 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Smart, Not Hard: Difficulty Adaptive Reasoning for Large Audio Language Models
Sep 26, 2025Large Audio Language Models (LALMs), powered by the chain-of-thought (CoT) paradigm, have shown remarkable reasoning capabilities. Intuitively, different problems often require varying depths of reasoning. While some methods can determine whether to reason for a given problem, they typically lack a fine-grained mechanism to modulate how much to reason. This often results in a ``one-size-fits-all'' reasoning depth, which generates redundant overthinking for simple questions while failing to allocate sufficient thought to complex ones. In this paper, we conduct an in-depth analysis of LALMs and find that an effective and efficient LALM should reason smartly by adapting its reasoning depth to the problem's complexity. To achieve this, we propose a difficulty-adaptive reasoning method for LALMs. Specifically, we propose a reward function that dynamically links reasoning length to the model's perceived problem difficulty. This reward encourages shorter, concise reasoning for easy tasks and more elaborate, in-depth reasoning for complex ones. Extensive experiments demonstrate that our method is both effective and efficient, simultaneously improving task performance and significantly reducing the average reasoning length. Further analysis on reasoning structure paradigm offers valuable insights for future work.
Improving Contextual ASR via Multi-grained Fusion with Large Language Models
Jul 16, 2025While end-to-end Automatic Speech Recognition (ASR) models have shown impressive performance in transcribing general speech, they often struggle to accurately recognize contextually relevant keywords, such as proper nouns or user-specific entities. Previous approaches have explored leveraging keyword dictionaries in the textual modality to improve keyword recognition, either through token-level fusion that guides token-by-token generation or phrase-level fusion that enables direct copying of keyword phrases. However, these methods operate at different granularities and have their own limitations. In this paper, we propose a novel multi-grained fusion approach that jointly leverages the strengths of both token-level and phrase-level fusion with Large Language Models (LLMs). Our approach incorporates a late-fusion strategy that elegantly combines ASR's acoustic information with LLM's rich contextual knowledge, balancing fine-grained token precision with holistic phrase-level understanding. Experiments on Chinese and English datasets demonstrate that our approach achieves state-of-the-art performance on keyword-related metrics while preserving high accuracy on non-keyword text. Ablation studies further confirm that the token-level and phrase-level components both contribute significantly to the performance gains, complementing each other in our joint multi-grained framework. The code and models will be publicly available at https://github.com/.
