 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransText: Alpha-as-RGB Representation for Transparent Text Animation
Mar 19, 2026We introduce the first method, to the best of our knowledge, for adapting image-to-video models to layer-aware text (glyph) animation, a capability critical for practical dynamic visual design. Existing approaches predominantly handle the transparency-encoding (alpha channel) as an extra latent dimension appended to the RGB space, necessitating the reconstruction of the underlying RGB-centric variational autoencoder (VAE). However, given the scarcity of high-quality transparent glyph data, retraining the VAE is computationally expensive and may erode the robust semantic priors learned from massive RGB corpora, potentially leading to latent pattern mixing. To mitigate these limitations, we propose TransText, a framework based on a novel Alpha-as-RGB paradigm to jointly model appearance and transparency without modifying the pre-trained generative manifold. TransText embeds the alpha channel as an RGB-compatible visual signal through latent spatial concatenation, explicitly ensuring strict cross-modal (RGB-and-Alpha) consistency while preventing feature entanglement. Our experiments demonstrate that TransText significantly outperforms baselines, generating coherent, high-fidelity transparent animations with diverse, fine-grained effects.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
ConText: Driving In-context Learning for Text Removal and Segmentation
Jun 04, 2025This paper presents the first study on adapting the visual in-context learning (V-ICL) paradigm to optical character recognition tasks, specifically focusing on text removal and segmentation. Most existing V-ICL generalists employ a reasoning-as-reconstruction approach: they turn to using a straightforward image-label compositor as the prompt and query input, and then masking the query label to generate the desired output. This direct prompt confines the model to a challenging single-step reasoning process. To address this, we propose a task-chaining compositor in the form of image-removal-segmentation, providing an enhanced prompt that elicits reasoning with enriched intermediates. Additionally, we introduce context-aware aggregation, integrating the chained prompt pattern into the latent query representation, thereby strengthening the model's in-context reasoning. We also consider the issue of visual heterogeneity, which complicates the selection of homogeneous demonstrations in text recognition. Accordingly, this is effectively addressed through a simple self-prompting strategy, preventing the model's in-context learnability from devolving into specialist-like, context-free inference. Collectively, these insights culminate in our ConText model, which achieves new state-of-the-art across both in- and out-of-domain benchmarks. The code is available at https://github.com/Ferenas/ConText.
Image Segmentation in Foundation Model Era: A Survey
Aug 23, 2024


Image segmentation is a long-standing challenge in computer vision, studied continuously over several decades, as evidenced by seminal algorithms such as N-Cut, FCN, and MaskFormer. With the advent of foundation models (FMs), contemporary segmentation methodologies have embarked on a new epoch by either adapting FMs (e.g., CLIP, Stable Diffusion, DINO) for image segmentation or developing dedicated segmentation foundation models (e.g., SAM). These approaches not only deliver superior segmentation performance, but also herald newfound segmentation capabilities previously unseen in deep learning context. However, current research in image segmentation lacks a detailed analysis of distinct characteristics, challenges, and solutions associated with these advancements. This survey seeks to fill this gap by providing a thorough review of cutting-edge research centered around FM-driven image segmentation. We investigate two basic lines of research -- generic image segmentation (i.e., semantic segmentation, instance segmentation, panoptic segmentation), and promptable image segmentation (i.e., interactive segmentation, referring segmentation, few-shot segmentation) -- by delineating their respective task settings, background concepts, and key challenges. Furthermore, we provide insights into the emergence of segmentation knowledge from FMs like CLIP, Stable Diffusion, and DINO. An exhaustive overview of over 300 segmentation approaches is provided to encapsulate the breadth of current research efforts. Subsequently, we engage in a discussion of open issues and potential avenues for future research. We envisage that this fresh, comprehensive, and systematic survey catalyzes the evolution of advanced image segmentation systems.
