 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Contrast CT Esophageal Varices Grading through Clinical Prior-Enhanced Multi-Organ Analysis
Dec 22, 2025Esophageal varices (EV) represent a critical complication of portal hypertension, affecting approximately 60% of cirrhosis patients with a significant bleeding risk of ~30%. While traditionally diagnosed through invasive endoscopy, non-contrast computed tomography (NCCT) presents a potential non-invasive alternative that has yet to be fully utilized in clinical practice. We present Multi-Organ-COhesion Network++ (MOON++), a novel multimodal framework that enhances EV assessment through comprehensive analysis of NCCT scans. Inspired by clinical evidence correlating organ volumetric relationships with liver disease severity, MOON++ synthesizes imaging characteristics of the esophagus, liver, and spleen through multimodal learning. We evaluated our approach using 1,631 patients, those with endoscopically confirmed EV were classified into four severity grades. Validation in 239 patient cases and independent testing in 289 cases demonstrate superior performance compared to conventional single organ methods, achieving an AUC of 0.894 versus 0.803 for the severe grade EV classification (G3 versus <G3) and 0.921 versus 0.793 for the differentiation of moderate to severe grades (>=G2 versus <G2). We conducted a reader study involving experienced radiologists to further validate the performance of MOON++. To our knowledge, MOON++ represents the first comprehensive multi-organ NCCT analysis framework incorporating clinical knowledge priors for EV assessment, potentially offering a promising non-invasive diagnostic alternative.
Self-Correction Makes LLMs Better Parsers
Apr 19, 2025Large language models (LLMs) have achieved remarkable success across various natural language processing (NLP) tasks. However, recent studies suggest that they still face challenges in performing fundamental NLP tasks essential for deep language understanding, particularly syntactic parsing. In this paper, we conduct an in-depth analysis of LLM parsing capabilities, delving into the specific shortcomings of their parsing results. We find that LLMs may stem from limitations to fully leverage grammar rules in existing treebanks, which restricts their capability to generate valid syntactic structures. To help LLMs acquire knowledge without additional training, we propose a self-correction method that leverages grammar rules from existing treebanks to guide LLMs in correcting previous errors. Specifically, we automatically detect potential errors and dynamically search for relevant rules, offering hints and examples to guide LLMs in making corrections themselves. Experimental results on three datasets with various LLMs, demonstrate that our method significantly improves performance in both in-domain and cross-domain settings on the English and Chinese datasets.
Double Landmines: Invisible Textual Backdoor Attacks based on Dual-Trigger
Dec 23, 2024At present, all textual backdoor attack methods are based on single triggers: for example, inserting specific content into the text to activate the backdoor; or changing the abstract text features. The former is easier to be identified by existing defense strategies due to its obvious characteristics; the latter, although improved in invisibility, has certain shortcomings in terms of attack performance, construction of poisoned datasets, and selection of the final poisoning rate. On this basis, this paper innovatively proposes a Dual-Trigger backdoor attack based on syntax and mood, and optimizes the construction of the poisoned dataset and the selection strategy of the final poisoning rate. A large number of experimental results show that this method significantly outperforms the previous methods based on abstract features in attack performance, and achieves comparable attack performance (almost 100% attack success rate) with the insertion-based method. In addition, the two trigger mechanisms included in this method can be activated independently in the application phase of the model, which not only improves the flexibility of the trigger style, but also enhances its robustness against defense strategies. These results profoundly reveal that textual backdoor attacks are extremely harmful and provide a new perspective for security protection in this field.
Mining Word Boundaries from Speech-Text Parallel Data for Cross-domain Chinese Word Segmentation
Dec 12, 2024



