 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdacc: Adaptive Compression and Activation Checkpointing for LLM Memory Management
Aug 01, 2025Training large language models often employs recomputation to alleviate memory pressure, which can introduce up to 30% overhead in real-world scenarios. In this paper, we propose Adacc, a novel memory management framework that combines adaptive compression and activation checkpointing to reduce the GPU memory footprint. It comprises three modules: (1) We design layer-specific compression algorithms that account for outliers in LLM tensors, instead of directly quantizing floats from FP16 to INT4, to ensure model accuracy. (2) We propose an optimal scheduling policy that employs MILP to determine the best memory optimization for each tensor. (3) To accommodate changes in training tensors, we introduce an adaptive policy evolution mechanism that adjusts the policy during training to enhance throughput. Experimental results show that Adacc can accelerate the LLM training by 1.01x to 1.37x compared to state-of-the-art frameworks, while maintaining comparable model accuracy to the Baseline.
Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025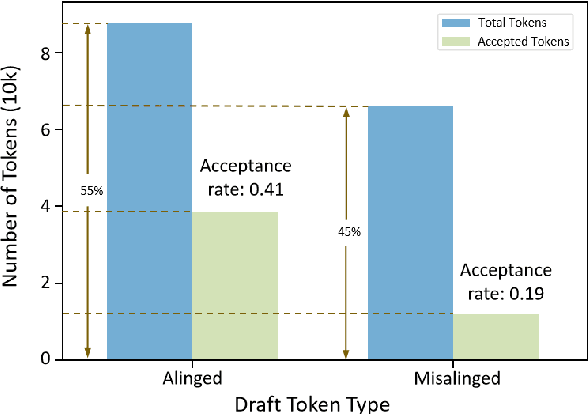
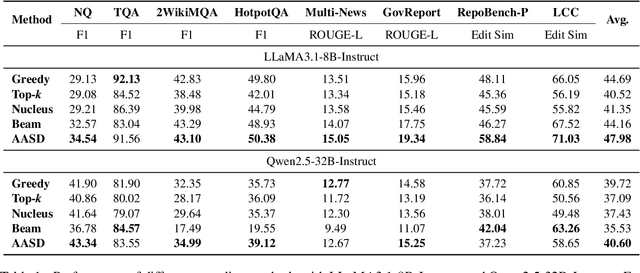
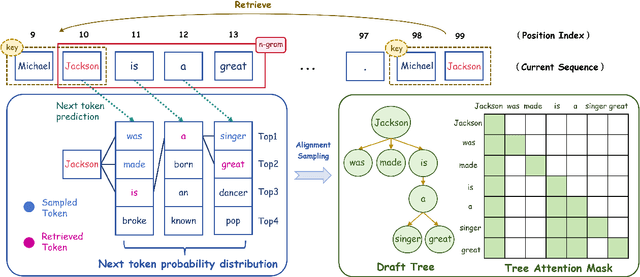
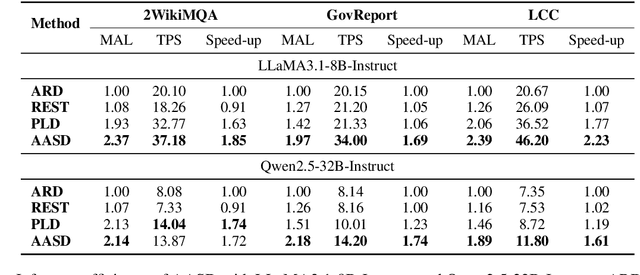
Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.
Accurate KV Cache Quantization with Outlier Tokens Tracing
May 16, 2025The impressive capabilities of Large Language Models (LLMs) come at the cost of substantial computational resources during deployment. While KV Cache can significantly reduce recomputation during inference, it also introduces additional memory overhead. KV Cache quantization presents a promising solution, striking a good balance between memory usage and accuracy. Previous research has shown that the Keys are distributed by channel, while the Values are distributed by token. Consequently, the common practice is to apply channel-wise quantization to the Keys and token-wise quantization to the Values. However, our further investigation reveals that a small subset of unusual tokens exhibit unique characteristics that deviate from this pattern, which can substantially impact quantization accuracy. To address this, we develop a simple yet effective method to identify these tokens accurately during the decoding process and exclude them from quantization as outlier tokens, significantly improving overall accuracy. Extensive experiments show that our method achieves significant accuracy improvements under 2-bit quantization and can deliver a 6.4 times reduction in memory usage and a 2.3 times increase in throughput.
Taming the Titans: A Survey of Efficient LLM Inference Serving
Apr 28, 2025Large Language Models (LLMs) for Generative AI have achieved remarkable progress, evolving into sophisticated and versatile tools widely adopted across various domains and applications. However, the substantial memory overhead caused by their vast number of parameters, combined with the high computational demands of the attention mechanism, poses significant challenges in achieving low latency and high throughput for LLM inference services. Recent advancements, driven by groundbreaking research, have significantly accelerated progress in this field. This paper provides a comprehensive survey of these methods, covering fundamental instance-level approaches, in-depth cluster-level strategies, emerging scenario directions, and other miscellaneous but important areas. At the instance level, we review model placement, request scheduling, decoding length prediction, storage management, and the disaggregation paradigm. At the cluster level, we explore GPU cluster deployment, multi-instance load balancing, and cloud service solutions. For emerging scenarios, we organize the discussion around specific tasks, modules, and auxiliary methods. To ensure a holistic overview, we also highlight several niche yet critical areas. Finally, we outline potential research directions to further advance the field of LLM inference serving.
FASP: Fast and Accurate Structured Pruning of Large Language Models
Jan 16, 2025



