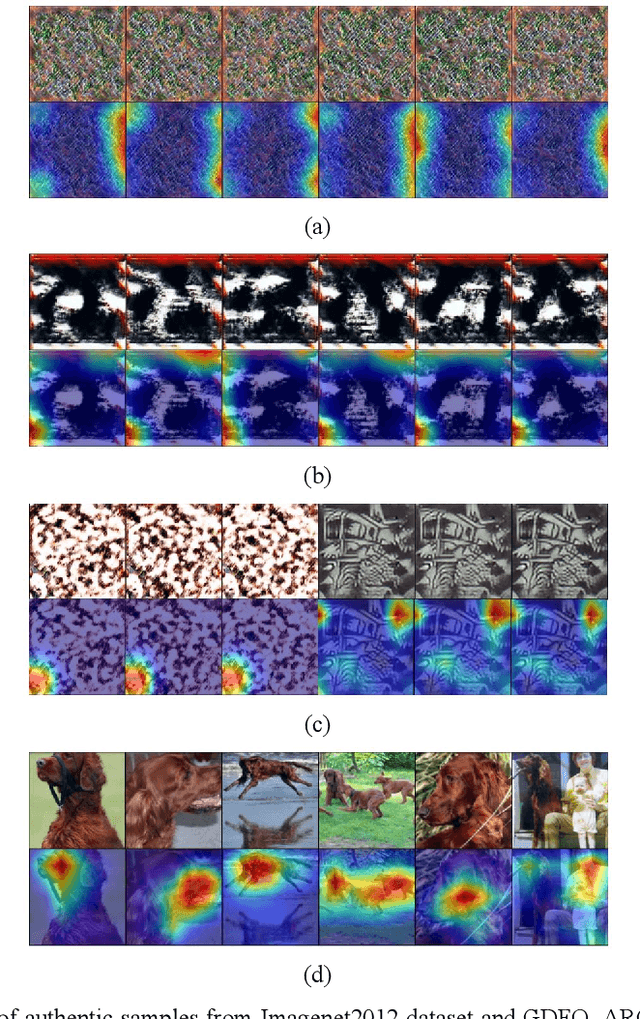

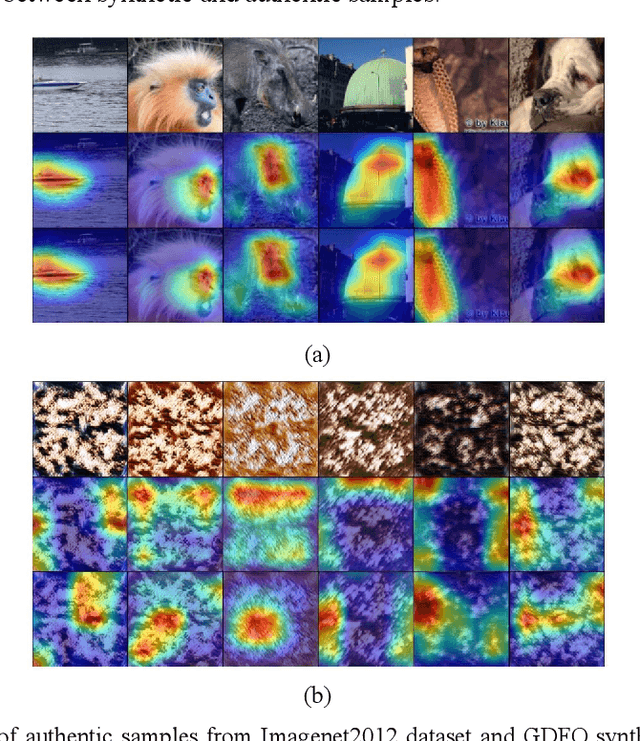
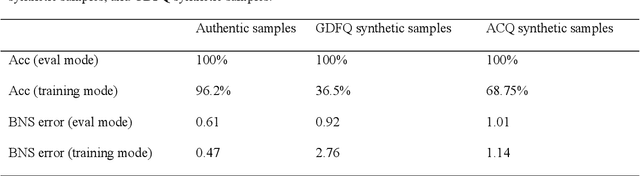
Data-free quantization aims to achieve model quantization without accessing any authentic sample. It is significant in an application-oriented context involving data privacy. Converting noise vectors into synthetic samples through a generator is a popular data-free quantization method, which is called generative data-free quantization. However, there is a difference in attention between synthetic samples and authentic samples. This is always ignored and restricts the quantization performance. First, since synthetic samples of the same class are prone to have homogenous attention, the quantized network can only learn limited modes of attention. Second, synthetic samples in eval mode and training mode exhibit different attention. Hence, the batch-normalization statistics matching tends to be inaccurate. ACQ is proposed in this paper to fix the attention of synthetic samples. An attention center position-condition generator is established regarding the homogenization of intra-class attention. Restricted by the attention center matching loss, the attention center position is treated as the generator's condition input to guide synthetic samples in obtaining diverse attention. Moreover, we design adversarial loss of paired synthetic samples under the same condition to prevent the generator from paying overmuch attention to the condition, which may result in mode collapse. To improve the attention similarity of synthetic samples in different network modes, we introduce a consistency penalty to guarantee accurate BN statistics matching. The experimental results demonstrate that ACQ effectively improves the attention problems of synthetic samples. Under various training settings, ACQ achieves the best quantization performance. For the 4-bit quantization of Resnet18 and Resnet50, ACQ reaches 67.55% and 72.23% accuracy, respectively.