Audio-Visual Segmentation via Unlabeled Frame Exploitation
Mar 17, 2024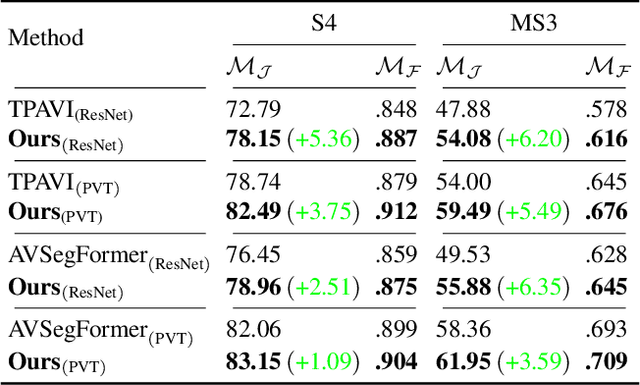
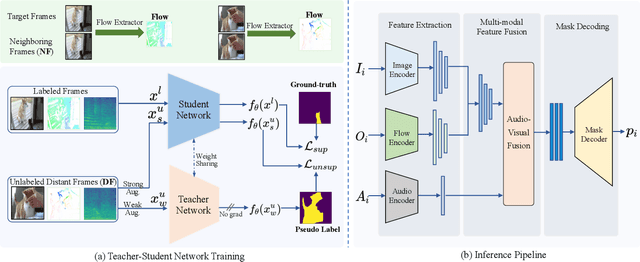
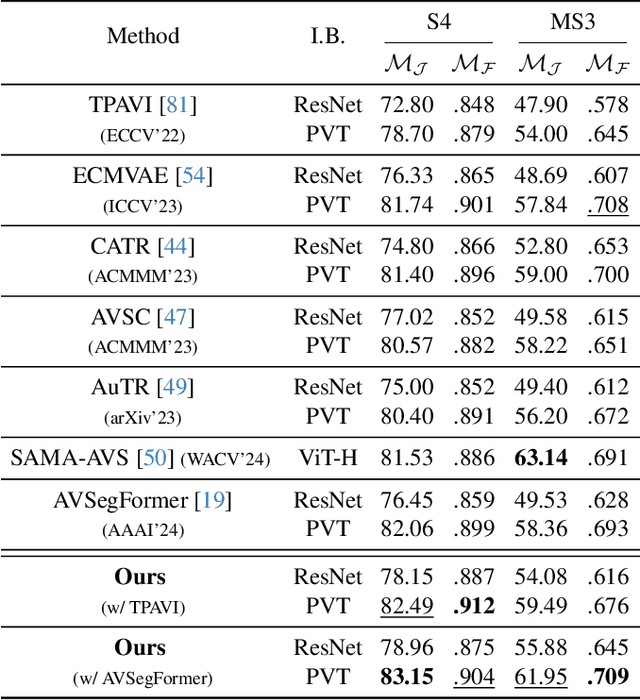
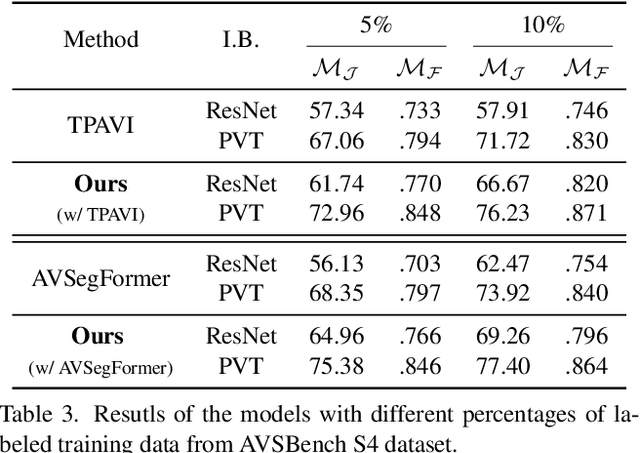
Audio-visual segmentation (AVS) aims to segment the sounding objects in video frames. Although great progress has been witnessed, we experimentally reveal that current methods reach marginal performance gain within the use of the unlabeled frames, leading to the underutilization issue. To fully explore the potential of the unlabeled frames for AVS, we explicitly divide them into two categories based on their temporal characteristics, i.e., neighboring frame (NF) and distant frame (DF). NFs, temporally adjacent to the labeled frame, often contain rich motion information that assists in the accurate localization of sounding objects. Contrary to NFs, DFs have long temporal distances from the labeled frame, which share semantic-similar objects with appearance variations. Considering their unique characteristics, we propose a versatile framework that effectively leverages them to tackle AVS. Specifically, for NFs, we exploit the motion cues as the dynamic guidance to improve the objectness localization. Besides, we exploit the semantic cues in DFs by treating them as valid augmentations to the labeled frames, which are then used to enrich data diversity in a self-training manner. Extensive experimental results demonstrate the versatility and superiority of our method, unleashing the power of the abundant unlabeled frames.