The rapid increase in the size of large language models (LLMs) has significantly escalated their computational and memory demands, posing challenges for efficient deployment, especially on resource-constrained devices. Structured pruning has emerged as an effective model compression method that can reduce these demands while preserving performance. In this paper, we introduce FASP (Fast and Accurate Structured Pruning), a novel structured pruning framework for LLMs that emphasizes both speed and accuracy. FASP employs a distinctive pruning structure that interlinks sequential layers, allowing for the removal of columns in one layer while simultaneously eliminating corresponding rows in the preceding layer without incurring additional performance loss. The pruning metric, inspired by Wanda, is computationally efficient and effectively selects components to prune. Additionally, we propose a restoration mechanism that enhances model fidelity by adjusting the remaining weights post-pruning. We evaluate FASP on the OPT and LLaMA model families, demonstrating superior performance in terms of perplexity and accuracy on downstream tasks compared to state-of-the-art methods. Our approach achieves significant speed-ups, pruning models such as OPT-125M in 17 seconds and LLaMA-30B in 15 minutes on a single NVIDIA RTX 4090 GPU, making it a highly practical solution for optimizing LLMs.
Beware of Calibration Data for Pruning Large Language Models
Oct 23, 2024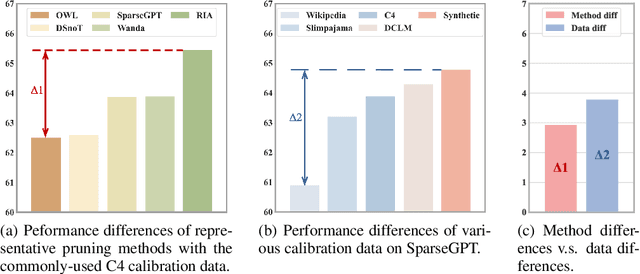

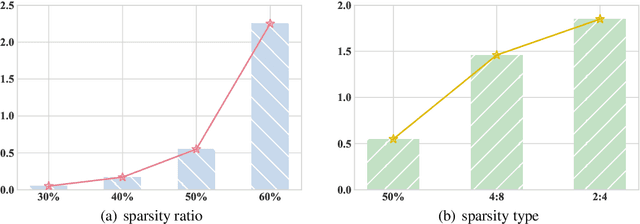

As large language models (LLMs) are widely applied across various fields, model compression has become increasingly crucial for reducing costs and improving inference efficiency. Post-training pruning is a promising method that does not require resource-intensive iterative training and only needs a small amount of calibration data to assess the importance of parameters. Previous research has primarily focused on designing advanced pruning methods, while different calibration data's impact on pruning performance still lacks systematical exploration. We fill this blank and surprisingly observe that the effects of calibration data even value more than designing advanced pruning strategies, especially for high sparsity. Our preliminary exploration also discloses that using calibration data similar to the training data can yield better performance. As pre-training data is usually inaccessible for advanced LLMs, we further provide a self-generating calibration data synthesis strategy to construct feasible calibration data. We conduct experiments on the recent strong open-source LLMs (e.g., DCLM, and LLaMA-3), and the results show that the proposed method outperforms commonly used calibration data and can effectively enhance strong pruning methods (e.g., Wanda, OWL).
A Convex-optimization-based Layer-wise Post-training Pruner for Large Language Models
Aug 07, 2024



