 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlayaLaser: Efficient Index Layout and Search Strategy for Large-scale High-dimensional Vector Similarity Search
Feb 26, 2026On-disk graph-based approximate nearest neighbor search (ANNS) is essential for large-scale, high-dimensional vector retrieval, yet its performance is widely recognized to be limited by the prohibitive I/O costs. Interestingly, we observed that the performance of on-disk graph-based index systems is compute-bound, not I/O-bound, with the rising of the vector data dimensionality (e.g., hundreds or thousands). This insight uncovers a significant optimization opportunity: existing on-disk graph-based index systems universally target I/O reduction and largely overlook computational overhead, which leaves a substantial performance improvement space. In this work, we propose AlayaLaser, an efficient on-disk graph-based index system for large-scale high-dimensional vector similarity search. In particular, we first conduct performance analysis on existing on-disk graph-based index systems via the adapted roofline model, then we devise a novel on-disk data layout in AlayaLaser to effectively alleviate the compute-bound, which is revealed by the above roofline model analysis, by exploiting SIMD instructions on modern CPUs. We next design a suite of optimization techniques (e.g., degree-based node cache, cluster-based entry point selection, and early dispatch strategy) to further improve the performance of AlayaLaser. We last conduct extensive experimental studies on a wide range of large-scale high-dimensional vector datasets to verify the superiority of AlayaLaser. Specifically, AlayaLaser not only surpasses existing on-disk graph-based index systems but also matches or even exceeds the performance of in-memory index systems.
Unleashing the True Potential of LLMs: A Feedback-Triggered Self-Correction with Long-Term Multipath Decoding
Sep 09, 2025

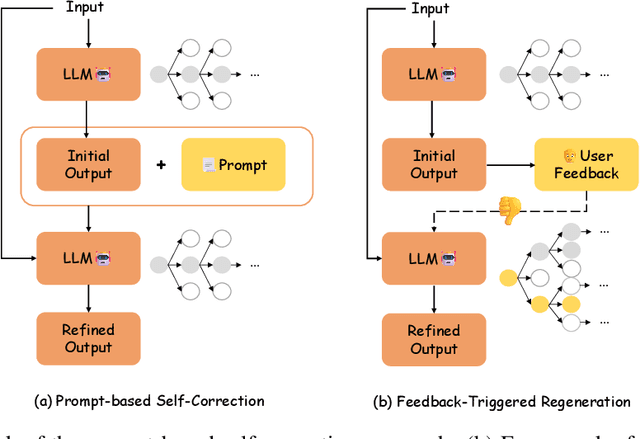

Large Language Models (LLMs) have achieved remarkable performance across diverse tasks, yet their susceptibility to generating incorrect content during inference remains a critical unsolved challenge. While self-correction methods offer potential solutions, their effectiveness is hindered by two inherent limitations: (1) the absence of reliable guidance signals for error localization, and (2) the restricted reasoning depth imposed by conventional next-token decoding paradigms. To address these issues, we propose Feedback-Triggered Regeneration (FTR), a novel framework that synergizes user feedback with enhanced decoding dynamics. Specifically, FTR activates response regeneration only upon receiving negative user feedback, thereby circumventing error propagation from faulty self-assessment while preserving originally correct outputs. Furthermore, we introduce Long-Term Multipath (LTM) decoding, which enables systematic exploration of multiple reasoning trajectories through delayed sequence evaluation, effectively overcoming the myopic decision-making characteristic of standard next-token prediction. Extensive experiments on mathematical reasoning and code generation benchmarks demonstrate that our framework achieves consistent and significant improvements over state-of-the-art prompt-based self-correction methods.
GARAD-SLAM: 3D GAussian splatting for Real-time Anti Dynamic SLAM
Feb 05, 2025



The 3D Gaussian Splatting (3DGS)-based SLAM system has garnered widespread attention due to its excellent performance in real-time high-fidelity rendering. However, in real-world environments with dynamic objects, existing 3DGS-based SLAM systems often face mapping errors and tracking drift issues. To address these problems, we propose GARAD-SLAM, a real-time 3DGS-based SLAM system tailored for dynamic scenes. In terms of tracking, unlike traditional methods, we directly perform dynamic segmentation on Gaussians and map them back to the front-end to obtain dynamic point labels through a Gaussian pyramid network, achieving precise dynamic removal and robust tracking. For mapping, we impose rendering penalties on dynamically labeled Gaussians, which are updated through the network, to avoid irreversible erroneous removal caused by simple pruning. Our results on real-world datasets demonstrate that our method is competitive in tracking compared to baseline methods, generating fewer artifacts and higher-quality reconstructions in rendering.