Uncovering Prototypical Knowledge for Weakly Open-Vocabulary Semantic Segmentation
Oct 29, 2023



This paper studies the problem of weakly open-vocabulary semantic segmentation (WOVSS), which learns to segment objects of arbitrary classes using mere image-text pairs. Existing works turn to enhance the vanilla vision transformer by introducing explicit grouping recognition, i.e., employing several group tokens/centroids to cluster the image tokens and perform the group-text alignment. Nevertheless, these methods suffer from a granularity inconsistency regarding the usage of group tokens, which are aligned in the all-to-one v.s. one-to-one manners during the training and inference phases, respectively. We argue that this discrepancy arises from the lack of elaborate supervision for each group token. To bridge this granularity gap, this paper explores explicit supervision for the group tokens from the prototypical knowledge. To this end, this paper proposes the non-learnable prototypical regularization (NPR) where non-learnable prototypes are estimated from source features to serve as supervision and enable contrastive matching of the group tokens. This regularization encourages the group tokens to segment objects with less redundancy and capture more comprehensive semantic regions, leading to increased compactness and richness. Based on NPR, we propose the prototypical guidance segmentation network (PGSeg) that incorporates multi-modal regularization by leveraging prototypical sources from both images and texts at different levels, progressively enhancing the segmentation capability with diverse prototypical patterns. Experimental results show that our proposed method achieves state-of-the-art performance on several benchmark datasets. The source code is available at https://github.com/Ferenas/PGSeg.
First realization of macroscopic Fourier ptychography for hundred-meter distance sub-diffraction imaging
Oct 23, 2023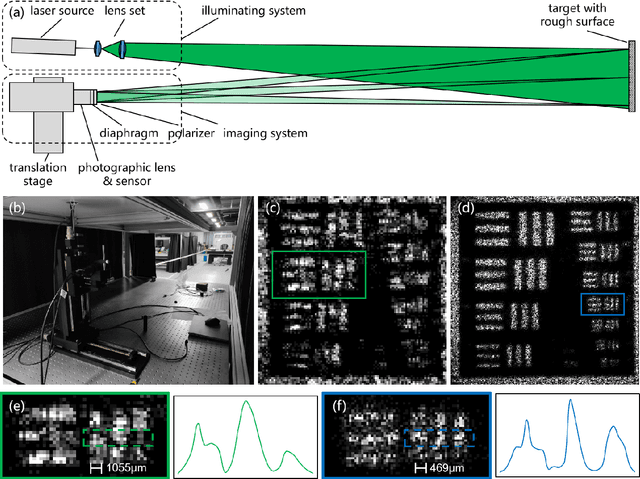
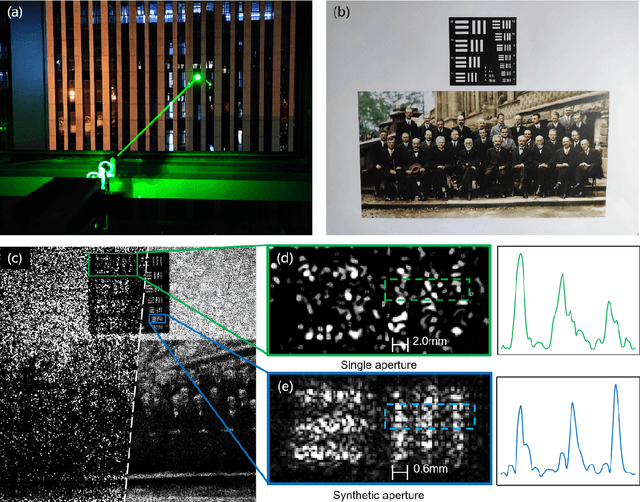
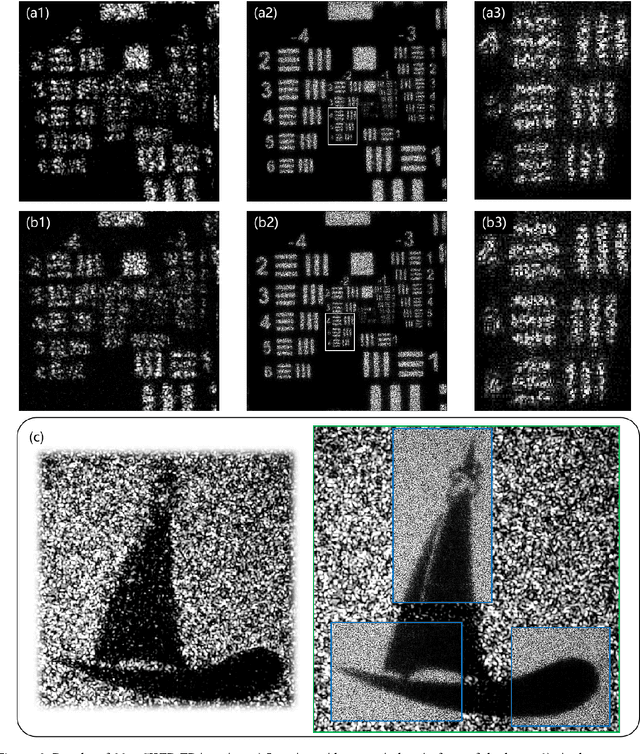

Fourier ptychography (FP) imaging, drawing on the idea of synthetic aperture, has been demonstrated as a potential approach for remote sub-diffraction-limited imaging. Nevertheless, the farthest imaging distance is still limited around 10 m even though there has been a significant improvement in macroscopic FP. The most severely issue in increasing the imaging distance is FoV limitation caused by far-field condition for diffraction. Here, we propose to modify the Fourier far-field condition for rough reflective objects, aiming to overcome the small FoV limitation by using a divergent beam