 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025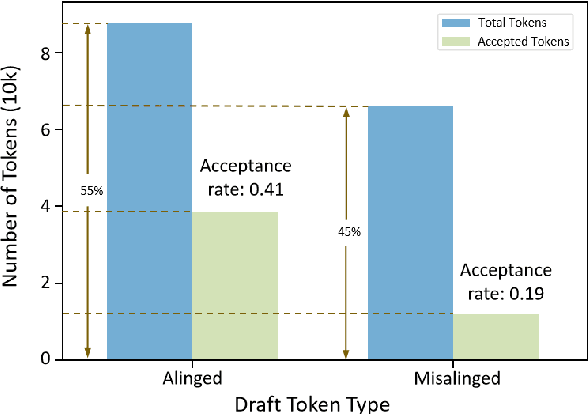
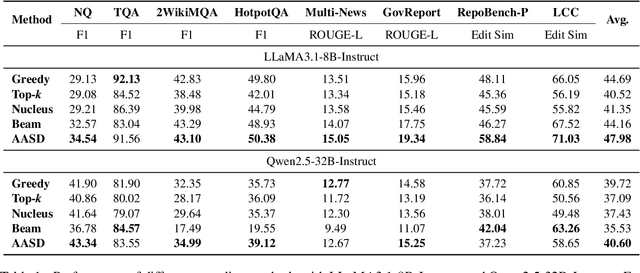
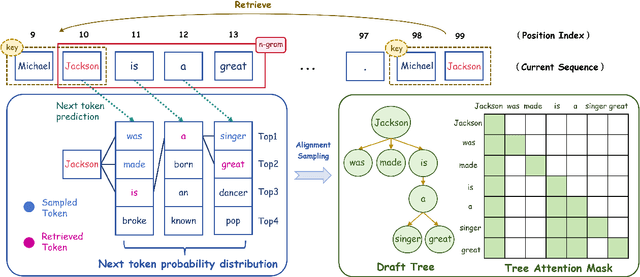
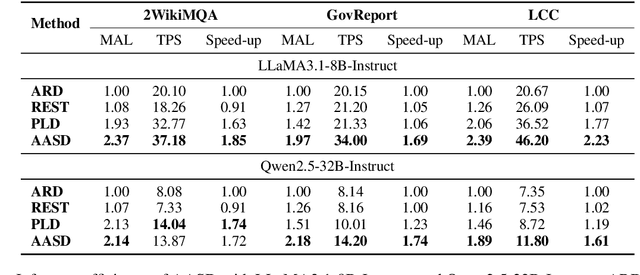
Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.
Accurate KV Cache Quantization with Outlier Tokens Tracing
May 16, 2025The impressive capabilities of Large Language Models (LLMs) come at the cost of substantial computational resources during deployment. While KV Cache can significantly reduce recomputation during inference, it also introduces additional memory overhead. KV Cache quantization presents a promising solution, striking a good balance between memory usage and accuracy. Previous research has shown that the Keys are distributed by channel, while the Values are distributed by token. Consequently, the common practice is to apply channel-wise quantization to the Keys and token-wise quantization to the Values. However, our further investigation reveals that a small subset of unusual tokens exhibit unique characteristics that deviate from this pattern, which can substantially impact quantization accuracy. To address this, we develop a simple yet effective method to identify these tokens accurately during the decoding process and exclude them from quantization as outlier tokens, significantly improving overall accuracy. Extensive experiments show that our method achieves significant accuracy improvements under 2-bit quantization and can deliver a 6.4 times reduction in memory usage and a 2.3 times increase in throughput.