Reinforced Prompt Personalization for Recommendation with Large Language Models
Jul 24, 2024

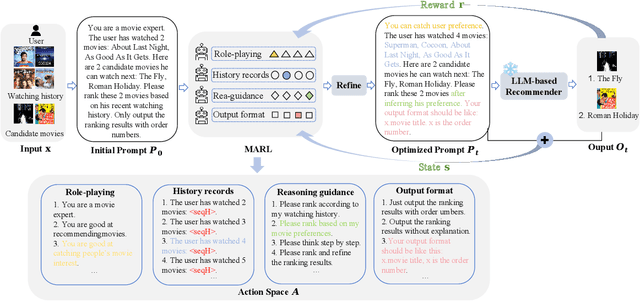

Designing effective prompts can empower LLMs to understand user preferences and provide recommendations by leveraging LLMs' intent comprehension and knowledge utilization capabilities. However, existing research predominantly concentrates on task-wise prompting, developing fixed prompt templates composed of four patterns (i.e., role-playing, history records, reasoning guidance, and output format) and applying them to all users for a given task. Although convenient, task-wise prompting overlooks individual user differences, leading to potential mismatches in capturing user preferences. To address it, we introduce the concept of instance-wise prompting to personalize discrete prompts for individual users and propose Reinforced Prompt Personalization (RPP) to optimize the four patterns in prompts using multi-agent reinforcement learning (MARL). To boost efficiency, RPP formulates prompt personalization as selecting optimal sentences holistically across the four patterns, rather than optimizing word-by-word. To ensure the quality of prompts, RPP meticulously crafts diverse expressions for each of the four patterns, considering multiple analytical perspectives for specific recommendation tasks. In addition to RPP, our proposal of RPP+ aims to enhance the scalability of action space by dynamically refining actions with LLMs throughout the iterative process. We evaluate the effectiveness of RPP/RPP+ in ranking tasks over various datasets. Experimental results demonstrate the superiority of RPP/RPP+ over traditional recommender models, few-shot methods, and other prompt-based methods, underscoring the significance of instance-wise prompting for LLMs in recommendation tasks and validating the effectiveness of RPP/RPP+. Our code is available at https://github.com/maowenyu-11/RPP.
