 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
SpecDETR: A Transformer-based Hyperspectral Point Object Detection Network
May 16, 2024



Hyperspectral target detection (HTD) aims to identify specific materials based on spectral information in hyperspectral imagery and can detect point targets, some of which occupy a smaller than one-pixel area. However, existing HTD methods are developed based on per-pixel binary classification, which limits the feature representation capability for point targets. In this paper, we rethink the hyperspectral point target detection from the object detection perspective, and focus more on the object-level prediction capability rather than the pixel classification capability. Inspired by the token-based processing flow of Detection Transformer (DETR), we propose the first specialized network for hyperspectral multi-class point object detection, SpecDETR. Without the backbone part of the current object detection framework, SpecDETR treats the spectral features of each pixel in hyperspectral images as a token and utilizes a multi-layer Transformer encoder with local and global coordination attention modules to extract deep spatial-spectral joint features. SpecDETR regards point object detection as a one-to-many set prediction problem, thereby achieving a concise and efficient DETR decoder that surpasses the current state-of-the-art DETR decoder in terms of parameters and accuracy in point object detection. We develop a simulated hyperSpectral Point Object Detection benchmark termed SPOD, and for the first time, evaluate and compare the performance of current object detection networks and HTD methods on hyperspectral multi-class point object detection. SpecDETR demonstrates superior performance as compared to current object detection networks and HTD methods on the SPOD dataset. Additionally, we validate on a public HTD dataset that by using data simulation instead of manual annotation, SpecDETR can detect real-world single-spectral point objects directly.
Monte Carlo Linear Clustering with Single-Point Supervision is Enough for Infrared Small Target Detection
Apr 10, 2023



Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds on infrared images. Recently, deep learning based methods have achieved promising performance on SIRST detection, but at the cost of a large amount of training data with expensive pixel-level annotations. To reduce the annotation burden, we propose the first method to achieve SIRST detection with single-point supervision. The core idea of this work is to recover the per-pixel mask of each target from the given single point label by using clustering approaches, which looks simple but is indeed challenging since targets are always insalient and accompanied with background clutters. To handle this issue, we introduce randomness to the clustering process by adding noise to the input images, and then obtain much more reliable pseudo masks by averaging the clustered results. Thanks to this "Monte Carlo" clustering approach, our method can accurately recover pseudo masks and thus turn arbitrary fully supervised SIRST detection networks into weakly supervised ones with only single point annotation. Experiments on four datasets demonstrate that our method can be applied to existing SIRST detection networks to achieve comparable performance with their fully supervised counterparts, which reveals that single-point supervision is strong enough for SIRST detection. Our code will be available at: https://github.com/YeRen123455/SIRST-Single-Point-Supervision.
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
Apr 04, 2023



Training a convolutional neural network (CNN) to detect infrared small targets in a fully supervised manner has gained remarkable research interests in recent years, but is highly labor expensive since a large number of per-pixel annotations are required. To handle this problem, in this paper, we make the first attempt to achieve infrared small target detection with point-level supervision. Interestingly, during the training phase supervised by point labels, we discover that CNNs first learn to segment a cluster of pixels near the targets, and then gradually converge to predict groundtruth point labels. Motivated by this "mapping degeneration" phenomenon, we propose a label evolution framework named label evolution with single point supervision (LESPS) to progressively expand the point label by leveraging the intermediate predictions of CNNs. In this way, the network predictions can finally approximate the updated pseudo labels, and a pixel-level target mask can be obtained to train CNNs in an end-to-end manner. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Experimental results show that CNNs equipped with LESPS can well recover the target masks from corresponding point labels, {and can achieve over 70% and 95% of their fully supervised performance in terms of pixel-level intersection over union (IoU) and object-level probability of detection (Pd), respectively. Code is available at https://github.com/XinyiYing/LESPS.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023