to illuminate objects. A joint optimization of pupil function and target image is utilized to attain the aberration-free image while estimating the pupil function simultaneously. Benefiting from the optimized reconstruction algorithm which effectively expands the camera's effective aperture, we experimentally implement several FP systems suited for imaging distance of 12 m, 90 m, and 170 m with the maximum synthetic aperture of 200 mm. The maximum imaging distance and synthetic aperture are thus improved by more than one order of magnitude of the state-of-the-art works with a fourfold improvement in the resolution. Our findings demonstrate significant potential for advancing the field of macroscopic FP, propelling it into a new stage of development.
Open-Vocabulary Semantic Segmentation via Attribute Decomposition-Aggregation
Aug 31, 2023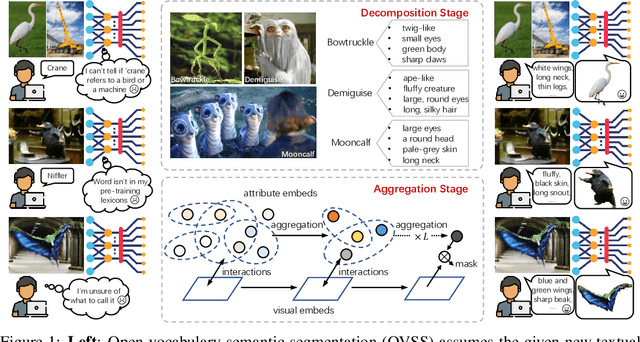


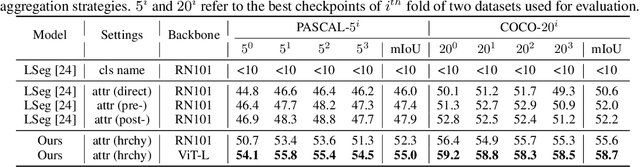
Open-vocabulary semantic segmentation is a challenging task that requires segmenting novel object categories at inference time. Recent works explore vision-language pre-training to handle this task, but suffer from unrealistic assumptions in practical scenarios, i.e., low-quality textual category names. For example, this paradigm assumes that new textual categories will be accurately and completely provided, and exist in lexicons during pre-training. However, exceptions often happen when meet with ambiguity for brief or incomplete names, new words that are not present in the pre-trained lexicons, and difficult-to-describe categories for users. To address these issues, this work proposes a novel decomposition-aggregation framework, inspired by human cognition in understanding new concepts. Specifically, in the decomposition stage, we decouple class names into diverse attribute descriptions to enrich semantic contexts. Two attribute construction strategies are designed: using large language models for common categories, and involving manually labelling for human-invented categories. In the aggregation stage, we group diverse attributes into an integrated global description, to form a discriminative classifier that distinguishes the target object from others. One hierarchical aggregation is further designed to achieve multi-level alignment and deep fusion between vision and text. The final result is obtained by computing the embedding similarity between aggregated attributes and images. To evaluate the effectiveness, we annotate three datasets with attribute descriptions, and conduct extensive experiments and ablation studies. The results show the superior performance of attribute decomposition-aggregation.
