 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyNE: Better Contextual ASR by Copying Named Entities
Paper and Code
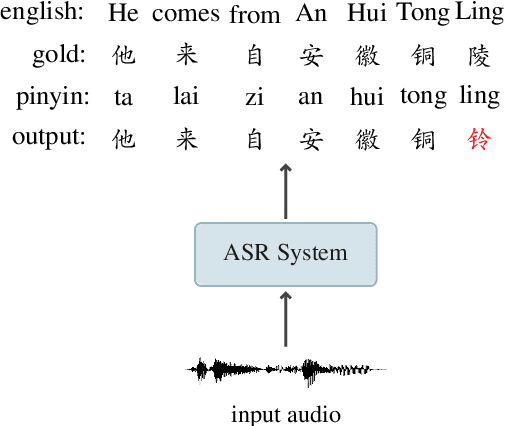
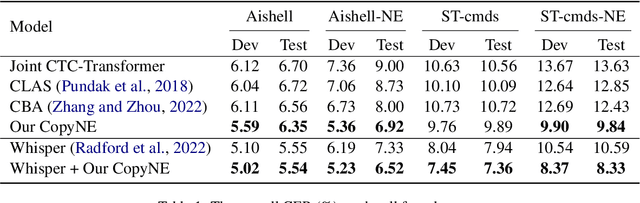
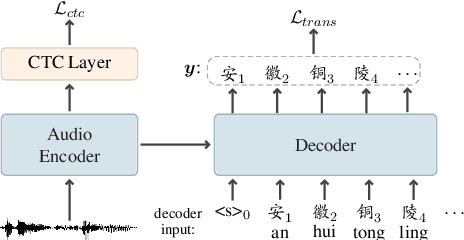
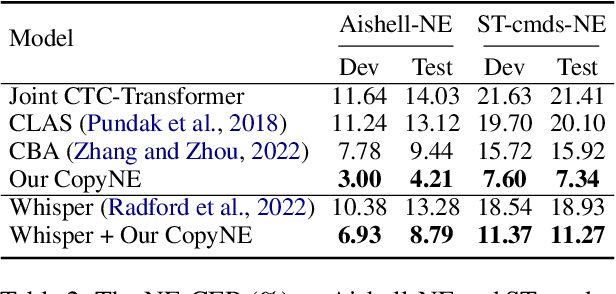
Recent years have seen remarkable progress in automatic speech recognition (ASR). However, traditional token-level ASR models have struggled with accurately transcribing entities due to the problem of homophonic and near-homophonic tokens. This paper introduces a novel approach called CopyNE, which uses a span-level copying mechanism to improve ASR in transcribing entities. CopyNE can copy all tokens of an entity at once, effectively avoiding errors caused by homophonic or near-homophonic tokens that occur when predicting multiple tokens separately. Experiments on Aishell and ST-cmds datasets demonstrate that CopyNE achieves significant reductions in character error rate (CER) and named entity CER (NE-CER), especially in entity-rich scenarios. Furthermore, even when compared to the strong Whisper baseline, CopyNE still achieves notable reductions in CER and NE-CER. Qualitative comparisons with previous approaches demonstrate that CopyNE can better handle entities, effectively improving the accuracy of ASR.