In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022
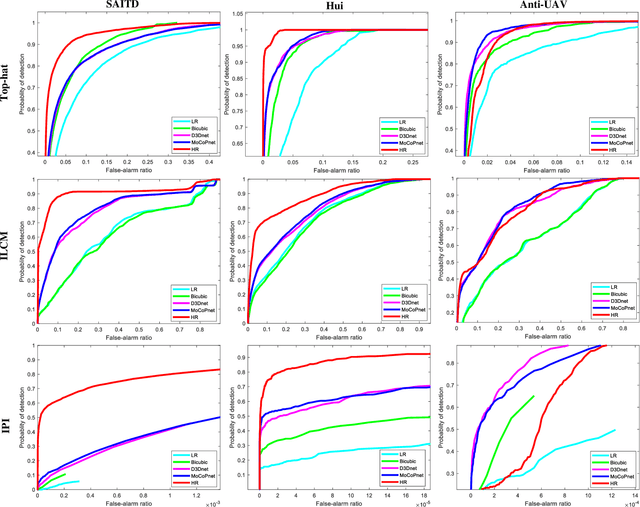

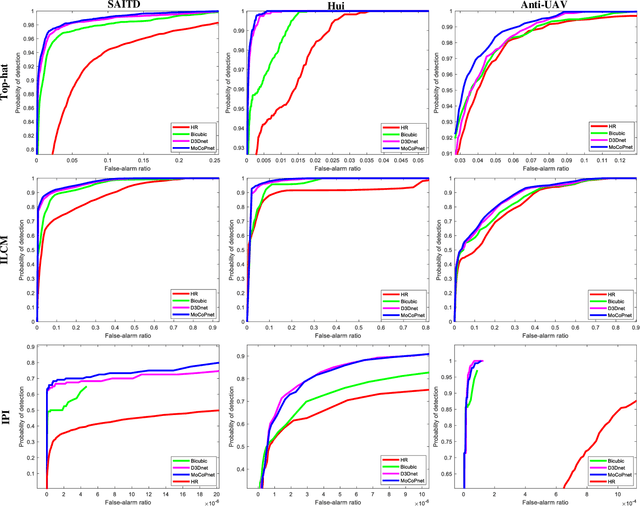
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021
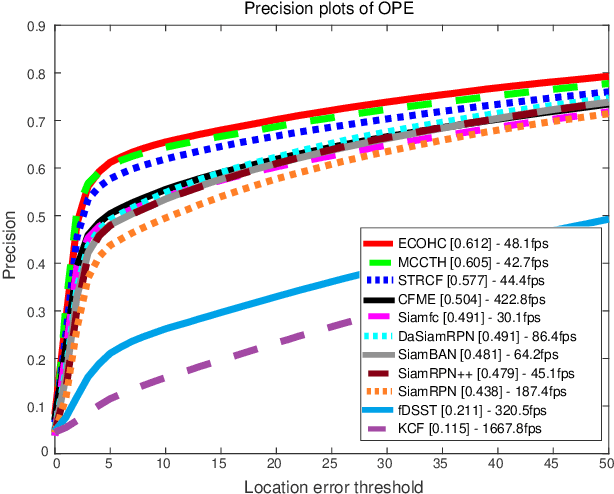
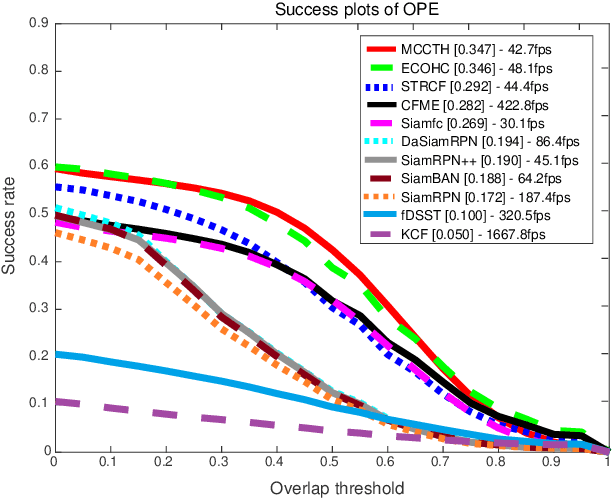

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.
Dense Nested Attention Network for Infrared Small Target Detection
Jun 01, 2021

