 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency Follows Global-Local Decoupling
Mar 20, 2026Modern vision models must capture image-level context without sacrificing local detail while remaining computationally affordable. We revisit this tradeoff and advance a simple principle: decouple the roles of global reasoning and local representation. To operationalize this principle, we introduce ConvNeur, a two-branch architecture in which a lightweight neural memory branch aggregates global context on a compact set of tokens, and a locality-preserving branch extracts fine structure. A learned gate lets global cues modulate local features without entangling their objectives. This separation yields subquadratic scaling with image size, retains inductive priors associated with local processing, and reduces overhead relative to fully global attention. On standard classification, detection, and segmentation benchmarks, ConvNeur matches or surpasses comparable alternatives at similar or lower compute and offers favorable accuracy versus latency trade-offs at similar budgets. These results support the view that efficiency follows global-local decoupling.
Towards Remote Sensing Change Detection with Neural Memory
Feb 11, 2026Remote sensing change detection is essential for environmental monitoring, urban planning, and related applications. However, current methods often struggle to capture long-range dependencies while maintaining computational efficiency. Although Transformers can effectively model global context, their quadratic complexity poses scalability challenges, and existing linear attention approaches frequently fail to capture intricate spatiotemporal relationships. Drawing inspiration from the recent success of Titans in language tasks, we present ChangeTitans, the Titans-based framework for remote sensing change detection. Specifically, we propose VTitans, the first Titans-based vision backbone that integrates neural memory with segmented local attention, thereby capturing long-range dependencies while mitigating computational overhead. Next, we present a hierarchical VTitans-Adapter to refine multi-scale features across different network layers. Finally, we introduce TS-CBAM, a two-stream fusion module leveraging cross-temporal attention to suppress pseudo-changes and enhance detection accuracy. Experimental evaluations on four benchmark datasets (LEVIR-CD, WHU-CD, LEVIR-CD+, and SYSU-CD) demonstrate that ChangeTitans achieves state-of-the-art results, attaining \textbf{84.36\%} IoU and \textbf{91.52\%} F1-score on LEVIR-CD, while remaining computationally competitive.
AbductiveMLLM: Boosting Visual Abductive Reasoning Within MLLMs
Jan 06, 2026Visual abductive reasoning (VAR) is a challenging task that requires AI systems to infer the most likely explanation for incomplete visual observations. While recent MLLMs develop strong general-purpose multimodal reasoning capabilities, they fall short in abductive inference, as compared to human beings. To bridge this gap, we draw inspiration from the interplay between verbal and pictorial abduction in human cognition, and propose to strengthen abduction of MLLMs by mimicking such dual-mode behavior. Concretely, we introduce AbductiveMLLM comprising of two synergistic components: REASONER and IMAGINER. The REASONER operates in the verbal domain. It first explores a broad space of possible explanations using a blind LLM and then prunes visually incongruent hypotheses based on cross-modal causal alignment. The remaining hypotheses are introduced into the MLLM as targeted priors, steering its reasoning toward causally coherent explanations. The IMAGINER, on the other hand, further guides MLLMs by emulating human-like pictorial thinking. It conditions a text-to-image diffusion model on both the input video and the REASONER's output embeddings to "imagine" plausible visual scenes that correspond to verbal explanation, thereby enriching MLLMs' contextual grounding. The two components are trained jointly in an end-to-end manner. Experiments on standard VAR benchmarks show that AbductiveMLLM achieves state-of-the-art performance, consistently outperforming traditional solutions and advanced MLLMs.