Mining Word Boundaries from Speech-Text Parallel Data for Cross-domain Chinese Word Segmentation
Dec 12, 2024



Inspired by early research on exploring naturally annotated data for Chinese Word Segmentation (CWS), and also by recent research on integration of speech and text processing, this work for the first time proposes to explicitly mine word boundaries from speech-text parallel data. We employ the Montreal Forced Aligner (MFA) toolkit to perform character-level alignment on speech-text data, giving pauses as candidate word boundaries. Based on detailed analysis of collected pauses, we propose an effective probability-based strategy for filtering unreliable word boundaries. To more effectively utilize word boundaries as extra training data, we also propose a robust complete-then-train (CTT) strategy. We conduct cross-domain CWS experiments on two target domains, i.e., ZX and AISHELL2. We have annotated about 1,000 sentences as the evaluation data of AISHELL2. Experiments demonstrate the effectiveness of our proposed approach.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
CopyNE: Better Contextual ASR by Copying Named Entities
May 22, 2023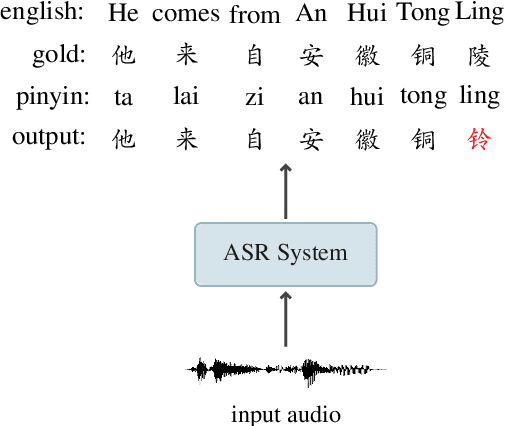
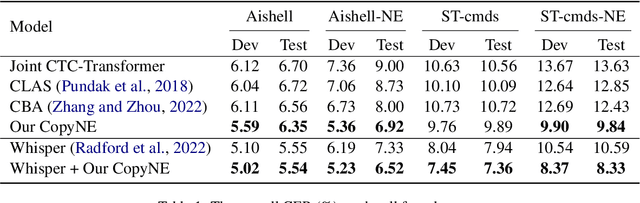
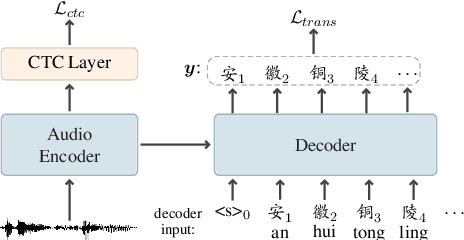
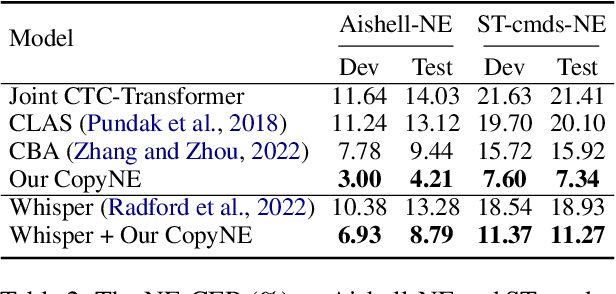
Recent years have seen remarkable progress in automatic speech recognition (ASR). However, traditional token-level ASR models have struggled with accurately transcribing entities due to the problem of homophonic and near-homophonic tokens. This paper introduces a novel approach called CopyNE, which uses a span-level copying mechanism to improve ASR in transcribing entities. CopyNE can copy all tokens of an entity at once, effectively avoiding errors caused by homophonic or near-homophonic tokens that occur when predicting multiple tokens separately. Experiments on Aishell and ST-cmds datasets demonstrate that CopyNE achieves significant reductions in character error rate (CER) and named entity CER (NE-CER), especially in entity-rich scenarios. Furthermore, even when compared to the strong Whisper baseline, CopyNE still achieves notable reductions in CER and NE-CER. Qualitative comparisons with previous approaches demonstrate that CopyNE can better handle entities, effectively improving the accuracy of ASR.
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
Apr 04, 2023