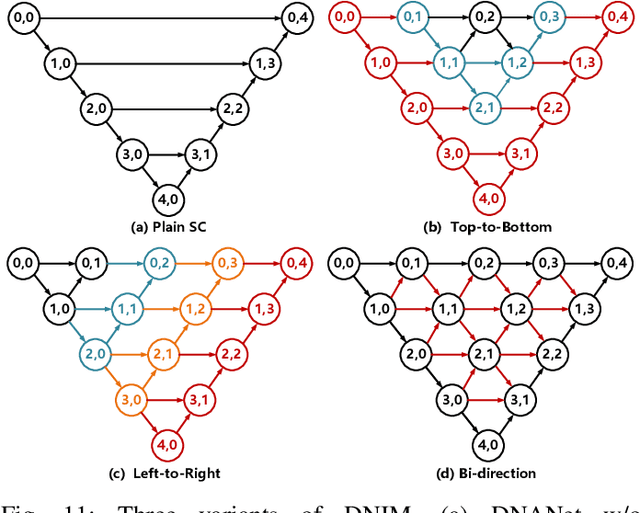
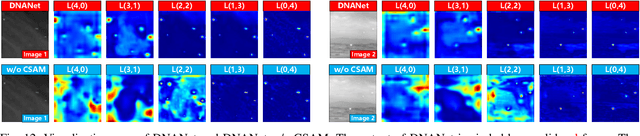
Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds. With the advances of deep learning, CNN-based methods have yielded promising results in generic object detection due to their powerful modeling capability. However, existing CNN-based methods cannot be directly applied for infrared small targets since pooling layers in their networks could lead to the loss of targets in deep layers. To handle this problem, we propose a dense nested attention network (DNANet) in this paper. Specifically, we design a dense nested interactive module (DNIM) to achieve progressive interaction among high-level and low-level features. With the repeated interaction in DNIM, infrared small targets in deep layers can be maintained. Based on DNIM, we further propose a cascaded channel and spatial attention module (CSAM) to adaptively enhance multi-level features. With our DNANet, contextual information of small targets can be well incorporated and fully exploited by repeated fusion and enhancement. Moreover, we develop an infrared small target dataset (namely, NUDT-SIRST) and propose a set of evaluation metrics to conduct comprehensive performance evaluation. Experiments on both public and our self-developed datasets demonstrate the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of probability of detection (Pd), false-alarm rate (Fa), and intersection of union (IoU).
Parallax Attention for Unsupervised Stereo Correspondence Learning
Sep 16, 2020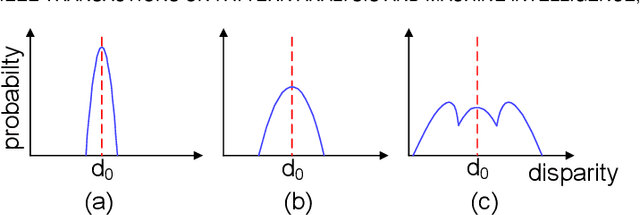
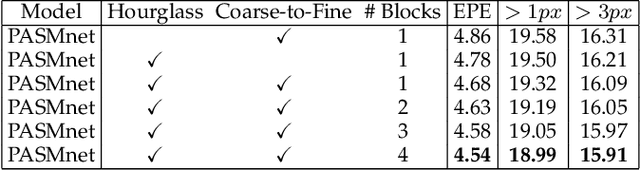
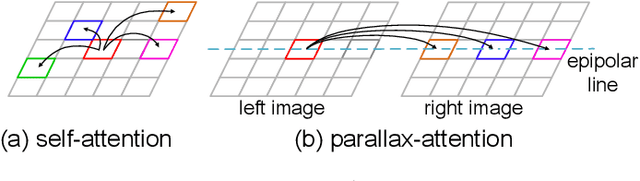