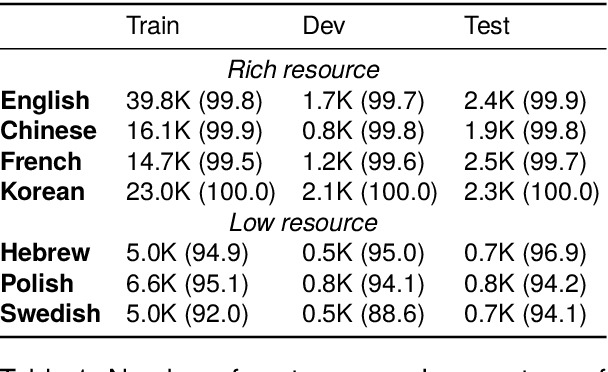
Inspired by early research on exploring naturally annotated data for Chinese Word Segmentation (CWS), and also by recent research on integration of speech and text processing, this work for the first time proposes to explicitly mine word boundaries from speech-text parallel data. We employ the Montreal Forced Aligner (MFA) toolkit to perform character-level alignment on speech-text data, giving pauses as candidate word boundaries. Based on detailed analysis of collected pauses, we propose an effective probability-based strategy for filtering unreliable word boundaries. To more effectively utilize word boundaries as extra training data, we also propose a robust complete-then-train (CTT) strategy. We conduct cross-domain CWS experiments on two target domains, i.e., ZX and AISHELL2. We have annotated about 1,000 sentences as the evaluation data of AISHELL2. Experiments demonstrate the effectiveness of our proposed approach.
Character-Level Chinese Dependency Parsing via Modeling Latent Intra-Word Structure
Jun 06, 2024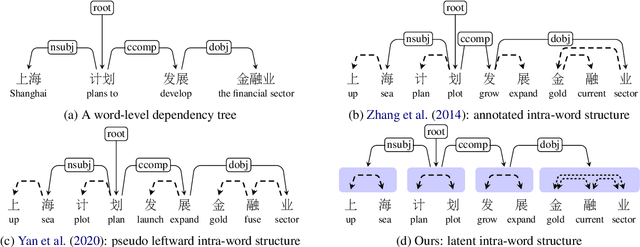
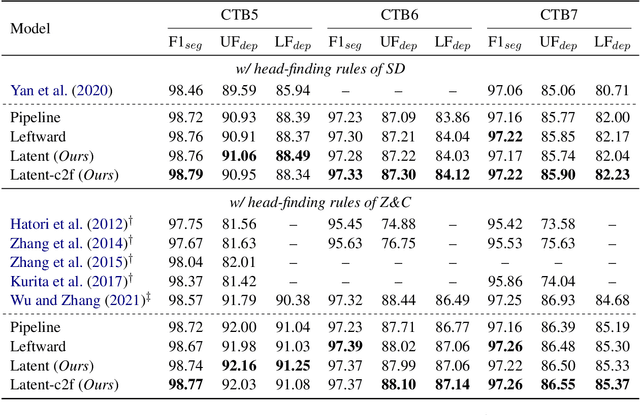
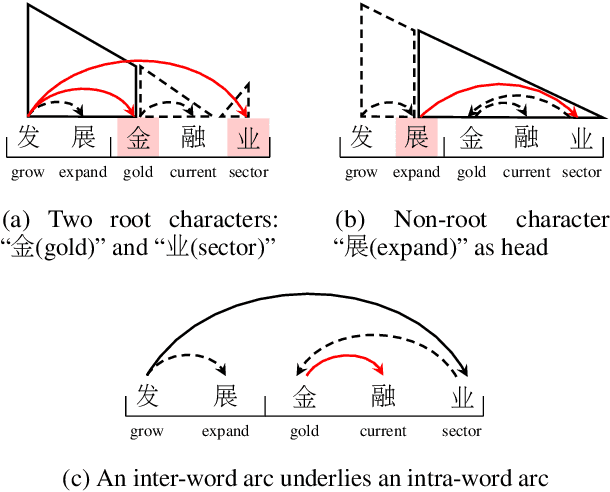

Revealing the syntactic structure of sentences in Chinese poses significant challenges for word-level parsers due to the absence of clear word boundaries. To facilitate a transition from word-level to character-level Chinese dependency parsing, this paper proposes modeling latent internal structures within words. In this way, each word-level dependency tree is interpreted as a forest of character-level trees. A constrained Eisner algorithm is implemented to ensure the compatibility of character-level trees, guaranteeing a single root for intra-word structures and establishing inter-word dependencies between these roots. Experiments on Chinese treebanks demonstrate the superiority of our method over both the pipeline framework and previous joint models. A detailed analysis reveals that a coarse-to-fine parsing strategy empowers the model to predict more linguistically plausible intra-word structures.
PolyGlotFake: A Novel Multilingual and Multimodal DeepFake Dataset
May 14, 2024With the rapid advancement of generative AI, multimodal deepfakes, which manipulate both audio and visual modalities, have drawn increasing public concern. Currently, deepfake detection has emerged as a crucial strategy in countering these growing threats. However, as a key factor in training and validating deepfake detectors, most existing deepfake datasets primarily focus on the visual modal, and the few that are multimodal employ outdated techniques, and their audio content is limited to a single language, thereby failing to represent the cutting-edge advancements and globalization trends in current deepfake technologies. To address this gap, we propose a novel, multilingual, and multimodal deepfake dataset: PolyGlotFake. It includes content in seven languages, created using a variety of cutting-edge and popular Text-to-Speech, voice cloning, and lip-sync technologies. We conduct comprehensive experiments using state-of-the-art detection methods on PolyGlotFake dataset. These experiments demonstrate the dataset's significant challenges and its practical value in advancing research into multimodal deepfake detection.
How Well Do Large Language Models Understand Syntax? An Evaluation by Asking Natural Language Questions
Nov 14, 2023
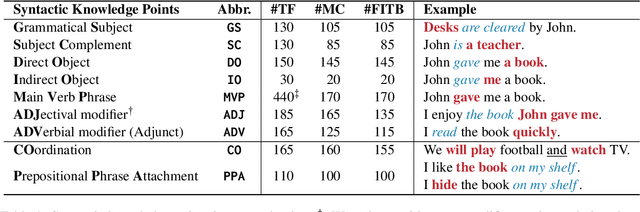