VideoRFT: Incentivizing Video Reasoning Capability in MLLMs via Reinforced Fine-Tuning
May 18, 2025Reinforcement fine-tuning (RFT) has shown great promise in achieving humanlevel reasoning capabilities of Large Language Models (LLMs), and has recently been extended to MLLMs. Nevertheless, reasoning about videos, which is a fundamental aspect of human intelligence, remains a persistent challenge due to the complex logic, temporal and causal structures inherent in video data. To fill this gap, we propose VIDEORFT, a novel approach that extends the RFT paradigm to cultivate human-like video reasoning capabilities in MLLMs. VIDEORFT follows the standard two-stage scheme in RFT: supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations, followed by reinforcement learning (RL) to improve generalization. A central challenge to achieve this in the video domain lies in the scarcity of large-scale, high-quality video CoT datasets. We address this by building a fully automatic CoT curation pipeline. First, we devise a cognitioninspired prompting strategy to elicit a reasoning LLM to generate preliminary CoTs based solely on rich, structured, and literal representations of video content. Subsequently, these CoTs are revised by a visual-language model conditioned on the actual video, ensuring visual consistency and reducing visual hallucinations. This pipeline results in two new datasets - VideoRFT-CoT-102K for SFT and VideoRFT-RL-310K for RL. To further strength the RL phase, we introduce a novel semantic-consistency reward that explicitly promotes the alignment between textual reasoning with visual evidence. This reward encourages the model to produce coherent, context-aware reasoning outputs grounded in visual input. Extensive experiments show that VIDEORFT achieves state-of-the-art performance on six video reasoning benchmarks.
Prompt-Driven Continual Graph Learning
Feb 10, 2025



Continual Graph Learning (CGL), which aims to accommodate new tasks over evolving graph data without forgetting prior knowledge, is garnering significant research interest. Mainstream solutions adopt the memory replay-based idea, ie, caching representative data from earlier tasks for retraining the graph model. However, this strategy struggles with scalability issues for constantly evolving graphs and raises concerns regarding data privacy. Inspired by recent advancements in the prompt-based learning paradigm, this paper introduces a novel prompt-driven continual graph learning (PROMPTCGL) framework, which learns a separate prompt for each incoming task and maintains the underlying graph neural network model fixed. In this way, PROMPTCGL naturally avoids catastrophic forgetting of knowledge from previous tasks. More specifically, we propose hierarchical prompting to instruct the model from both feature- and topology-level to fully address the variability of task graphs in dynamic continual learning. Additionally, we develop a personalized prompt generator to generate tailored prompts for each graph node while minimizing the number of prompts needed, leading to constant memory consumption regardless of the graph scale. Extensive experiments on four benchmarks show that PROMPTCGL achieves superior performance against existing CGL approaches while significantly reducing memory consumption. Our code is available at https://github.com/QiWang98/PromptCGL.
On-Road Object Importance Estimation: A New Dataset and A Model with Multi-Fold Top-Down Guidance
Nov 26, 2024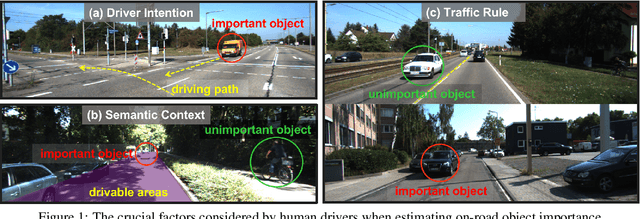

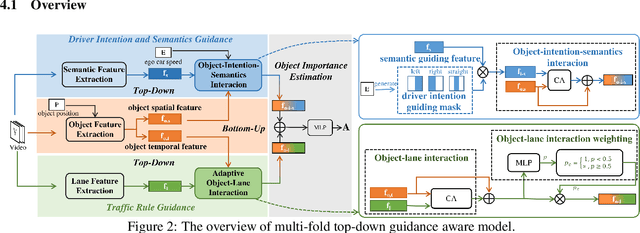
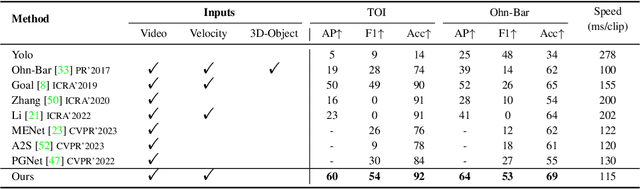
This paper addresses the problem of on-road object importance estimation, which utilizes video sequences captured from the driver's perspective as the input. Although this problem is significant for safer and smarter driving systems, the exploration of this problem remains limited. On one hand, publicly-available large-scale datasets are scarce in the community. To address this dilemma, this paper contributes a new large-scale dataset named Traffic Object Importance (TOI). On the other hand, existing methods often only consider either bottom-up feature or single-fold guidance, leading to limitations in handling highly dynamic and diverse traffic scenarios. Different from existing methods, this paper proposes a model that integrates multi-fold top-down guidance with the bottom-up feature. Specifically, three kinds of top-down guidance factors (ie, driver intention, semantic context, and traffic rule) are integrated into our model. These factors are important for object importance estimation, but none of the existing methods simultaneously consider them. To our knowledge, this paper proposes the first on-road object importance estimation model that fuses multi-fold top-down guidance factors with bottom-up feature. Extensive experiments demonstrate that our model outperforms state-of-the-art methods by large margins, achieving 23.1% Average Precision (AP) improvement compared with the recently proposed model (ie, Goal).
