 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeware of Calibration Data for Pruning Large Language Models
Paper and Code
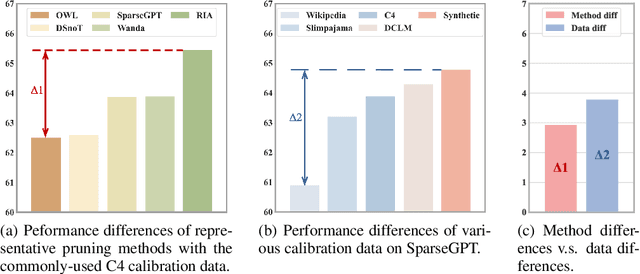

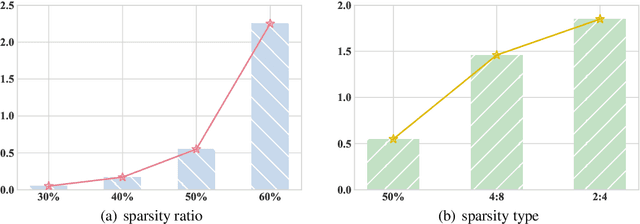

As large language models (LLMs) are widely applied across various fields, model compression has become increasingly crucial for reducing costs and improving inference efficiency. Post-training pruning is a promising method that does not require resource-intensive iterative training and only needs a small amount of calibration data to assess the importance of parameters. Previous research has primarily focused on designing advanced pruning methods, while different calibration data's impact on pruning performance still lacks systematical exploration. We fill this blank and surprisingly observe that the effects of calibration data even value more than designing advanced pruning strategies, especially for high sparsity. Our preliminary exploration also discloses that using calibration data similar to the training data can yield better performance. As pre-training data is usually inaccessible for advanced LLMs, we further provide a self-generating calibration data synthesis strategy to construct feasible calibration data. We conduct experiments on the recent strong open-source LLMs (e.g., DCLM, and LLaMA-3), and the results show that the proposed method outperforms commonly used calibration data and can effectively enhance strong pruning methods (e.g., Wanda, OWL).