Training a convolutional neural network (CNN) to detect infrared small targets in a fully supervised manner has gained remarkable research interests in recent years, but is highly labor expensive since a large number of per-pixel annotations are required. To handle this problem, in this paper, we make the first attempt to achieve infrared small target detection with point-level supervision. Interestingly, during the training phase supervised by point labels, we discover that CNNs first learn to segment a cluster of pixels near the targets, and then gradually converge to predict groundtruth point labels. Motivated by this "mapping degeneration" phenomenon, we propose a label evolution framework named label evolution with single point supervision (LESPS) to progressively expand the point label by leveraging the intermediate predictions of CNNs. In this way, the network predictions can finally approximate the updated pseudo labels, and a pixel-level target mask can be obtained to train CNNs in an end-to-end manner. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Experimental results show that CNNs equipped with LESPS can well recover the target masks from corresponding point labels, {and can achieve over 70% and 95% of their fully supervised performance in terms of pixel-level intersection over union (IoU) and object-level probability of detection (Pd), respectively. Code is available at https://github.com/XinyiYing/LESPS.
Learning Non-Local Spatial-Angular Correlation for Light Field Image Super-Resolution
Feb 18, 2023
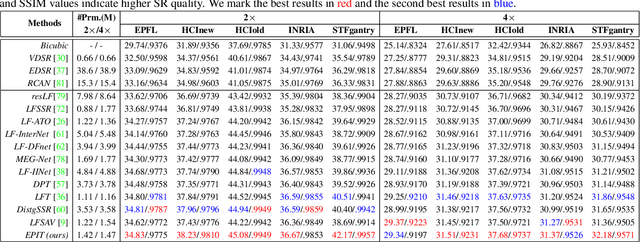
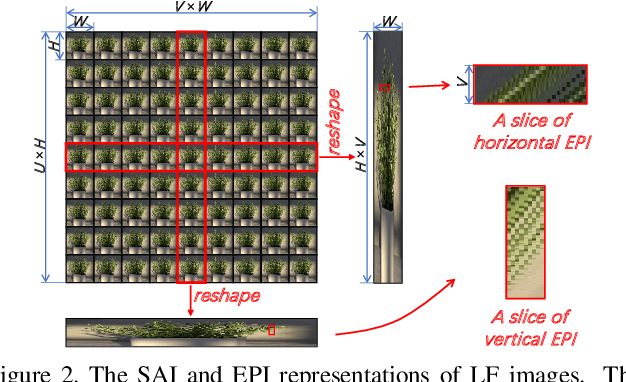
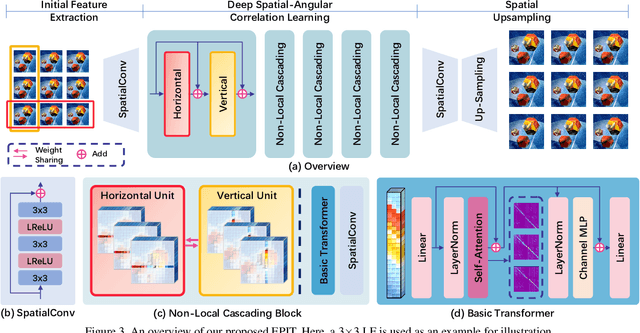
Exploiting spatial-angular correlation is crucial to light field (LF) image super-resolution (SR), but is highly challenging due to its non-local property caused by the disparities among LF images. Although many deep neural networks (DNNs) have been developed for LF image SR and achieved continuously improved performance, existing methods cannot well leverage the long-range spatial-angular correlation and thus suffer a significant performance drop when handling scenes with large disparity variations. In this paper, we propose a simple yet effective method to learn the non-local spatial-angular correlation for LF image SR. In our method, we adopt the epipolar plane image (EPI) representation to project the 4D spatial-angular correlation onto multiple 2D EPI planes, and then develop a Transformer network with repetitive self-attention operations to learn the spatial-angular correlation by modeling the dependencies between each pair of EPI pixels. Our method can fully incorporate the information from all angular views while achieving a global receptive field along the epipolar line. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Comparative results on five public datasets show that our method not only achieves state-of-the-art SR performance, but also performs robust to disparity variations. Code is publicly available at https://github.com/ZhengyuLiang24/EPIT.