Taming the Titans: A Survey of Efficient LLM Inference Serving
Apr 28, 2025Large Language Models (LLMs) for Generative AI have achieved remarkable progress, evolving into sophisticated and versatile tools widely adopted across various domains and applications. However, the substantial memory overhead caused by their vast number of parameters, combined with the high computational demands of the attention mechanism, poses significant challenges in achieving low latency and high throughput for LLM inference services. Recent advancements, driven by groundbreaking research, have significantly accelerated progress in this field. This paper provides a comprehensive survey of these methods, covering fundamental instance-level approaches, in-depth cluster-level strategies, emerging scenario directions, and other miscellaneous but important areas. At the instance level, we review model placement, request scheduling, decoding length prediction, storage management, and the disaggregation paradigm. At the cluster level, we explore GPU cluster deployment, multi-instance load balancing, and cloud service solutions. For emerging scenarios, we organize the discussion around specific tasks, modules, and auxiliary methods. To ensure a holistic overview, we also highlight several niche yet critical areas. Finally, we outline potential research directions to further advance the field of LLM inference serving.
Beware of Calibration Data for Pruning Large Language Models
Oct 23, 2024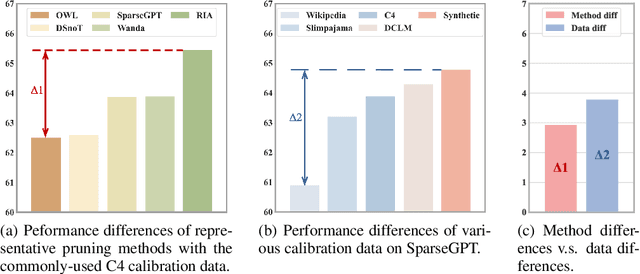

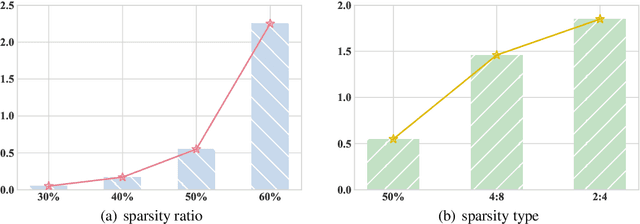

As large language models (LLMs) are widely applied across various fields, model compression has become increasingly crucial for reducing costs and improving inference efficiency. Post-training pruning is a promising method that does not require resource-intensive iterative training and only needs a small amount of calibration data to assess the importance of parameters. Previous research has primarily focused on designing advanced pruning methods, while different calibration data's impact on pruning performance still lacks systematical exploration. We fill this blank and surprisingly observe that the effects of calibration data even value more than designing advanced pruning strategies, especially for high sparsity. Our preliminary exploration also discloses that using calibration data similar to the training data can yield better performance. As pre-training data is usually inaccessible for advanced LLMs, we further provide a self-generating calibration data synthesis strategy to construct feasible calibration data. We conduct experiments on the recent strong open-source LLMs (e.g., DCLM, and LLaMA-3), and the results show that the proposed method outperforms commonly used calibration data and can effectively enhance strong pruning methods (e.g., Wanda, OWL).
OPT-Tree: Speculative Decoding with Adaptive Draft Tree Structure
Jun 25, 2024



Autoregressive language models demonstrate excellent performance in various scenarios. However, the inference efficiency is limited by its one-step-one-word generation mode, which has become a pressing problem recently as the models become increasingly larger. Speculative decoding employs a "draft and then verify" mechanism to allow multiple tokens to be generated in one step, realizing lossless acceleration. Existing methods mainly adopt fixed heuristic draft structures, which fail to adapt to different situations to maximize the acceptance length during verification. To alleviate this dilemma, we proposed OPT-Tree, an algorithm to construct adaptive and scalable draft trees. It searches the optimal tree structure that maximizes the mathematical expectation of the acceptance length in each decoding step. Experimental results reveal that OPT-Tree outperforms the existing draft structures and achieves a speed-up ratio of up to 3.2 compared with autoregressive decoding. If the draft model is powerful enough and the node budget is sufficient, it can generate more than ten tokens in a single step. Our code is available at https://github.com/Jikai0Wang/OPT-Tree.