RIS-aided MIMO Beamforming: Piece-Wise Near-field Channel Model
Jun 21, 2024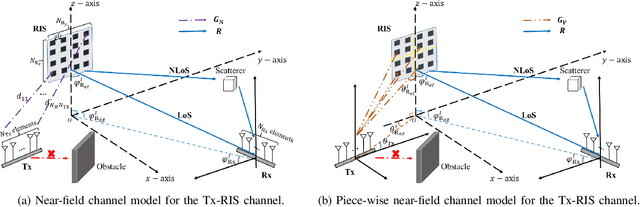
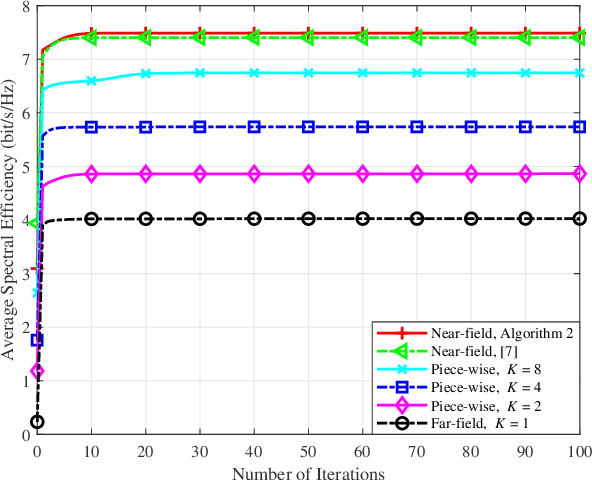
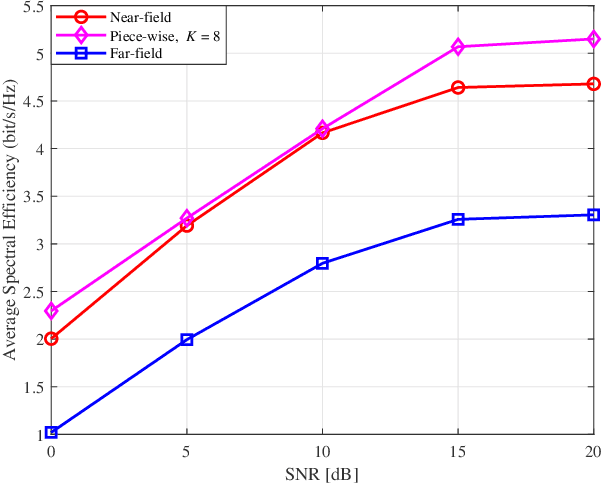
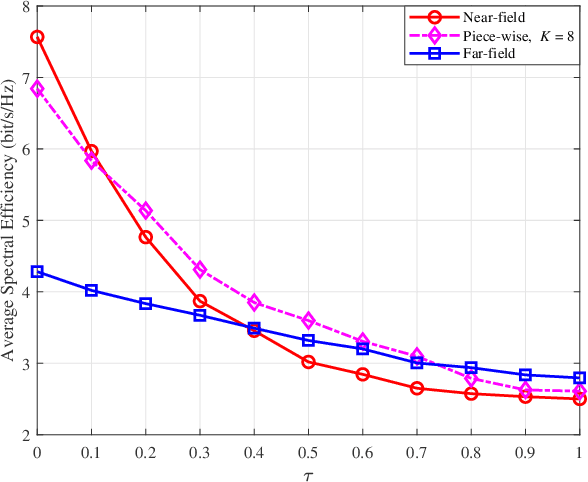
This paper proposes a joint active and passive beamforming design for reconfigurable intelligent surface (RIS)-aided wireless communication systems, adopting a piece-wise near-field channel model. While a traditional near-field channel model, applied without any approximations, offers higher modeling accuracy than a far-field model, it renders the system design more sensitive to channel estimation errors (CEEs). As a remedy, we propose to adopt a piece-wise near-field channel model that leverages the advantages of the near-field approach while enhancing its robustness against CEEs. Our study analyzes the impact of different channel models, including the traditional near-field, the proposed piece-wise near-field and far-field channel models, on the interference distribution caused by CEEs and model mismatches. Subsequently, by treating the interference as noise, we formulate a joint active and passive beamforming design problem to maximize the spectral efficiency (SE). The formulated problem is then recast as a mean squared error (MSE) minimization problem and a suboptimal algorithm is developed to iteratively update the active and passive beamforming strategies. Simulation results demonstrate that adopting the piece-wise near-field channel model leads to an improved SE compared to both the near-field and far-field models in the presence of CEEs. Furthermore, the proposed piece-wise near-field model achieves a good trade-off between modeling accuracy and system's degrees of freedom (DoF).
Optimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024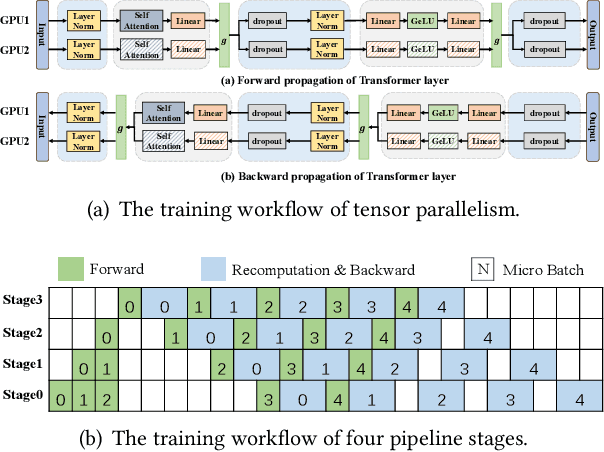
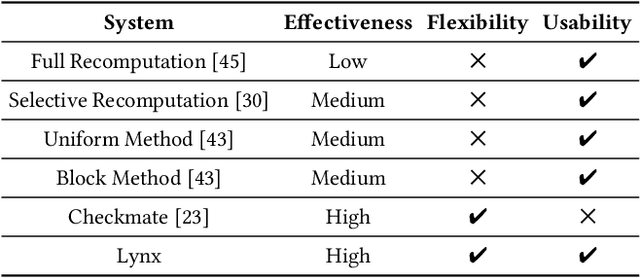
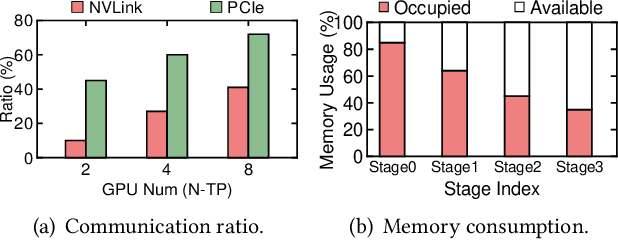
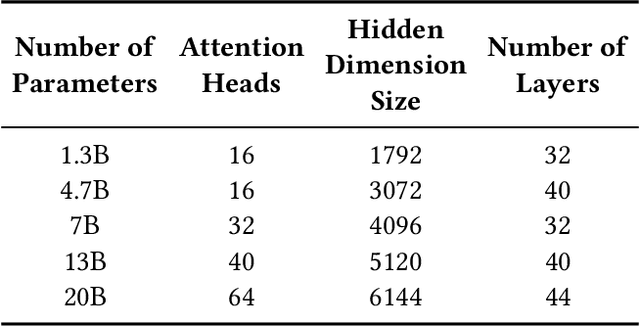
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.
Explainable Sparse Knowledge Graph Completion via High-order Graph Reasoning Network
Jul 14, 2022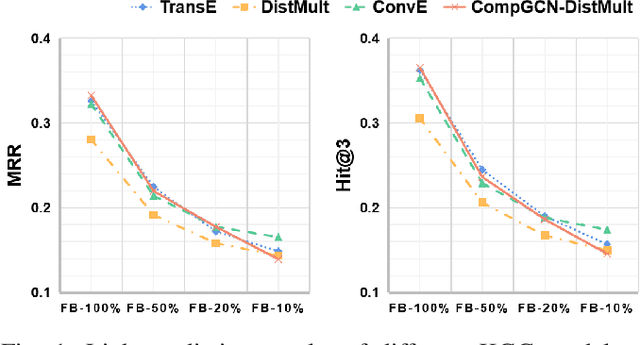
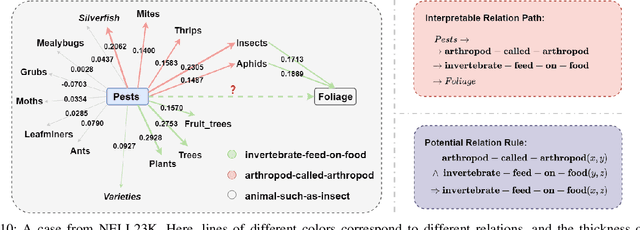
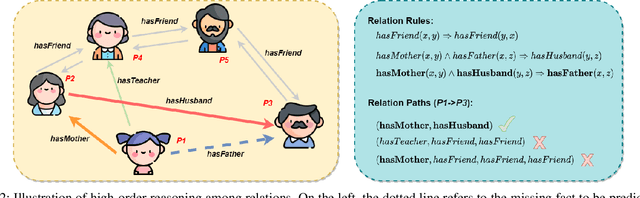
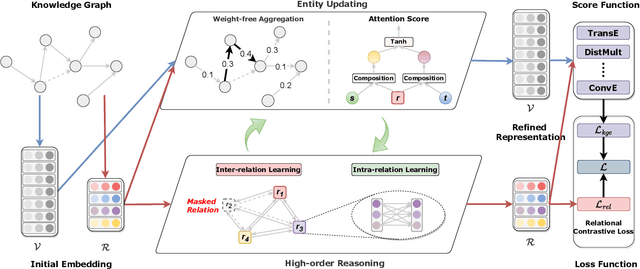
Knowledge Graphs (KGs) are becoming increasingly essential infrastructures in many applications while suffering from incompleteness issues. The KG completion task (KGC) automatically predicts missing facts based on an incomplete KG. However, existing methods perform unsatisfactorily in real-world scenarios. On the one hand, their performance will dramatically degrade along with the increasing sparsity of KGs. On the other hand, the inference procedure for prediction is an untrustworthy black box. This paper proposes a novel explainable model for sparse KGC, compositing high-order reasoning into a graph convolutional network, namely HoGRN. It can not only improve the generalization ability to mitigate the information insufficiency issue but also provide interpretability while maintaining the model's effectiveness and efficiency. There are two main components that are seamlessly integrated for joint optimization. First, the high-order reasoning component learns high-quality relation representations by capturing endogenous correlation among relations. This can reflect logical rules to justify a broader of missing facts. Second, the entity updating component