Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs It Really Useful to Jointly Parse Constituency and Dependency Trees? A Revisit
Paper and Code
Sep 21, 2023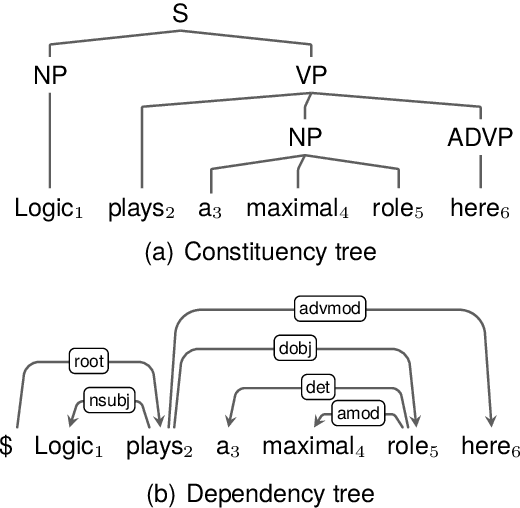
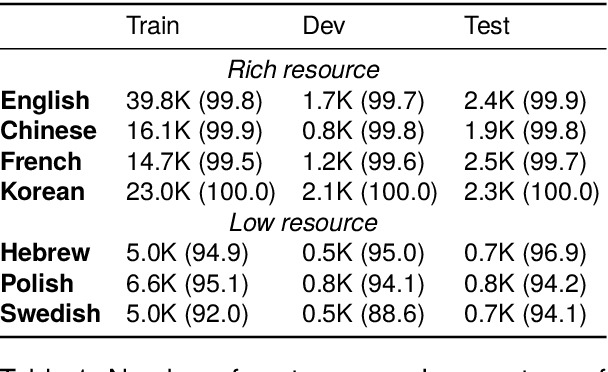


This work visits the topic of jointly parsing constituency and dependency trees, i.e., to produce compatible constituency and dependency trees simultaneously for input sentences, which is attractive considering that the two types of trees are complementary in representing syntax. Compared with previous works, we make progress in four aspects: (1) adopting a much more efficient decoding algorithm, (2) exploring joint modeling at the training phase, instead of only at the inference phase, (3) proposing high-order scoring components for constituent-dependency interaction, (4) gaining more insights via in-depth experiments and analysis.
View paper on