AuG-KD: Anchor-Based Mixup Generation for Out-of-Domain Knowledge Distillation
Mar 18, 2024
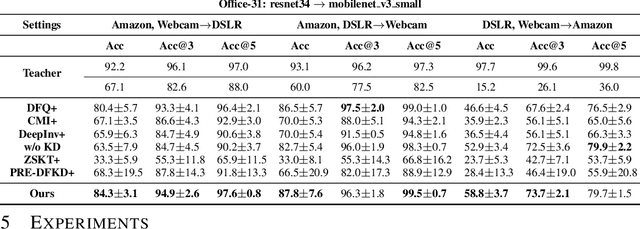
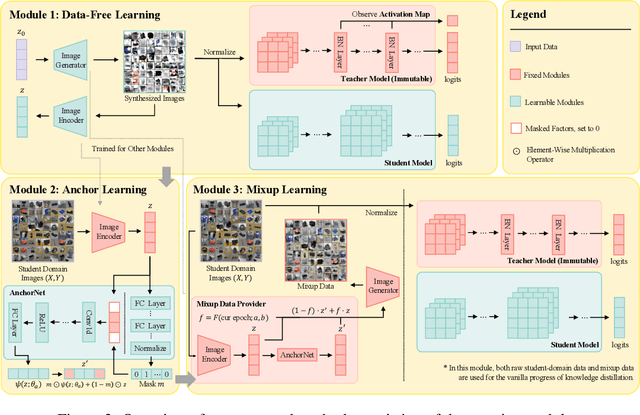
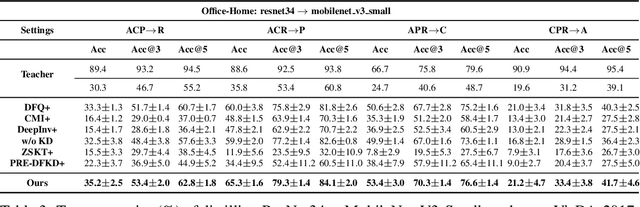
Due to privacy or patent concerns, a growing number of large models are released without granting access to their training data, making transferring their knowledge inefficient and problematic. In response, Data-Free Knowledge Distillation (DFKD) methods have emerged as direct solutions. However, simply adopting models derived from DFKD for real-world applications suffers significant performance degradation, due to the discrepancy between teachers' training data and real-world scenarios (student domain). The degradation stems from the portions of teachers' knowledge that are not applicable to the student domain. They are specific to the teacher domain and would undermine students' performance. Hence, selectively transferring teachers' appropriate knowledge becomes the primary challenge in DFKD. In this work, we propose a simple but effective method AuG-KD. It utilizes an uncertainty-guided and sample-specific anchor to align student-domain data with the teacher domain and leverages a generative method to progressively trade off the learning process between OOD knowledge distillation and domain-specific information learning via mixup learning. Extensive experiments in 3 datasets and 8 settings demonstrate the stability and superiority of our approach. Code available at https://github.com/IshiKura-a/AuG-KD .
A General and Flexible Multi-concept Parsing Framework for Multilingual Semantic Matching
Mar 05, 2024



Sentence semantic matching is a research hotspot in natural language processing, which is considerably significant in various key scenarios, such as community question answering, searching, chatbot, and recommendation. Since most of the advanced models directly model the semantic relevance among words between two sentences while neglecting the \textit{keywords} and \textit{intents} concepts of them, DC-Match is proposed to disentangle keywords from intents and utilizes them to optimize the matching performance. Although DC-Match is a simple yet effective method for semantic matching, it highly depends on the external NER techniques to identify the keywords of sentences, which limits the performance of semantic matching for minor languages since satisfactory NER tools are usually hard to obtain. In this paper, we propose to generally and flexibly resolve the text into multi concepts for multilingual semantic matching to liberate the model from the reliance on NER models. To this end, we devise a \underline{M}ulti-\underline{C}oncept \underline{P}arsed \underline{S}emantic \underline{M}atching framework based on the pre-trained language models, abbreviated as \textbf{MCP-SM}, to extract various concepts and infuse them into the classification tokens. We conduct comprehensive experiments on English datasets QQP and MRPC, and Chinese dataset Medical-SM. Besides, we experiment on Arabic datasets MQ2Q and XNLI, the outstanding performance further prove MCP-SM's applicability in low-resource languages.