leverages a weight-free Graph Convolutional Network (GCN) to efficiently model KG structures with interpretability. Unlike conventional methods, we conduct entity aggregation and design composition-based attention in the relational space without additional parameters. The lightweight design makes HoGRN better suitable for sparse settings. For evaluation, we have conducted extensive experiments-the results of HoGRN on several sparse KGs present impressive improvements (9% MRR gain on average). Further ablation and case studies demonstrate the effectiveness of the main components. Our codes will be released upon acceptance.
Structure-Enhanced Meta-Learning For Few-Shot Graph Classification
Mar 11, 2021

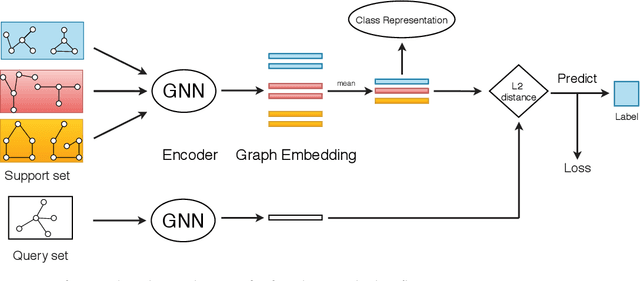
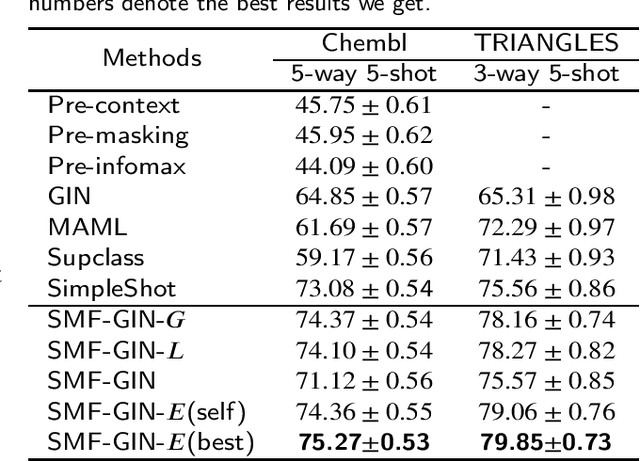
Graph classification is a highly impactful task that plays a crucial role in a myriad of real-world applications such as molecular property prediction and protein function prediction. Aiming to handle the new classes with limited labeled graphs, few-shot graph classification has become a bridge of existing graph classification solutions and practical usage. This work explores the potential of metric-based meta-learning for solving few-shot graph classification. We highlight the importance of considering structural characteristics in the solution and propose a novel framework which explicitly considers global structure and local structure of the input graph. An implementation upon GIN, named SMFGIN, is tested on two datasets, Chembl and TRIANGLES, where extensive experiments validate the effectiveness of the proposed method. The Chembl is constructed to fill in the gap of lacking largescale benchmark for few-shot graph classification evaluation, which will be released together with the implementation of SMF-GIN upon acceptance