Image Segmentation in Foundation Model Era: A Survey
Aug 23, 2024


Image segmentation is a long-standing challenge in computer vision, studied continuously over several decades, as evidenced by seminal algorithms such as N-Cut, FCN, and MaskFormer. With the advent of foundation models (FMs), contemporary segmentation methodologies have embarked on a new epoch by either adapting FMs (e.g., CLIP, Stable Diffusion, DINO) for image segmentation or developing dedicated segmentation foundation models (e.g., SAM). These approaches not only deliver superior segmentation performance, but also herald newfound segmentation capabilities previously unseen in deep learning context. However, current research in image segmentation lacks a detailed analysis of distinct characteristics, challenges, and solutions associated with these advancements. This survey seeks to fill this gap by providing a thorough review of cutting-edge research centered around FM-driven image segmentation. We investigate two basic lines of research -- generic image segmentation (i.e., semantic segmentation, instance segmentation, panoptic segmentation), and promptable image segmentation (i.e., interactive segmentation, referring segmentation, few-shot segmentation) -- by delineating their respective task settings, background concepts, and key challenges. Furthermore, we provide insights into the emergence of segmentation knowledge from FMs like CLIP, Stable Diffusion, and DINO. An exhaustive overview of over 300 segmentation approaches is provided to encapsulate the breadth of current research efforts. Subsequently, we engage in a discussion of open issues and potential avenues for future research. We envisage that this fresh, comprehensive, and systematic survey catalyzes the evolution of advanced image segmentation systems.
Nonverbal Interaction Detection
Jul 11, 2024



This work addresses a new challenge of understanding human nonverbal interaction in social contexts. Nonverbal signals pervade virtually every communicative act. Our gestures, facial expressions, postures, gaze, even physical appearance all convey messages, without anything being said. Despite their critical role in social life, nonverbal signals receive very limited attention as compared to the linguistic counterparts, and existing solutions typically examine nonverbal cues in isolation. Our study marks the first systematic effort to enhance the interpretation of multifaceted nonverbal signals. First, we contribute a novel large-scale dataset, called NVI, which is meticulously annotated to include bounding boxes for humans and corresponding social groups, along with 22 atomic-level nonverbal behaviors under five broad interaction types. Second, we establish a new task NVI-DET for nonverbal interaction detection, which is formalized as identifying triplets in the form <individual, group, interaction> from images. Third, we propose a nonverbal interaction detection hypergraph (NVI-DEHR), a new approach that explicitly models high-order nonverbal interactions using hypergraphs. Central to the model is a dual multi-scale hypergraph that adeptly addresses individual-to-individual and group-to-group correlations across varying scales, facilitating interactional feature learning and eventually improving interaction prediction. Extensive experiments on NVI show that NVI-DEHR improves various baselines significantly in NVI-DET. It also exhibits leading performance on HOI-DET, confirming its versatility in supporting related tasks and strong generalization ability. We hope that our study will offer the community new avenues to explore nonverbal signals in more depth.