Stereo image pairs encode 3D scene cues into stereo correspondences between the left and right images. To exploit 3D cues within stereo images, recent CNN based methods commonly use cost volume techniques to capture stereo correspondence over large disparities. However, since disparities can vary significantly for stereo cameras with different baselines, focal lengths and resolutions, the fixed maximum disparity used in cost volume techniques hinders them to handle different stereo image pairs with large disparity variations. In this paper, we propose a generic parallax-attention mechanism (PAM) to capture stereo correspondence regardless of disparity variations. Our PAM integrates epipolar constraints with attention mechanism to calculate feature similarities along the epipolar line to capture stereo correspondence. Based on our PAM, we propose a parallax-attention stereo matching network (PASMnet) and a parallax-attention stereo image super-resolution network (PASSRnet) for stereo matching and stereo image super-resolution tasks. Moreover, we introduce a new and large-scale dataset named Flickr1024 for stereo image super-resolution. Experimental results show that our PAM is generic and can effectively learn stereo correspondence under large disparity variations in an unsupervised manner. Comparative results show that our PASMnet and PASSRnet achieve the state-of-the-art performance.
Learning Sparse Masks for Efficient Image Super-Resolution
Jun 17, 2020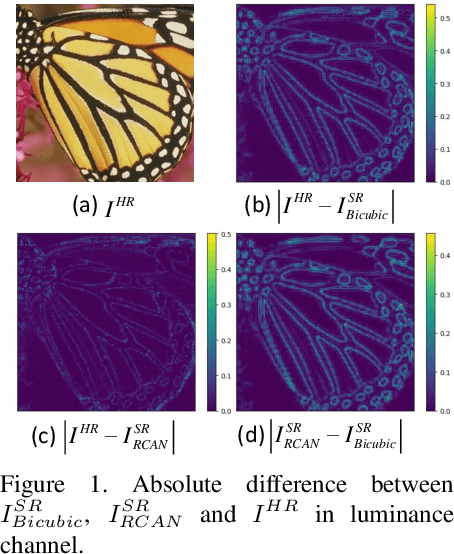
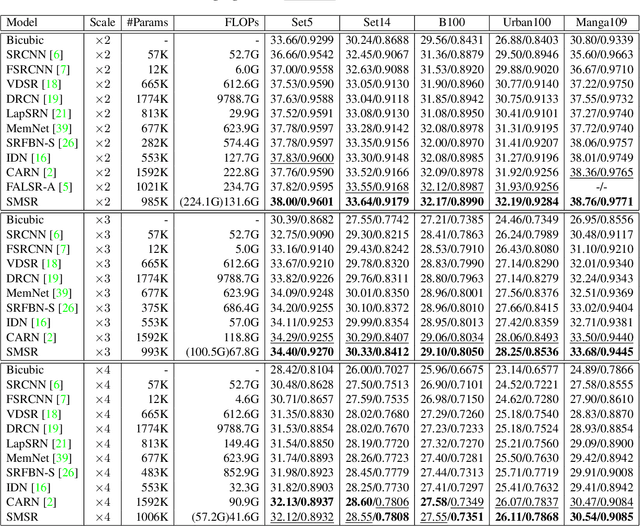
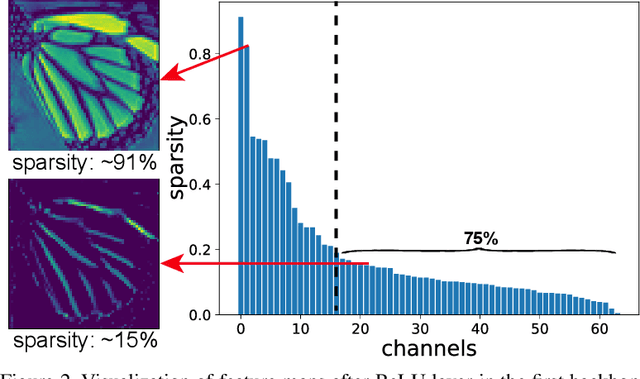

Current CNN-based super-resolution (SR) methods process all locations equally with computational resources being uniformly assigned in space. However, since highfrequency details mainly lie around edges and textures, less computational resources are required for those flat regions. Therefore, existing CNN-based methods involve much redundant computation in flat regions, which increases their computational cost and limits the applications on mobile devices. To address this limitation, we develop an SR network (SMSR) to learn sparse masks to prune redundant computation conditioned on the input image. Within our SMSR, spatial masks learn to identify "important" locations while channel masks learn to mark redundant channels in those "unimportant" regions. Consequently, redundant computation can be accurately located and skipped while maintaining comparable performance. It is demonstrated that our SMSR achieves state-of-the-art performance with 41%/33%/27% FLOPs being reduced for x2/3/4 SR.