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 17, 2020
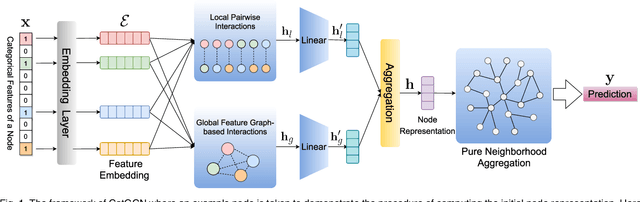
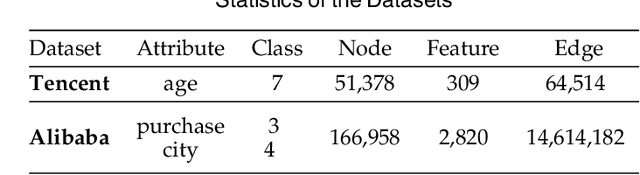
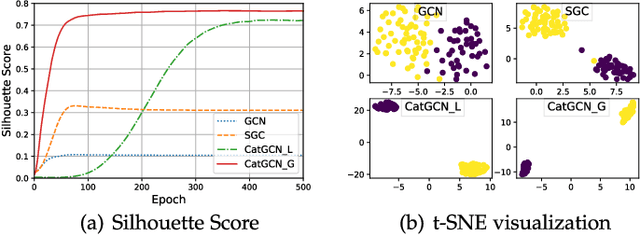
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
Graph Convolution Machine for Context-aware Recommender System
Jan 30, 2020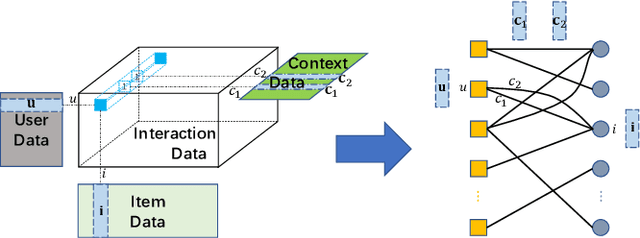
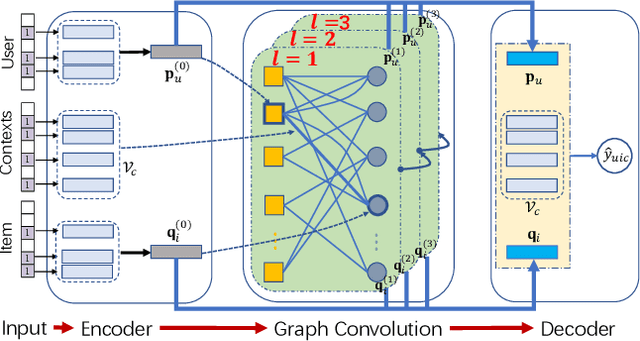
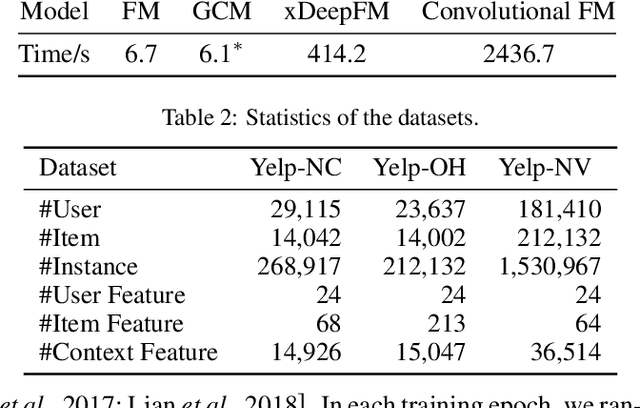

The latest advance in recommendation shows that better user and item representations can be learned via performing graph convolutions on the user-item interaction graph. However, such finding is mostly restricted to the collaborative filtering (CF) scenario, where the interaction contexts are not available. In this work, we extend the advantages of graph convolutions to context-aware recommender system (CARS, which represents a generic type of models that can handle various side information). We propose Graph Convolution Machine (GCM), an end-to-end framework that consists of three components: an encoder, graph convolution (GC) layers, and a decoder. The encoder projects users, items, and contexts into embedding vectors, which are passed to the GC layers that refine user and item embeddings with context-aware graph convolutions on user-item graph. The decoder digests the refined embeddings to output the prediction score by considering the interactions among user, item, and context embeddings. We conduct experiments on three real-world datasets from Yelp, validating the effectiveness of GCM and the benefits of performing graph convolutions for CARS.