LFMamba: Light Field Image Super-Resolution with State Space Model
Jun 18, 2024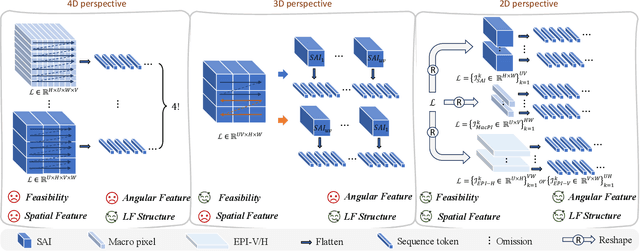
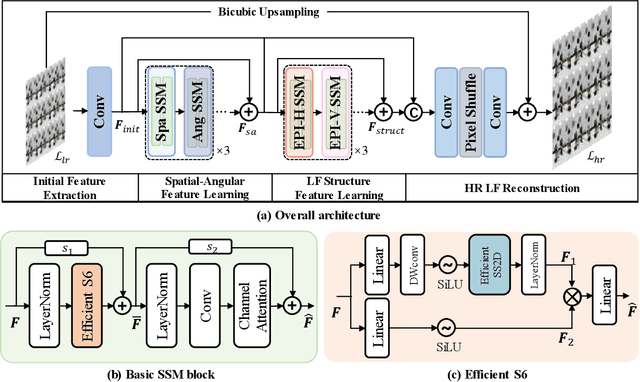
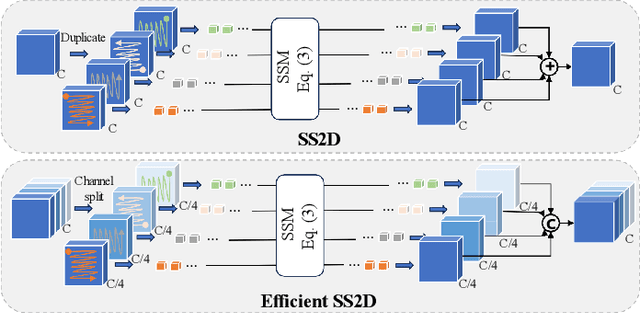

Recent years have witnessed significant advancements in light field image super-resolution (LFSR) owing to the progress of modern neural networks. However, these methods often face challenges in capturing long-range dependencies (CNN-based) or encounter quadratic computational complexities (Transformer-based), which limit their performance. Recently, the State Space Model (SSM) with selective scanning mechanism (S6), exemplified by Mamba, has emerged as a superior alternative in various vision tasks compared to traditional CNN- and Transformer-based approaches, benefiting from its effective long-range sequence modeling capability and linear-time complexity. Therefore, integrating S6 into LFSR becomes compelling, especially considering the vast data volume of 4D light fields. However, the primary challenge lies in \emph{designing an appropriate scanning method for 4D light fields that effectively models light field features}. To tackle this, we employ SSMs on the informative 2D slices of 4D LFs to fully explore spatial contextual information, complementary angular information, and structure information. To achieve this, we carefully devise a basic SSM block characterized by an efficient SS2D mechanism that facilitates more effective and efficient feature learning on these 2D slices. Based on the above two designs, we further introduce an SSM-based network for LFSR termed LFMamba. Experimental results on LF benchmarks demonstrate the superior performance of LFMamba. Furthermore, extensive ablation studies are conducted to validate the efficacy and generalization ability of our proposed method. We expect that our LFMamba shed light on effective representation learning of LFs with state space models.
Uncovering Prototypical Knowledge for Weakly Open-Vocabulary Semantic Segmentation
Oct 29, 2023



This paper studies the problem of weakly open-vocabulary semantic segmentation (WOVSS), which learns to segment objects of arbitrary classes using mere image-text pairs. Existing works turn to enhance the vanilla vision transformer by introducing explicit grouping recognition, i.e., employing several group tokens/centroids to cluster the image tokens and perform the group-text alignment. Nevertheless, these methods suffer from a granularity inconsistency regarding the usage of group tokens, which are aligned in the all-to-one v.s. one-to-one manners during the training and inference phases, respectively. We argue that this discrepancy arises from the lack of elaborate supervision for each group token. To bridge this granularity gap, this paper explores explicit supervision for the group tokens from the prototypical knowledge. To this end, this paper proposes the non-learnable prototypical regularization (NPR) where non-learnable prototypes are estimated from source features to serve as supervision and enable contrastive matching of the group tokens. This regularization encourages the group tokens to segment objects with less redundancy and capture more comprehensive semantic regions, leading to increased compactness and richness. Based on NPR, we propose the prototypical guidance segmentation network (PGSeg) that incorporates multi-modal regularization by leveraging prototypical sources from both images and texts at different levels, progressively enhancing the segmentation capability with diverse prototypical patterns. Experimental results show that our proposed method achieves state-of-the-art performance on several benchmark datasets. The source code is available at https://github.com/Ferenas/PGSeg.