Mining Word Boundaries in Speech as Naturally Annotated Word Segmentation Data
Oct 31, 2022

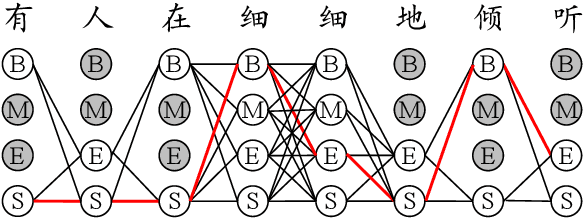

Chinese word segmentation (CWS) models have achieved very high performance when the training data is sufficient and in-domain. However, the performance drops drastically when shifting to cross-domain and low-resource scenarios due to data sparseness issues. Considering that constructing large-scale manually annotated data is time-consuming and labor-intensive, in this work, we for the first time propose to mine word boundary information from pauses in speech to efficiently obtain large-scale CWS naturally annotated data. We present a simple yet effective complete-then-train method to utilize these natural annotations from speech for CWS model training. Extensive experiments demonstrate that the CWS performance in cross-domain and low-resource scenarios can be significantly improved by leveraging our naturally annotated data extracted from speech.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022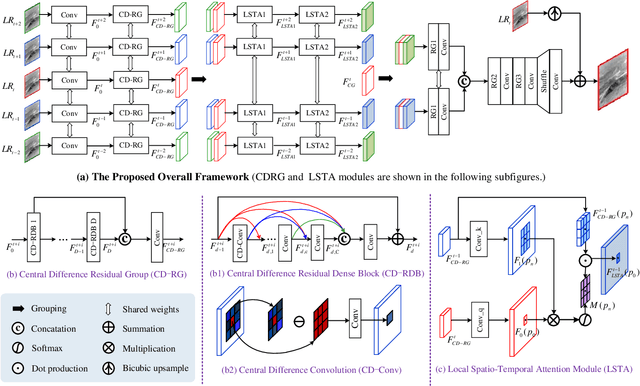
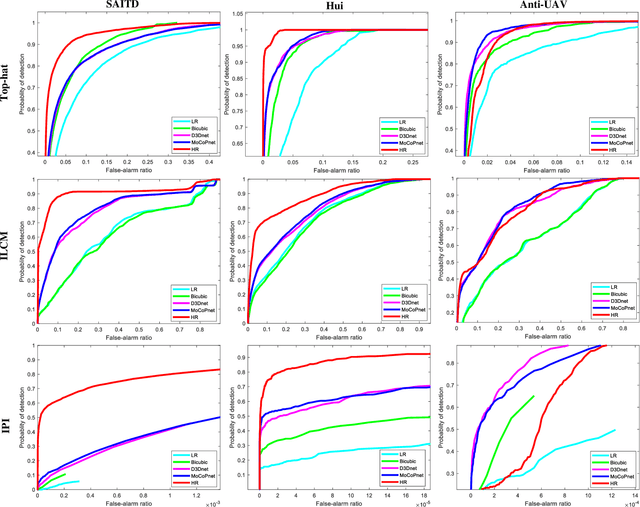

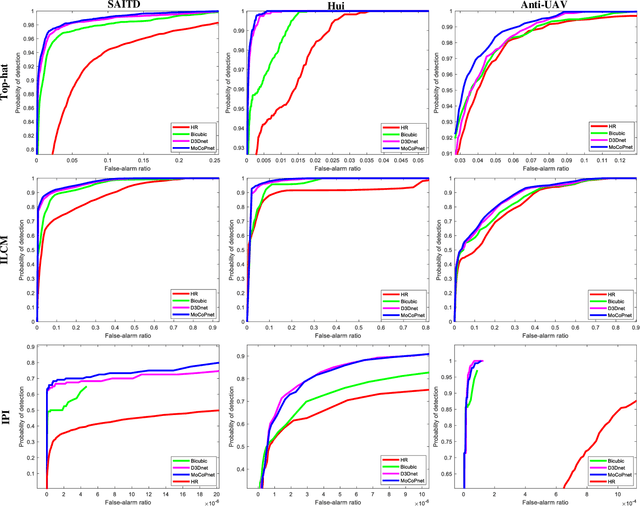
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Fast and Accurate Span-based Semantic Role Labeling as Graph Parsing
Dec 06, 2021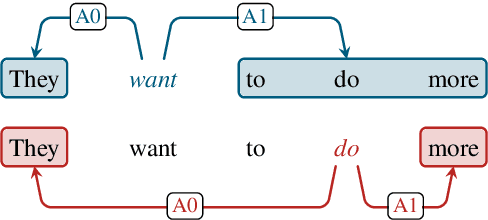
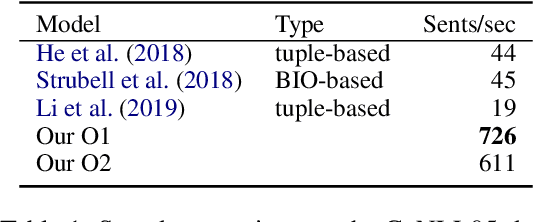
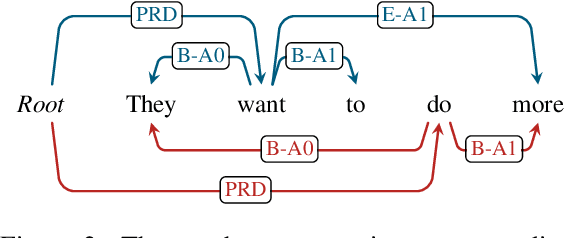
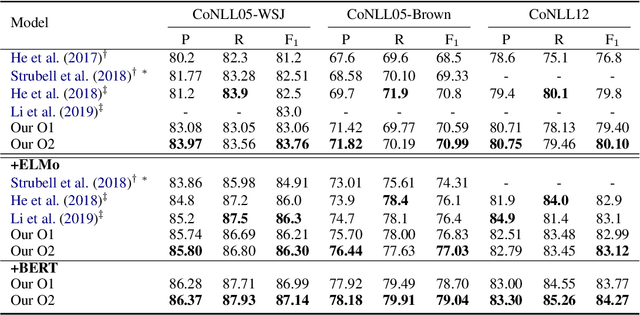
Currently, BIO-based and tuple-based approaches perform quite well on the span-based semantic role labeling (SRL) task. However, the BIO-based approach usually needs to encode a sentence once for each predicate when predicting its arguments, and the tuple-based approach has to deal with a huge search space of $O(n^3)$, greatly reducing the training and inference efficiency. The parsing speed is less than 50 sentences per second. Moreover, both BIO-based and tuple-based approaches usually consider only local structural information when making predictions. This paper proposes to cast end-to-end span-based SRL as a graph parsing task. Based on a novel graph representation schema, we present a fast and accurate SRL parser on the shoulder of recent works on high-order semantic dependency graph parsing. Moreover, we propose a constrained Viterbi procedure to ensure the legality of the output graph. Experiments on English CoNLL05 and CoNLL12 datasets show that our model achieves new state-of-the-art results under both settings of without and with pre-trained language models, and can parse over 600 sentences per second.