Exploiting Counter-Examples for Active Learning with Partial labels
Jul 14, 2023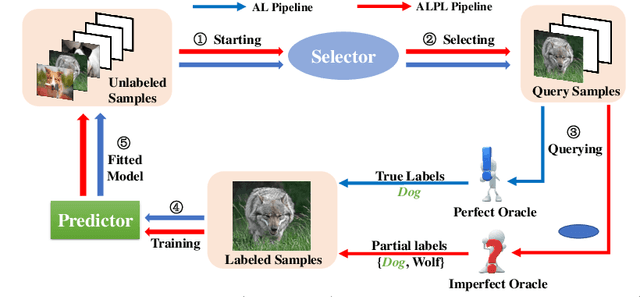
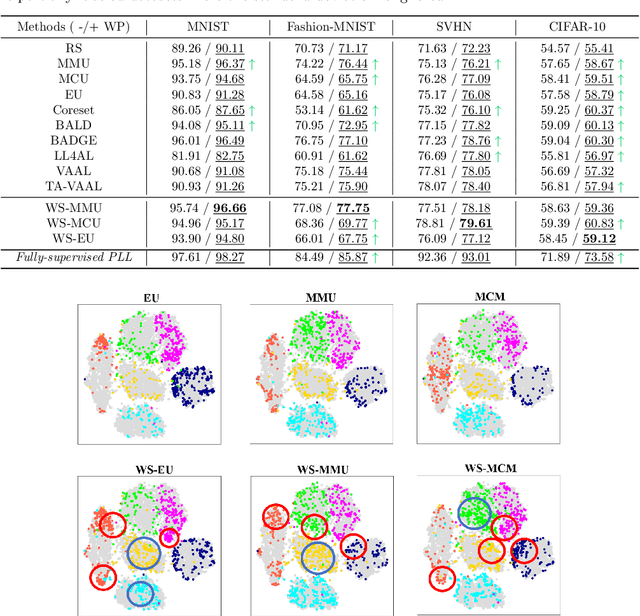
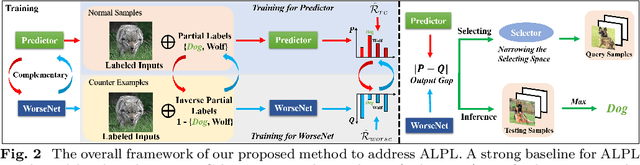
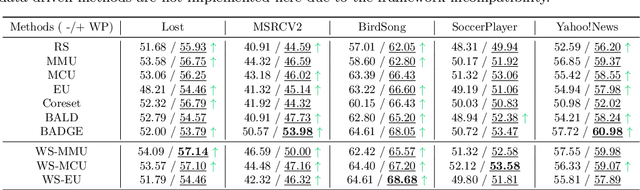
This paper studies a new problem, \emph{active learning with partial labels} (ALPL). In this setting, an oracle annotates the query samples with partial labels, relaxing the oracle from the demanding accurate labeling process. To address ALPL, we first build an intuitive baseline that can be seamlessly incorporated into existing AL frameworks. Though effective, this baseline is still susceptible to the \emph{overfitting}, and falls short of the representative partial-label-based samples during the query process. Drawing inspiration from human inference in cognitive science, where accurate inferences can be explicitly derived from \emph{counter-examples} (CEs), our objective is to leverage this human-like learning pattern to tackle the \emph{overfitting} while enhancing the process of selecting representative samples in ALPL. Specifically, we construct CEs by reversing the partial labels for each instance, and then we propose a simple but effective WorseNet to directly learn from this complementary pattern. By leveraging the distribution gap between WorseNet and the predictor, this adversarial evaluation manner could enhance both the performance of the predictor itself and the sample selection process, allowing the predictor to capture more accurate patterns in the data. Experimental results on five real-world datasets and four benchmark datasets show that our proposed method achieves comprehensive improvements over ten representative AL frameworks, highlighting the superiority of WorseNet. The source code will be available at \url{https://github.com/Ferenas/APLL}.
Prediction of Post-Operative Renal and Pulmonary Complications Using Transformers
Jun 06, 2023Postoperative complications pose a significant challenge in the healthcare industry, resulting in elevated healthcare expenses and prolonged hospital stays, and in rare instances, patient mortality. To improve patient outcomes and reduce healthcare costs, healthcare providers rely on various perioperative risk scores to guide clinical decisions and prioritize care. In recent years, machine learning techniques have shown promise in predicting postoperative complications and fatality, with deep learning models achieving remarkable success in healthcare applications. However, research on the application of deep learning models to intra-operative anesthesia management data is limited. In this paper, we evaluate the performance of transformer-based models in predicting postoperative acute renal failure, postoperative pulmonary complications, and postoperative in-hospital mortality. We compare our method's performance with state-of-the-art tabular data prediction models, including gradient boosting trees and sequential attention models, on a clinical dataset. Our results demonstrate that transformer-based models can achieve superior performance in predicting postoperative complications and outperform traditional machine learning models. This work highlights the potential of deep learning techniques, specifically transformer-based models, in revolutionizing the healthcare industry's approach to postoperative care.