Pruning is a critical strategy for compressing trained large language models (LLMs), aiming at substantial memory conservation and computational acceleration without compromising performance. However, existing pruning methods often necessitate inefficient retraining for billion-scale LLMs or rely on heuristic methods such as the optimal brain surgeon framework, which degrade performance. In this paper, we introduce FISTAPruner, the first post-training pruner based on convex optimization models and algorithms. Specifically, we propose a convex optimization model incorporating $\ell_1$ norm to induce sparsity and utilize the FISTA solver for optimization. FISTAPruner incorporates an intra-layer cumulative error correction mechanism and supports parallel pruning. We comprehensively evaluate FISTAPruner on models such as OPT, LLaMA, LLaMA-2, and LLaMA-3 with 125M to 70B parameters under unstructured and 2:4 semi-structured sparsity, demonstrating superior performance over existing state-of-the-art methods across various language benchmarks.
MSceneSpeech: A Multi-Scene Speech Dataset For Expressive Speech Synthesis
Jul 19, 2024



We introduce an open source high-quality Mandarin TTS dataset MSceneSpeech (Multiple Scene Speech Dataset), which is intended to provide resources for expressive speech synthesis. MSceneSpeech comprises numerous audio recordings and texts performed and recorded according to daily life scenarios. Each scenario includes multiple speakers and a diverse range of prosodic styles, making it suitable for speech synthesis that entails multi-speaker style and prosody modeling. We have established a robust baseline, through the prompting mechanism, that can effectively synthesize speech characterized by both user-specific timbre and scene-specific prosody with arbitrary text input. The open source MSceneSpeech Dataset and audio samples of our baseline are available at https://speechai-demo.github.io/MSceneSpeech/.
OPT-Tree: Speculative Decoding with Adaptive Draft Tree Structure
Jun 25, 2024



Autoregressive language models demonstrate excellent performance in various scenarios. However, the inference efficiency is limited by its one-step-one-word generation mode, which has become a pressing problem recently as the models become increasingly larger. Speculative decoding employs a "draft and then verify" mechanism to allow multiple tokens to be generated in one step, realizing lossless acceleration. Existing methods mainly adopt fixed heuristic draft structures, which fail to adapt to different situations to maximize the acceptance length during verification. To alleviate this dilemma, we proposed OPT-Tree, an algorithm to construct adaptive and scalable draft trees. It searches the optimal tree structure that maximizes the mathematical expectation of the acceptance length in each decoding step. Experimental results reveal that OPT-Tree outperforms the existing draft structures and achieves a speed-up ratio of up to 3.2 compared with autoregressive decoding. If the draft model is powerful enough and the node budget is sufficient, it can generate more than ten tokens in a single step. Our code is available at https://github.com/Jikai0Wang/OPT-Tree.
Optimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024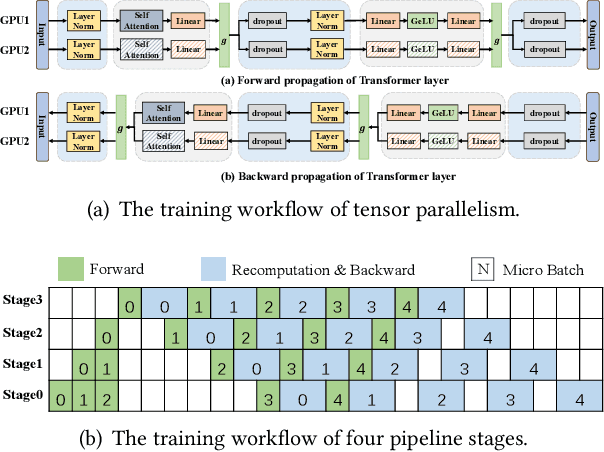
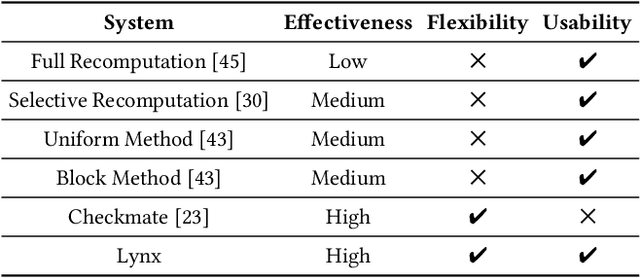
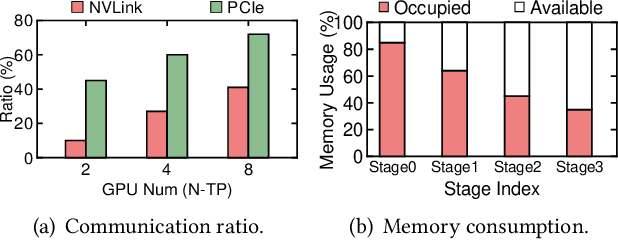
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.