 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024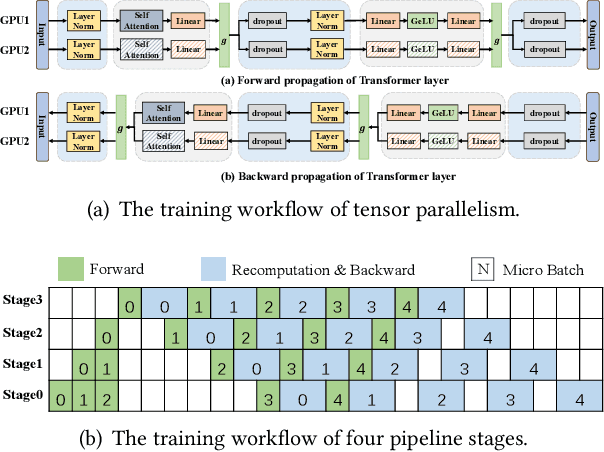
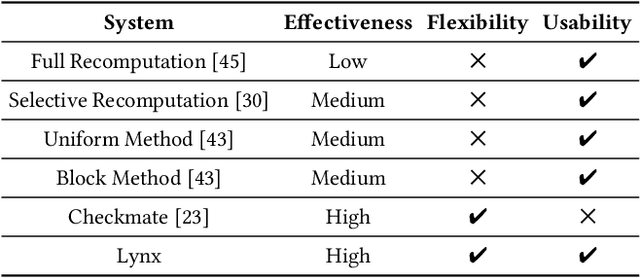
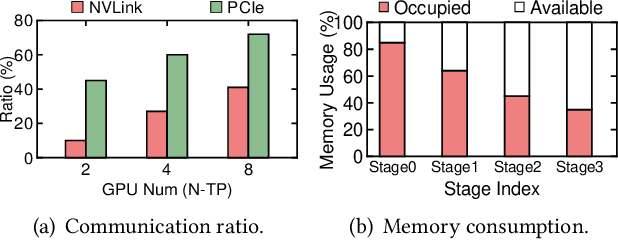
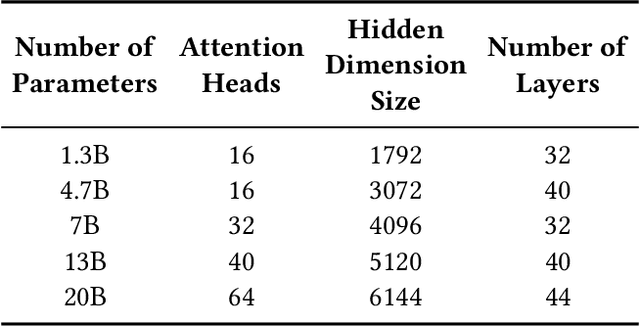
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.