While recent advancements in large language models (LLMs) bring us closer to achieving artificial general intelligence, the question persists: Do LLMs truly understand language, or do they merely mimic comprehension through pattern recognition? This study seeks to explore this question through the lens of syntax, a crucial component of sentence comprehension. Adopting a natural language question-answering (Q&A) scheme, we craft questions targeting nine syntactic knowledge points that are most closely related to sentence comprehension. Experiments conducted on 24 LLMs suggest that most have a limited grasp of syntactic knowledge, exhibiting notable discrepancies across different syntactic knowledge points. In particular, questions involving prepositional phrase attachment pose the greatest challenge, whereas those concerning adjectival modifier and indirect object are relatively easier for LLMs to handle. Furthermore, a case study on the training dynamics of the LLMs reveals that the majority of syntactic knowledge is learned during the initial stages of training, hinting that simply increasing the number of training tokens may not be the `silver bullet' for improving the comprehension ability of LLMs.
Is It Really Useful to Jointly Parse Constituency and Dependency Trees? A Revisit
Sep 21, 2023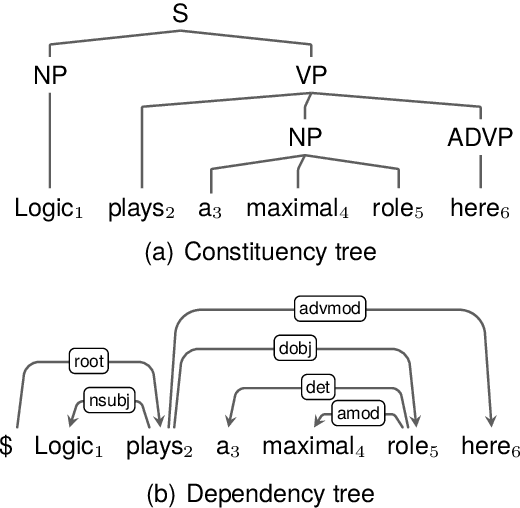


This work visits the topic of jointly parsing constituency and dependency trees, i.e., to produce compatible constituency and dependency trees simultaneously for input sentences, which is attractive considering that the two types of trees are complementary in representing syntax. Compared with previous works, we make progress in four aspects: (1) adopting a much more efficient decoding algorithm, (2) exploring joint modeling at the training phase, instead of only at the inference phase, (3) proposing high-order scoring components for constituent-dependency interaction, (4) gaining more insights via in-depth experiments and analysis.
Evading DeepFake Detectors via Adversarial Statistical Consistency
Apr 23, 2023
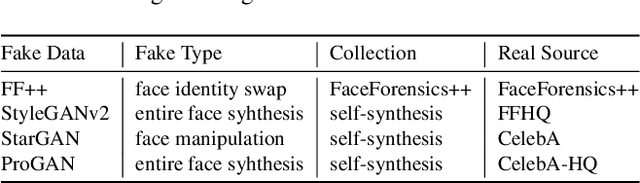


In recent years, as various realistic face forgery techniques known as DeepFake improves by leaps and bounds,more and more DeepFake detection techniques have been proposed. These methods typically rely on detecting statistical differences between natural (i.e., real) and DeepFakegenerated images in both spatial and frequency domains. In this work, we propose to explicitly minimize the statistical differences to evade state-of-the-art DeepFake detectors. To this end, we propose a statistical consistency attack (StatAttack) against DeepFake detectors, which contains two main parts. First, we select several statistical-sensitive natural degradations (i.e., exposure, blur, and noise) and add them to the fake images in an adversarial way. Second, we find that the statistical differences between natural and DeepFake images are positively associated with the distribution shifting between the two kinds of images, and we propose to use a distribution-aware loss to guide the optimization of different degradations. As a result, the feature distributions of generated adversarial examples is close to the natural images.Furthermore, we extend the StatAttack to a more powerful version, MStatAttack, where we extend the single-layer degradation to multi-layer degradations sequentially and use the loss to tune the combination weights jointly. Comprehensive experimental results on four spatial-based detectors and two frequency-based detectors with four datasets demonstrate the effectiveness of our proposed attack method in both white-box and black-box settings.