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
Jan 02, 2024Style transfer for out-of-domain (OOD) singing voice synthesis (SVS) focuses on generating high-quality singing voices with unseen styles (such as timbre, emotion, pronunciation, and articulation skills) derived from reference singing voice samples. However, the endeavor to model the intricate nuances of singing voice styles is an arduous task, as singing voices possess a remarkable degree of expressiveness. Moreover, existing SVS methods encounter a decline in the quality of synthesized singing voices in OOD scenarios, as they rest upon the assumption that the target vocal attributes are discernible during the training phase. To overcome these challenges, we propose StyleSinger, the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples. StyleSinger incorporates two critical approaches for enhanced effectiveness: 1) the Residual Style Adaptor (RSA) which employs a residual quantization module to capture diverse style characteristics in singing voices, and 2) the Uncertainty Modeling Layer Normalization (UMLN) to perturb the style attributes within the content representation during the training phase and thus improve the model generalization. Our extensive evaluations in zero-shot style transfer undeniably establish that StyleSinger outperforms baseline models in both audio quality and similarity to the reference singing voice samples. Access to singing voice samples can be found at https://stylesinger.github.io/.
TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation
Dec 23, 2023Direct speech-to-speech translation achieves high-quality results through the introduction of discrete units obtained from self-supervised learning. This approach circumvents delays and cascading errors associated with model cascading. However, talking head translation, converting audio-visual speech (i.e., talking head video) from one language into another, still confronts several challenges compared to audio speech: (1) Existing methods invariably rely on cascading, synthesizing via both audio and text, resulting in delays and cascading errors. (2) Talking head translation has a limited set of reference frames. If the generated translation exceeds the length of the original speech, the video sequence needs to be supplemented by repeating frames, leading to jarring video transitions. In this work, we propose a model for talking head translation, \textbf{TransFace}, which can directly translate audio-visual speech into audio-visual speech in other languages. It consists of a speech-to-unit translation model to convert audio speech into discrete units and a unit-based audio-visual speech synthesizer, Unit2Lip, to re-synthesize synchronized audio-visual speech from discrete units in parallel. Furthermore, we introduce a Bounded Duration Predictor, ensuring isometric talking head translation and preventing duplicate reference frames. Experiments demonstrate that our proposed Unit2Lip model significantly improves synchronization (1.601 and 0.982 on LSE-C for the original and generated audio speech, respectively) and boosts inference speed by a factor of 4.35 on LRS2. Additionally, TransFace achieves impressive BLEU scores of 61.93 and 47.55 for Es-En and Fr-En on LRS3-T and 100% isochronous translations.
How Well Do Large Language Models Understand Syntax? An Evaluation by Asking Natural Language Questions
Nov 14, 2023
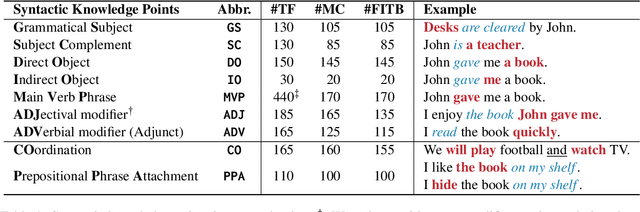


While recent advancements in large language models (LLMs) bring us closer to achieving artificial general intelligence, the question persists: Do LLMs truly understand language, or do they merely mimic comprehension through pattern recognition? This study seeks to explore this question through the lens of syntax, a crucial component of sentence comprehension. Adopting a natural language question-answering (Q&A) scheme, we craft questions targeting nine syntactic knowledge points that are most closely related to sentence comprehension. Experiments conducted on 24 LLMs suggest that most have a limited grasp of syntactic knowledge, exhibiting notable discrepancies across different syntactic knowledge points. In particular, questions involving prepositional phrase attachment pose the greatest challenge, whereas those concerning adjectival modifier and indirect object are relatively easier for LLMs to handle. Furthermore, a case study on the training dynamics of the LLMs reveals that the majority of syntactic knowledge is learned during the initial stages of training, hinting that simply increasing the number of training tokens may not be the `silver bullet' for improving the comprehension ability of LLMs.